
模板
Flask 模板是一种用来生成动态网页的技术,它使用 Jinja2 作为模板引擎,可以在 HTML 文件中嵌入 Python 代码和控制语句,实现数据的渲染和逻辑的处理。Flask 模板还支持过滤器、宏、继承、包含等高级功能,提高了代码的复用性和可维护性。
以下是一篇 Flask 模板的学习笔记,希望对你有用:
- 在 Flask 中,可以使用 `render_template()` 函数来渲染模板文件,该函数接受模板文件名和一些关键字参数作为输入,返回一个字符串作为响应。
- 模板文件默认放在项目根目录下的 `templates` 文件夹中,可以使用相对路径或绝对路径来指定模板文件名。
- 在模板文件中,可以使用 `{
{
... }}` 来插入 Python 表达式的值,例如 `{
{
name }}` 会显示传入的 `name` 参数的值。
- 在模板文件中,可以使用 `{
% ... %}` 来执行 Python 语句,例如 `{
% for item in items %}` 和 `{
% endfor %}` 可以实现循环遍历列表。
- 过滤器是一种对变量值进行转换或格式化的函数,可以在变量名后面加上 `|` 符号和过滤器名来使用,例如 `{
{
name|capitalize }}` 会把 `name` 的首字母大写。
- Flask 支持多种内置过滤器,如 `safe`(禁用自动转义)、`lower`(转换为小写)、`length`(获取长度)等。
- 可以使用多个过滤器进行链式操作,例如 `{
{
name|capitalize|safe }}` 会先把 `name` 的首字母大写再禁用自动转义。
- 可以自定义过滤器,并在 Flask 应用对象上注册,例如:
```python
@app.template_filter("reverse")
def reverse_filter(s):
return s[::-1]
3. Web 表单
Web 表单是一种让用户输入数据并提交给服务器的交互方式,在 HTML 中可以使用 <form> 标签来创建表单,并指定表单提交时的方法(GET 或 POST)和目标 URL。
在表单中可以使用各种类型的 <input> 标签来创建不同的输入控件,如文本框、密码框、复选框、单选框等,并为每个控件设置一个唯一的名称(name 属性)。
在 Flask 中,可以使用 request.form.get() 方法来获取表单提交时用户输入的数据,并根据业务逻辑进行处理或存储。例如:
@app.route("/login", methods=["GET", "POST"])
def login():
if request.method == "POST":
username = request.form.get("username")
password = request.form.get("password")
return render_template("login.html")
4. 控制语句
控制语句是一种改变程序执行流程或逻辑判断的语句,在模板中可以使用 {
% ... %} 来书写控制语句,并且要注意配对结束标签 {
% end... %}。
Jinja2
5. 宏
宏是一种定义可重用的代码块的方式,在模板中可以使用 {
% macro ... %} 和 {
% endmacro %} 来定义一个宏,并给它一个名称和一些参数。
在模板中可以使用 {
{
macro_name(...) }} 来调用一个宏,并传入相应的参数,例如 {
{
render_field(form.username) }} 会调用名为 render_field 的宏,并传入表单对象的 username 字段作为参数。
在模板中可以使用 {
% import ... %} 来导入其他模板文件中定义的宏,例如 {
% import "macros.html" as macros %} 会导入名为 macros.html 的模板文件,并把它命名为 macros,然后可以使用 {
{
macros.render_field(...) }} 来调用其中的宏。
6. 继承
继承是一种让一个模板文件继承另一个模板文件中的内容和结构的方式,在模板中可以使用 {
% extends ... %} 来指定要继承的父模板文件,例如 {
% extends "base.html" %} 会继承名为 base.html 的父模板文件。
在父模板文件中,可以使用 {
% block ... %} 和 {
% endblock %} 来定义一些可被子模板覆盖或修改的区域,并给每个区域一个唯一的名称,例如:
<html>
<head>
<title>{
% block title %}{
% endblock %}</title>
</head>
<body>
<h1>{
% block header %}{
% endblock %}</h1>
<div>{
% block content %}{
% endblock %}</div>
</body>
</html>
在子模板文件中,可以使用相同的名称来覆盖或修改父模板中定义的区域,例如:
{
% extends "base.html" %}
{
% block title %}
Flask 模板示例
{
% endblock %}
{
% block header %}
欢迎来到 Flask 模板示例
{
% endblock %}
{
% block content %}
这里是内容区域
{
% endblock %}
7. 包含
包含是一种在一个模板文件中插入另一个模板文件中的内容的方式,在模板中可以使用 {
