







1. . 匹配
除了 \n 都可以进行匹配
在sublime自己去感受感受,ctrl+f ;设置正则匹配

一直敲回车键就可以查看到匹配的过程。
2.[]的使用
-----借助b站的呜呜记忆(心房)=匹配的内容出现在[]里面就成功,匹配 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ 其中一个即可

3.[^]
-----借助呜呜记忆:通过进入超市的办法进入心房。所以都不需要,eg:不是a-Z的都能匹配(\b是无法匹配的,虽然也不在a-Z中),回车符号可以匹配,空格

4.\w
匹配 能作为变量的字符(数字,字母,下划线)(word),因为中文也能当变量,所以也能匹配到—只能这么记忆咯
js console中 

5. \W
不能构成变量名的字符
在此补充一下
https://www.cnblogs.com/liluxiang/p/9474913.html
\r是回车,英文是Carriage return,作用:使光标到行首
\n是换行,英文是New line/line feed,作用:使光标下移一行
如果用过机械打字机,就知道回车和换行的区别了。
回车就是把水平位置复位,不卷动滚筒。
换行就是把滚筒卷一格,不改变水平位置。
我们平时所说的键盘Enter键换行实则应该叫做叫做回车换行(\r\n)
看到一种说法:
windows下enter是 \r\n;
linux/unix下是\n;
mac下是\r
Windows 采用 \r\n 是有原因的,Windows 采用了传统的英文打字机的模式。
想想看英文打字机是如何换行的呢?英文打字机是选择将小车退回至起点,
这个过程称为回车(carriage return, CR),随后把小车调至下一行的位
置,这个过程称为换行(line feed, LF),这样就完成了英文打字机中换
行过程。
回车(CR)在计算机中使用 ASCII 为 13 的字符来表示(0x0D),换行 (LF)使用
ASCII 为 10 的字符来表示(0x0A)。
注意:
1、windows下可直接使用\n来匹配换行符,但仍然推荐使用标准的\r\n来匹配键盘Enter键的换行符;
2、使用\r\n组合是有顺序的,调转顺序写成\n\r是错误的,将无法匹配换行符!
回车符号(\r\n ),空格,tab,.{[(|*+ \t(tab) \f换页符 等
其实 [ \r \n \t \f ] ==== \s
\s是无法当成变量的
6.\s
\t \f \n \r 第5点已经说明白了,由于在sublime无法 换页符号
\r 这两种。
此时的\s展现的就是\r\n的内容
7.\S
不是 \s的内容都可以匹配,当然 间隔符无法展现

8.\d 数字
data

9.\D
不是数字咯 等价于[^0-9] 还是无法匹配到 间隔符

10.*
呜呜记忆法 0次或多次

11.+
呜呜记忆法 1次或多次
12.?
呜呜记忆法 不是0就是1咯
13 {m,n} 重复m,n次。
当然n可以不指定,就是大于等于m次
连续出现4次以上的 数字 被匹配

14 懒惰匹配 4种情况
* ? 匹配0次及以上,因为是懒惰匹配,所以匹配到0次就放行
+? 匹配1次及以上,因为是懒惰匹配,所以匹配到一次就放行
?? 匹配0次或者一次,因为是懒惰匹配,所以匹配0次就放行
{m,n}? 匹配m到n次,懒惰匹配,所以匹配m次
14-1:*? 匹配0次以上
首先不使用懒惰匹配,所以他会尽可能的匹配多一点。

使用懒惰匹配(也就是在后面加上?)

14-2 +? 匹配1次及以上(懒惰匹配哦)
还是老样子,不加?进行匹配

加上?进行匹配

我就懒一点,匹配到一个数字就返回,然后重新开始匹配
14-3 ?? 匹配0或者1次
不加?,就会匹配一次

加了?-------懒惰,匹配到一个3我就不匹配了

14-4:{m,n}?
不是懒惰匹配,不加?

懒惰匹配{m,n}?

15. ^ 行首
每行的行首都会进行匹配

16 $ 行尾

17.\A 字符串开头
在sublime中,一个文件的开头
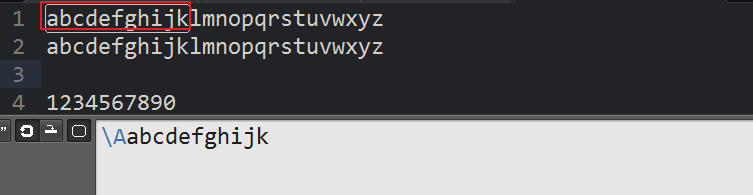
18 \Z 字符串尾巴
在sublime中,一个文件的结尾 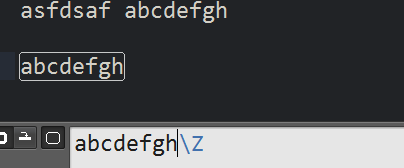
如果想要匹配 \Aabcdefg\Z
则新构建一个文件,只有abcdefg才能匹配

