






今天为了测试一下urllib2模块中的headers部分,也就是模拟客户端登陆的那个东东,就对煎蛋网妹子图练了一下手,感觉还可以吧。分享一下!
代码如下
# coding:UTF-8
import urllib2,urllib,re,random
def getHtml(url) :
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
page = response.read()
return page
def getImageUrls(page):
reg = r'src="(.+?\.jpg)"'
imageReg = re.compile(reg)
img_urls = re.findall(imageReg,page)
return img_urls
# 根据给定的路径,文件名,将指定的数据写入到文件中
def writeToFile(path,name,data):
file = open(path+name,'wb')
file.write(data)
file.close()
print name+" has been Writed Succeed!"
#writeToFile(path,str(name)+".jpg",content)
def downloadImages(images_url) :
for i, item in enumerate(images_url):
everypicture = getHtml(item)
# 此处下载之后的文件使用了item来命名是为了避免图片的覆盖
writeToFile(path, str(i+random.randint(1,100000000)) + ".jpg", everypicture)
# --------------------------------------------------------------------------------------------------
# 下面是我们的测试代码
headers = {
'referer':'http://jandan.net/ooxx/page-1986',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'
}
path = "F:\\pachong\\jiandan\\"
# 注意这里的URL不是全部,按理应该使用url拼接自动完成的,但是我这里是手动修改的
originalurl = 'http://jandan.net/ooxx/page-1986'
page = getHtml(originalurl)
images_url = getImageUrls(page)
downloadImages(images_url)
爬虫结果
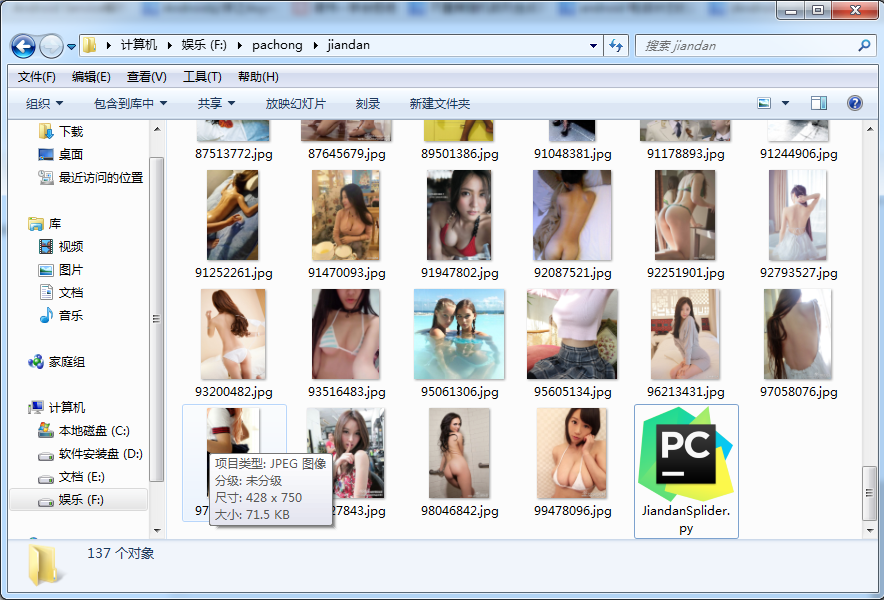
总结
代码不多,核心在于思想。逻辑如下:
- 使用headers绕开网站的验证
- 获得主页面中所有的图片的url
- 根据图片url循环的读取网页内容
- 再循环中就把图片写入到本地
是不是很简单呢,但是这里有不智能的地方,那就是没有把原始的url做处理,如果再用url拼接技术的话,我们就可以实现“只需要一张网址,就可以抓取我们想要的所有的图片了”。
代码中不可避免的存在一些问题,欢迎大家批评指正!















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