% include ... %} 来指定要包含的子模板文件,例如 {
% include "nav.html" %} 会包含名为 nav.html 的子模板文件。
包含和继承不同之处在于,包含不会改变原有的结构和样式,而只是简单地插入另一个文件中的内容。包含适合用于重复出现在多个页面上的部分,如导航栏、页脚等。
Flask-SQLAlchemy

ORM 映射框架
ORM是什么
ORM(Object Relational Mapping),对象关系映射
ORM的重要特性:
面向对象的编程思想,方便扩充
少写(几乎不写)SQL,提升开发效率
支持多种类型的数据库,方便切换
ORM技术成熟,能解决绝大部分问题
pip安装:pip install -U Flask-SQLAlchemy
源码安装:python setup.py install
安装依赖
pip install mysqlclient
安装pymysql依赖包
pip install pymysql
ModuleNotFoundError: No module named 'MySQLdb’错误, 则表示缺少mysql依赖包
mysqlclient 和 pymysql 都是用于mysql访问的依赖包,
前者由C语言实现的, 而后者由python实现, 前者的执行效率比后者更高,
但前者在windows系统中兼容性较差, 工作中建议优先前者。
组件初始化
fask-sqlalchemy配置
相关配置也封装到了 flask 的配置项中, 可以通过app.config属性 或
配置加载方案 (如config.from_object) 进行设置
配置项
SQLALCHEMY DATABASE URI 设置数据库的连接地址
SQLALCHEMY BINDS 访问多个数据库时,用于设置数据库的连接地址
SQLALCHEMY ECHO 是否打印底层执行的SQL语句
SQLALCHEMY RECORD QUERIES 是否记录执行的查询语句,用于慢查询分析,调试模式下自动启动
SQLALCHEMY TRACK MODIFICATIONS 是否追踪数据库变化(触发钩子函数),会消耗额外的内存
SQLALCHEMY ENGINE OPTIONS 设置针对 sqlalchemy 本体的配置项
数据库URI:
(连接地址)格式:
协议名://用户名:密码@数据库IP:端口号/数据库名, 如:
app.config['SQLALCHEMY_DATABASE_URI'] =
'mysql://root:[email protected]:3306/test31'
如果数据库驱动使用的是 pymysql, 则协议名需要修改为
mysql+pymysql://xxxxxxx
SQLALCHEMY_DATABASE_URI
统一资源标识符(Uniform resource Identifier,URI)是一个用于标识某一互联网资源名称的字符串
MySQL数据库URL参数格式
mysql: //scott: tiger@localhost/mydatabase

两种组件初始化方式
方式1
flask-sqlalchemy 支持两种组件初始化方式:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 应用配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 方式1: 初始化组件对象, 直接关联Flask应用
db = SQLAlchemy(app)
方式2: 先创建组件, 延后关联Flass应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 方式2: 初始化组件对象, 延后关联Flask应用
db = SQLAlchemy()
def create_app(config_type):
"""工厂函数"""
# 创建应用
flask_app = Flask(__name__)
# 加载配置
config_class = config_dict[config_type]
flask_app.config.from_object(config_class)
# 关联flask应用
db.init_app(app)
return flask_app
多个数据库支持
SQLALCHEMY_BINDS = {
'db1':'mysqldb://localhost/users',
'db2':'sqlit:path/to/appmeta.db'
}
设计数据库模型并创建表
数据库模型设计:
绑定到Fask对象
db = SQLAlchemy(app)
ORM模型创建
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
指定表名称
__tablename__ = 'weibo_user_addr'
创建和删除表:
手动创建数据库
创建表
db.create_all(bind='db1')
删除表
db.drop_all()
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 配置数据库的连接参数
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]/test_flask'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), nullable=False)
构建数据库模型类:
模型设计
ORM模型字段类型支持
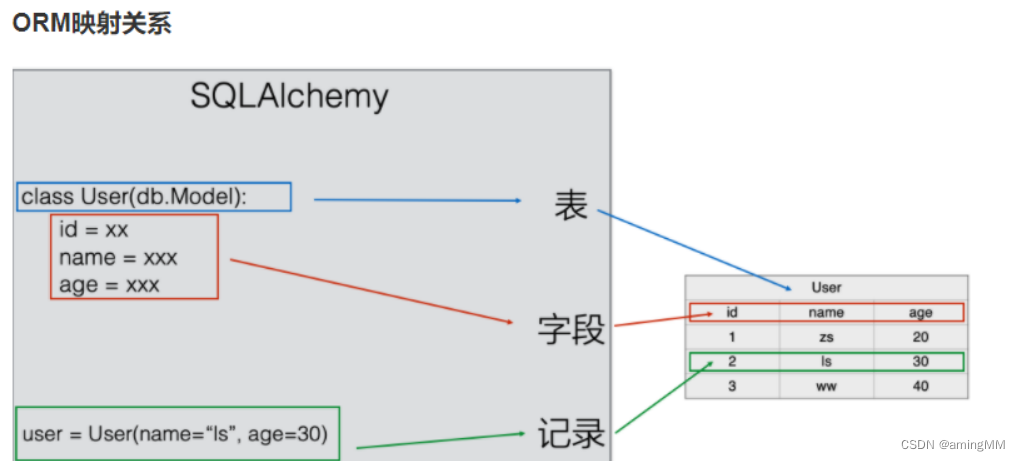
