异步任务队列/ 基于分布式消息传递的作业队列。
它侧重于实时操作,但对调度支持也很好。
celery用于生产系统每天处理数以百万计的任务。
AttributeError: 'EntryPoints' object has no attribute 'get'
pip install frozenlist== 1.3 .1 geopy== 2.2 .0 humanize== 4.3 .0 idna== 3.3 importlib- metadata== 4.12 .0 jsonschema== 4.9 .0 korean_lunar_calendar== 0.2 .1 marshmallow== 3.17 .0 pyOpenSSL== 22.0 .0 pyrsistent== 0.18 .1 python- dotenv== 0.20 .0 pytz== 2022.2 .1 selenium== 4.4 .0 simplejson== 3.17 .6 sniffio== 1.2 .0 trio== 0.21 .0 urllib3== 1.26 .11 wsproto== 1.1 .0 zipp== 3.8 .1
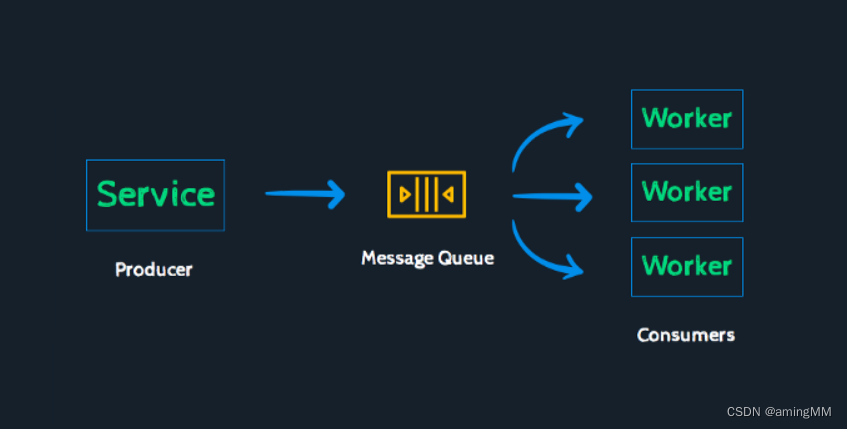
Celery是一个由Python开发的异步分布式任务调度模块,它专注于实时任务处理,同时也支持任务调度。
Celery的架构由三个主要组件构成:消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)。Celery本身不含消息服务,而是使用第三方的消息服务来传递任务,目前支持的消息服务包括RabbitMQ、Redis以及数据库等。
以上信息仅供参考,如需了解更多关于Celery的信息,建议查阅其官方文档或咨询专业的技术人员。
platforms. C_FORCE_ROOT = True
是一个Python语句,用于设置celery. platforms模块中的C_FORCE_ROOT变量为True 。1
celery是一个使用Python开发的分布式任务调度模块,可以用于异步执行任务或定时调度任务。
celery. platforms是一个提供平台相关的功能和工具的模块,
其中C_FORCE_ROOT是一个环境变量,用于控制celery是否允许以root用户启动。
如果使用root用户启动celery,会遇到以下的警告:
Running a worker with superuser privileges when the worker accepts messages serialized with pickle is a very bad idea!
If you really want to continue then you have to set the C_FORCE_ROOT environment variable ( but please think about this before you do) .