19 \b 单词边界
由于subline,无法显示匹配结果,于是手动的添加了边界

那我是怎么知道就是这些地方匹配到了呢?
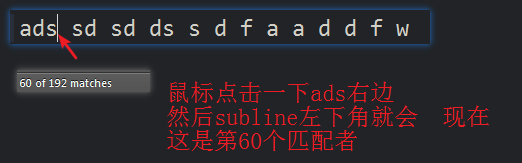
点击其他的地方:
20 \B 不是词头,
词尾就能匹配(也是一个边界)
不是\b的就是咯(\n\t 也会匹配到)
验证\B能匹配制表符
首先匹配 \t能匹配到第5行的两个制表符
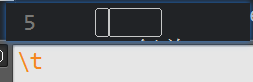
然后匹配\B

也能说的通,空格 ,制表符 ,换行符都不是 单词的词头词尾。所以能匹配到
21 ()
有向后引用的作用,后面使用前面的内容
为什么要有这个语法呢?
匹配日期吧?
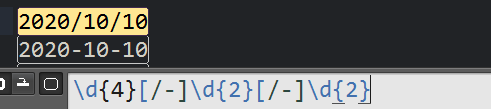
使用这个也能匹配成功,但是也会匹配到这些不合规则的日期
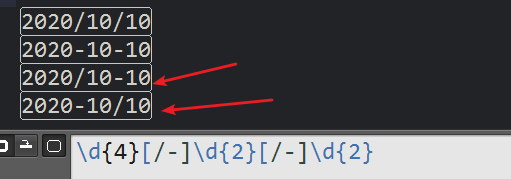
所以使用向后引用,让后面的与前面显示内容一样

另外两个不合规则的日期就会过滤掉
22 \1,\2
23 设定规则

乍一看,看不懂,说的什么东西,不过从博客中看到了一句话
以 (?) 开头的组是纯的非捕获 组,它不捕获文本 ,也不针对组合计进行计数。就是说,
如果小括号中以?号开头,那么这个分组就不会捕获文本,
当然也不会有组的编号,因此 也不存在向后 引用。
23.1 : (?=X) 人话解释一下
(?=x)必须放在右边,进行判断左边是否合规则
eg:
匹配w,但是w的右边一定是55
w+(?=55)

23.2 : (?!X)
这个也是放在右边来判断左边匹配的内容是否符合右边的规则呢?
我想匹配w,但是 w 的右边不是1024

23.3
通过在匹配的内容的右边设定规则,过滤已经匹配到的。当然我们也可以在匹配的内容的左边设定规则,判断匹配的内容是否符合左边的规则
使用
(?<=X)
eg: 匹配 99,但是99的左边一定是23
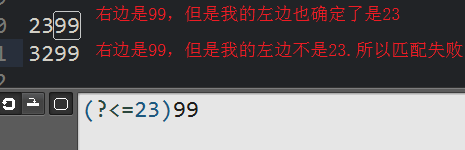
23.4 : (?<!X)
匹配 99,但是99的左侧不是23
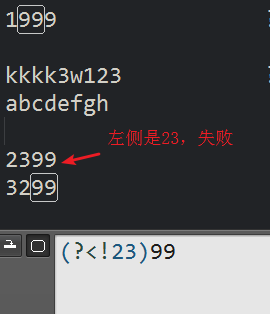
23总一下
我想规定一下我匹配的内容,我匹配的内容左边要满足什么条件
或者右边需要满足什么条件。这样我匹配的内容才是正确的,否则失败
1。规定右边需要满足什么条件
已经匹配的内容(?=X)
如果右边是X,则匹配的内容成功
已经匹配的内容(?!X)
如果右边不是X,则匹配的内容成功
2.规定左边需要满足什么条件
(?<=X) 已经匹配的内容
如果左侧是X,则已经匹配的内容成功
(?<!)X已经匹配的内容
如果左侧不是X,则已经匹配的内容成功
符号记忆:
*一般都是从左往右进行匹配,所以一般会先匹配到左边的内容
所以我们通过这两个 规定 已经匹配的内容(左边) 是否符合规则
(? =X) (? !X)
*开发员又想规定 右边的内容是否合法,所以只能在左侧定义规则
为了区分 使用< 代表左侧
(? < =X) (? < !X) ,将<往上面插入就可以了。
上面的内容是通过这张图展现出来的。

eg:
最后一个字符是,的情况

或者 ,$

https://blog.csdn.net/chenlei0630/article/details/19036819
区别 \A \Z 和 ^ $的请借鉴:
https://zhidao.baidu.com/question/1386685065581558500.html
先使用这个视频,简单的记忆一下。挺不错的哦----呜呜记忆法
https://www.bilibili.com/video/av82911240?from=search&seid=6436916534512915174
然后看看老外的视频教程
https://www.bilibili.com/video/av66949177?t=2266
使用sublime也可实现这样的效果。















 4488
4488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