flask-sqlalchemy 的关系映射和 Django-orm 类似
类 对应 表
类属性 对应 字段
实例对象 对应 记录
类型 python接收类型 mysql生成类型 说明
Integer/Float int/float int 整数/浮点类型
String (size) 有长度限制的字符串
Text str text 文本类型,最大64KB
DateTime datetime.datetime datetime datetime对象的 时间和日期
Boolean bool tinyint 存储布尔值 整型,只占1个字节
PickleType 存储为一个持久化的 Python 对象
LargeBinary 存储一个任意大的二进制数据
LongText str longtext 文本类型,最大4GB
String str varchar 变长字符串,必须限定长度
Date datetime.date date 日期
Time datetime.time time 时间
常用的字段选项
选项名
primary_key 如果为True,表示该字段为表的主键,默认自增
unique 如果为True,代表这列设置唯一约束
nullable 如果为False,代表这列设置非空约束
default 为这列设置默认值默认
index 如果为True,为这列创建索引,提高查询效率
注意点: 如果没有给对应字段的类属性设置default参数,
且添加数据时也没有给该字段赋值, 则sqlalchemy会给该字段设置默认值 None
# 构建模型类 类->表 类属性->字段 实例对象->记录
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
if __name__ == '__main__':
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
app.run(debug=True)
注意点
模型类必须继承 db.Model, 其中 db 指对应的组件对象
表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
类属性对应字段, 必须是通过 db.Column() 创建的对象
可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表
一对多关系,外键关联
user_id = db.Column(db.Integer, db.ForeignKey('weibo_user.id'), nullable=False)
一对多关系,外键关联
user = db.relationship('User', backref=db.backref('address', lazy=True))
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 配置数据库的连接参数
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]/test_flask'
db = SQLAlchemy(app)
from sqlalchemy import create_engine
engine = create_engine("sqlite:///testdb.db")
class User(db.Model):
__tablename__ = 'weibo_user'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), nullable=False)
password = db.Column(db.String(256), nullable=False)
birth_date = db.Column(db.Date, nullable=True)
age = db.Column(db.Integer, default=0)
class UserAddress(db.Model):
""" 用户的地址 """
__tablename__ = 'weibo_user_addr'
id = db.Column(db.Integer, primary_key=True)
addr = db.Column(db.String(256), nullable=False)
user_id = db.Column(db.Integer, db.ForeignKey('weibo_user.id'), nullable=False)
user = db.relationship('User', backref=db.backref('address', lazy=True))
@app.route('/')
def mine():
""" 首页 """
return render_template('index.html')
使用ORM插入、修改、删除数据
新增/修改数据
构造ORM模型对象
usr = User('admin','[email protected])
添加到db.session(备注:可添加多个对象)
db.session.add(user)
提交到数据库
db.session.commit()
物理删除数据:
查询ORM模型对象
user = User.query.filter_by(username='zhangsan').first()
添加到db.session
db.session.delete(user)
提交到数据库
db.session.commit()
使用ORM进行数据查询与展示