这是因为使用root用户启动celery可能存在安全风险,特别是当使用pickle作为序列化格式时,可能导致任意代码执行的漏洞。
如果你确实需要以root用户启动celery,你可以通过以下几种方式设置C_FORCE_ROOT环境变量为True :
在命令行中输入export C_FORCE_ROOT= "true" ,然后启动celery。
在shell配置文件(如~ / . bashrc)中添加export C_FORCE_ROOT= "true" ,然后重新加载配置文件。
在Python代码中导入celery. platforms模块,并设置platforms. C_FORCE_ROOT = True ,然后启动celery。
@celery. task ( queue= ‘arltask’) 这是一个Python装饰器,用于将一个函数定义为celery的任务,并指定该任务使用的队列为’arltask’。1
celery是一个使用Python开发的分布式任务调度模块,可以用于异步执行任务或定时调度任务。2
celery. task是一个提供任务相关的功能和工具的模块,其中task是一个装饰器,用于将一个函数转换为celery的任务,并返回一个Task类的实例。3
queue是一个参数,用于指定任务使用的队列名称。队列是一种用于存储和传递消息的数据结构,celery使用队列来分发任务给不同的worker进程。
例如,以下代码定义了一个名为add的函数,并将其转换为celery的任务,同时指定该任务使用的队列为’arltask’:
from celery import Celery
app = Celery( 'tasks' , broker= 'amqp://guest@localhost//' )
@app. task ( queue= 'arltask' )
def add ( x, y) :
return x + y
一些常用的参数有:
- -A, --app < app> :指定 celery 应用程序的名称或模块。
- -b, --broker < broker> :指定 broker 的 URL。
- –result-backend < result_backend> :指定 result backend 的 URL。
- -l, --loglevel < loglevel> :指定日志的级别,可以是 DEBUG| INFO| WARNING| ERROR| CRITICAL| FATAL 之一。
- -f, --logfile < logfile> :指定日志文件的路径。
- -c, --concurrency < concurrency> :指定 worker 的并发数。
- -Q, --queues < queues> :指定 worker 监听的队列,可以是一个或多个队列,用逗号分隔。
- --pool < pool> :指定 worker 使用的池类型,可以是 prefork| solo| eventlet| gevent 之一。
Celery是一个Python库,用于异步执行任务。
要启动Celery worker,你需要在你的项目中创建一个celery. py文件,
定义一个Celery实例,并导入你的任务模块。
然后,你可以在命令行中使用以下命令来启动worker:
celery - A project worker - - loglevel= info
其中,project是你的项目名,worker是要启动的worker类型,loglevel是要显示的日志级别。你可以根据你的需要修改这些参数1 。
Usage: celery [ OPTIONS] COMMAND [ ARGS] . . .
Celery command entrypoint.
Options:
- A, - - app APPLICATION
- b, - - broker TEXT
- - result- backend TEXT
- - loader TEXT
- - config TEXT
- - workdir PATH
- C, - - no- color
- q, - - quiet
- - version
- - help Show this message and exit.
Commands:
amqp AMQP Administration Shell.
beat Start the beat periodic task scheduler.
call Call a task by name.
control Workers remote control.
events Event- stream utilities.
graph The ``celery graph`` command.
inspect Inspect the worker at runtime.
list Get info from broker.
logtool The ``celery logtool`` command.
migrate Migrate tasks from one broker to another.
multi Start multiple worker instances.
purge Erase all messages from all known task queues.
report Shows information useful to include in bug- reports.
result Print the return value for a given task id .
shell Start shell session with convenient access to celery symbols.
status Show list of workers that are online.
upgrade Perform upgrade between versions.
worker Start worker instance.
用法:芹菜[ OPTIONS] 命令[ ARGS] 。。。
芹菜命令入口点。
选项:
- A、 - - 应用程序应用程序
- b、 - - 经纪人文本
- - 结果后端文本
- - 加载程序文本
- - 配置文本
- - 工作目录路径
- C、 - - 没有颜色
- q、 - - 安静
- - 版本
- - help 显示此消息并退出。
命令:
amqp amqp管理外壳。
beat启动beat周期性任务调度程序。
call按名称调用任务。
控制工人远程控制。
events事件流实用程序。
graph“芹菜图”命令。
inspect在运行时检查工作人员。
list 从经纪人处获取信息。
logtool“芹菜logtool”命令。
migrate将任务从一个代理迁移到另一个代理。