返回结果集(list)
查询所有数据
User.query.all()
按条件查询
User.query.filter_by(username='zhangsan')
User.query.filter(User.nickname.endswith('三')).all()
排序
order_by()
查询结果时,使用order_by()方法,可以指定根据表中的某个字段进行排序
User.query.order_by(User.username)
查询TOP10
User.query.limit(10).all()
返回单个ORM对象
模型定义时声明
有时候,不想每次在查询的时候都指定排序的方式,可以在定义模型的时候就指定默认排序的方式。
默认情况下是升序,还可以指定按降序方式输出结果。
PK(主键)查询
User.query.get(1)
获取第一条记录
User.query.first()
视图快捷函数:有则返回,无则返回404
first() vs first_or_404()
get() vs get_or_404()
多表关联查询
db.session.query(User).join(Address)
User.query.join(Address)
分页:
方式一:使用offset和limit
offset(偏移量) 与 limit(数据条数限制)
.offset(offset).limit(limit)
方式二:paginate分页支持
.paginte(page=2,per_page=4)
返回Pagination的对象
Pagination的对象:
has_prev/has_next——是否有上一页/下一页
Items——当前页的数据列表
prev_num/next_num——上一页/下一页的页码
total——总记录数
pages——总页数
paginate()方法的示例代码如下:
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///database.db'
db = SQLAlchemy(app)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(80), nullable=False)
content = db.Column(db.Text, nullable=False)
@app.route('/')
def index():
page = request.args.get('page', 1, type=int)
per_page = request.args.get('per_page', 10, type=int)
posts = Post.query.paginate(page=page, per_page=per_page)
return render_template('index.html', posts=posts)
结合模板实现分页
第一步:准备数据
list_user = User.query.filter_by(is_valid=1)
第二步:分页
list_user.paginate(page=2, per_page=4)
第三步:在模板中实现分页操作
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 配置数据库的连接参数
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:@127.0.0.1/test_flask'
db = SQLAlchemy(app)
class User(db.Model):
__tablename__ = 'weibo_user'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), nullable=False)
password = db.Column(db.String(256), nullable=False)
birth_date = db.Column(db.Date, nullable=True)
age = db.Column(db.Integer, default=0)
class UserAddress(db.Model):
""" 用户的地址 """
__tablename__ = 'weibo_user_addr'
id = db.Column(db.Integer, primary_key=True)
addr = db.Column(db.String(256), nullable=False)
user_id = db.Column(db.Integer, db.ForeignKey('weibo_user.id'), nullable=False)
user = db.relationship('User', backref=db.backref('address', lazy=True))
@app.route('/user/<int:page>/')
def list_user(page):
""" 用户分页 """
per_page = 10 # 每一页的数据大小
# 1. 查询用户信息
user_ls = User.query
# 2. 准备分页的数据
user_page_data = user_ls.paginate(page, per_page=per_page)
return render_template('list_user.html', user_page_data=user_page_data)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>用户分页操作</title>