multi启动多个工作实例。
清除清除所有已知任务队列中的所有消息。
report显示可包含在错误报告中的有用信息。
result打印给定任务id 的返回值。
shell通过方便地访问芹菜符号启动shell会话。
status显示联机工作人员的列表。
升级在不同版本之间执行升级。
worker启动worker实例。
Celery中的- Q参数是用来指定worker要监听的队列的。你可以用它来给不同的任务分配不同的优先级或者不同的资源1 。例如,你可以这样启动一个worker,让它只处理hipri和lopri两个队列中的任务:
celery - A proj worker - l INFO - Q hipri, lopri
你也可以用逗号分隔多个队列名,或者用星号匹配所有队列1
你好,这是Bing。Celery中的- n参数是用来指定worker的节点名的。你可以用它来给不同的worker分配不同的标识,方便管理和监控1 。例如,你可以这样启动三个worker,让它们分别使用worker1、worker2和worker3作为节点名:
celery - A proj worker - - loglevel= INFO - - concurrency= 10 - n worker1@% h
celery - A proj worker - - loglevel= INFO - - concurrency= 10 - n worker2@% h
celery - A proj worker - - loglevel= INFO - - concurrency= 10 - n worker3@% h
其中,% h是一个变量,表示主机名,包括域名2 。你也可以用% n表示主机名不包括域名,或者用% d表示域名2 。
Celery有很多命令行参数,用来控制不同的功能。以下是一些常用的参数及其功能的列表1 :
- A, - - app < app> 指定Celery应用的模块或对象名
- b, - - broker < broker> 指定消息代理的URL
- - result- backend < result_backend> 指定任务结果存储的后端
- - loader < loader> 指定加载器类
- - config < config> 指定配置模块
- - workdir < workdir> 指定工作目录
- C, - - no- color 禁用彩色输出
- q, - - quiet 禁用所有日志输出
- - version 显示Celery的版本信息
celery worker [ OPTIONS] 启动worker实例
- n, - - hostname < hostname> 指定worker的节点名
- Q, - - queues < queues> 指定worker要监听的队列
- c, - - concurrency < concurrency> 指定worker的并发数
- D, - - detach 让worker在后台运行
- l, - - loglevel < loglevel> 指定日志级别
- f, - - logfile < logfile> 指定日志文件
celery beat [ OPTIONS] 启动beat周期任务调度器
- s, - - schedule < schedule> 指定调度数据库的路径
- S, - - scheduler < scheduler> 指定调度器类
celery call [ OPTIONS] NAME 调用一个任务
- a, - - args < args> 指定任务的位置参数
- k, - - kwargs < kwargs> 指定任务的关键字参数
celery control [ OPTIONS] COMMAND [ ARGUMENTS] . . . 远程控制worker节点
- E, - - enable- events 开启事件发送
- d, - - destination < destination> 指定目标节点
celery inspect [ OPTIONS] COMMAND [ ARGUMENTS] . . . 查看worker节点的信息
- E, - - enable- events 开启事件发送
- d, - - destination < destination> 指定目标节点
celery amqp [ OPTIONS] COMMAND [ ARGUMENTS] . . . AMQP管理工具
celery multi [ OPTIONS] COMMAND [ ARGUMENTS] . . . 管理多个worker实例
celery shell [ OPTIONS] [ SHELL] . . . 启动一个交互式shell
celery status [ OPTIONS] . . . 显示在线worker节点的状态
celery report [ OPTIONS] . . . 显示诊断报告
celery upgrade [ OPTIONS] . . . 升级Celery到最新版本
AMQP是一种开放的消息传递协议,用于在不同的应用程序或系统之间发送和接收消息。
Python有多个库可以实现AMQP协议,其中一个是Pika,它是RabbitMQ团队推荐的Python客户端。要使用Pika,你需要先安装它:
python - m pip install pika - - upgrade
然后,你可以编写一些代码来发送和接收消息。以下是一个简单的例子,演示了如何使用Pika发送一条消息到一个名为"hello" 的队列,以及如何从该队列中接收消息1 。
send. py
import pika
connection = pika. BlockingConnection( pika. ConnectionParameters( 'localhost' ) )
channel = connection. channel( )
channel. queue_declare( queue= 'hello' )
channel. basic_publish( exchange= '' ,
routing_key= 'hello' ,
body= 'Hello World!' )
print ( " [x] Sent 'Hello World!'" )
connection. close( )
receive. py
import pika
connection = pika. BlockingConnection( pika. ConnectionParameters( 'localhost' ) )
channel = connection. channel( )
channel. queue_declare( queue= 'hello' )