</head>
<body>
<h3>总共有{
{ user_page_data.total }}用户,当前在第{
{ user_page_data.page }}页用户, 总共{
{ user_page_data.pages }}页</h3>
<p>
用户列表:
<ul>
{% for user in user_page_data.items %}
<li>{
{ user.username }} - {
{ user.password }}</li>
{% endfor %}
</ul>
{% if user_page_data.has_prev %}
<a href="{
{ url_for('list_user', page=user_page_data.prev_num) }}">上一页</a>
{% endif %}
{% if user_page_data.has_next %}
<a href="{
{ url_for('list_user', page=user_page_data.next_num) }}">下一页</a>
{% endif %}
</p>
</body>
</html>
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine(DB_URL)
Base = declarative_base(engine)
https://blog.csdn.net/stone0823/article/details/112344065
sql 报错
https://www.ngui.cc/article/show-939622.html?action=onClick
sqlacodegen
python -m pip install sqlacodegen -i "https://pypi.doubanio.com/simple/"
它读取现有数据库的结构并生成适当的 sqlalchemy模型代码,尽可能使用声明式样式。
这个工具是作为sqlautocode的替代品编写的,它有几个问题 (包括但不限于与python 3和最新sqlalchemy版本不兼容)。
功能
支持SQLAlchemy 0.8.x-1.3.x
生成几乎像是手写的声明性代码
生成符合PEP 8的代码
准确确定关系,包括多对多、一对一
自动检测联接表继承
出色的测试覆盖率
sqlacodegen postgresql+psycopg2://username:password@host/database --outfile models.py
至少,您必须给sqlacodegen一个数据库url。url直接传递给 sqlalchemy的create_engine()方法,请参考SQLAlchemy’s documentation 关于如何构造正确url的说明。
示例:
sqlacodegen postgresql:///some_local_db
sqlacodegen mysql+oursql://user:password@localhost/dbname
sqlacodegen sqlite:///database.db
查看选项的完整列表:
sqlacodegen --help
为什么它有时生成类,有时生成表?
除非使用--noclasses选项,否则sqlacodegen将尝试生成声明性模型类 从每张桌子上。有两种情况下会生成Table:
表没有主键约束(对于每个模型类,sqlalchemy都需要主键约束)
该表是其他两个表之间的关联表(有关详细信息,请参见下文)
模型类命名逻辑
表名(假定为英语)使用 “屈折”库。然后,在将下一个字母转换为大写字母时删除每个下划线 案例。例如,sales_invoices变成SalesInvoice。
关系检测逻辑
关系是根据现有的外键约束来检测的:
{
STR 1 }多对1 < /强>:表上存在外键约束 {
STR 1 }一对一< /强>:与^ {
STR 1 }相同:$1对1 < /强>,但在涉及的列上存在唯一约束
{
STR 1 }多对多< <强> >:发现两个表
之间存在关联表
如果表满足以下所有条件,则它被视为关联表:
只有两个外键约束
它的所有列都包含在上述约束中
关系命名逻辑
关系通常基于相反的类名命名。例如,如果Employee 类有一个名为employer的列,该列有一个到Company.id的外键,关系 名为company。
但是,对于单列多对一和一对一关系的一个特殊情况是 列的名称类似于employer_id。然后,由于这个关系被命名为employer。 _id后缀。
如果将使用同一名称创建多个关系,则将附加后一个关系 数字后缀,从1开始。
https://www.likecs.com/show-308587887.html
Flask-SQLAlchemy 是一个用于 Flask 框架的数据库操作库,它可以实现多种关系查询,如一对一、一对多、多对多等。关联查询的基本步骤是:
在模型类中定义外键字段和关联属性
在查询时使用 join 或 outerjoin 方法连接两个或多个模型类
在过滤或排序时使用模型类的属性或关联属性
以下是一个简单的示例代码,展示了如何使用 Flask-SQLAlchemy 进行一对多的关联查询123:
from flask import Flask
from flask_sqlalchemy impor








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