def callback ( ch, method, properties, body) :
print ( " [x] Received %r" % body)
channel. basic_consume( queue= 'hello' ,
auto_ack= True ,
on_message_callback= callback)
print ( ' [*] Waiting for messages. To exit press CTRL+C' )
channel. start_consuming( )
要运行这个例子,你需要先启动RabbitMQ服务器,然后在一个终端中运行receive. py,再在另一个终端中运行send. py。你应该能看到receive. py打印出收到的消息。
Python celery 是一个用于分布式任务队列的库,
它可以让你在后台异步地执行一些耗时或复杂的工作,而不影响 HTTP 请求- 响应循环。
Celery 通过消息来通信,通常使用一个代理(broker)来在客户端和工作进程之间传递消息。
要启动一个任务,客户端将一个消息放入队列,代理然后将该消息传递给一个工作进程。
一个 Celery 系统可以由多个工作进程和代理组成,从而实现高可用性和水平扩展。
Celery 是用 Python 编写的,但是它的协议可以用任何语言实现。
除了 Python 之外,还有 node- celery 和 node- celery- ts 用于 Node. js,以及一个 PHP 客户端。
语言互操作性也可以通过暴露一个 HTTP 端点并让一个任务请求它来实现(webhooks)。
要使用 Python celery,你需要安装它并配置一个代理。
Celery 支持多种代理,如 RabbitMQ, Redis, SQS 等,但是最常用的是 RabbitMQ 和 Redis。
你还需要定义一些任务函数,并用 @app. task 装饰器来注册它们。
然后你就可以在代码中调用这些任务函数,并使用 delay( ) 或 apply_async( ) 方法来将它们放入队列中。
你还需要启动一些 Celery 工作进程来执行队列中的任务。
下面是一个简单的 Python celery 应用的例子:
from celery import Celery
app = Celery( 'tasks' , broker= 'amqp://guest@localhost//' )
@app. task
def add ( x, y) :
return x + y
from tasks import add
result = add. delay( 4 , 4 )
print ( result. get( ) )
使用Python的Celery库来创建一个任务队列的实例。任务队列是一种分布式工作机制,可以用来异步地执行一些耗时或复杂的任务,而不影响HTTP请求响应的流程。具体来说,这行代码的意思是:
celery = Celery( ‘task’, broker= Config. CELERY_BROKER_URL) :创建一个Celery类的实例,命名为celery。
‘task’:指定这个实例的名称,用于区分不同的任务队列。
broker= Config. CELERY_BROKER_URL:指定这个实例使用的消息代理(broker),用于在客户端和工作进程之间传递消息。Config. CELERY_BROKER_URL是一个配置变量,存储了消息代理的地址和协议。常用的消息代理有RabbitMQ和Redis。
celery 是一个用于分布式任务队列的 python 框架,可以让你在后台执行异步的任务1 。调试 celery 的任务有以下几种方式:
使用 celery. contrib. rdb 模块,它是一个扩展了 pdb 的远程调试器,可以让你通过 telnet 连接到没有终端访问的进程中进行调试1 。你只需要在你的任务函数中加入 rdb. set_trace( ) 语句,就可以设置一个断点,然后在终端中使用 telnet 命令连接到指定的端口,就可以使用 pdb 的命令进行调试了1 。
使用 CELERY_RDBSIG 环境变量,它可以让你在发送 SIGUSR2 信号给 worker 进程时启动一个 rdb 实例1 。你可以在启动 worker 时设置这个环境变量,然后使用 kill - USR2 < pid> 命令给任何一个 worker 进程发送信号,就可以打开一个 rdb 会话了1 。
使用 debugpy 模块,它是一个用于 VS Code 的 python 调试器,可以让你在 VS Code 中有更好的调试体验2 。你可以在启动 celery 时使用 debugpy. listen( ) 函数来监听一个端口,然后在 VS Code 中配置一个远程调试器来连接到这个端口,就可以在 VS Code 中设置断点和查看变量了2 。
from celery import Celery
from celery. utils. log import get_task_logger
app = Celery( 'tasks' , broker= 'redis://localhost:6379/0' )
logger = get_task_logger( __name__)
@app. task
def add ( x, y) :
logger. info( 'Adding %s + %s' % ( x, y) )
return x + y
[ 2021 - 12 - 16 16 : 13 : 49 , 123 : INFO/ MainProcess] Received task: tasks. add[ 12345678 ]
[ 2021 - 12 - 16 16 : 13 : 49 , 456 : INFO/ ForkPoolWorker- 1 ] tasks. add[ 12345678 ] : Adding 3 + 4
[ 2021 - 12 - 16 16 : 13 : 49 , 789 : INFO/ ForkPoolWorker- 1 ] Task tasks. add[ 12345678 ] succeeded in 0 . 333s: 7
你好,这是Bing。根据搜索结果,你可以使用celery自带的日志记录器来写入celery日志。123
你可以在tasks. py文件中引入以下代码:
from celery. utils. log import get_task_logger
logger = get_task_logger( 'myapp' )
logger. info( 'some message' )
错误是由于你在Windows系统上运行celery时遇到的兼容性问题。123
有几种可能的解决方法:
你可以在启动celery worker时指定–pool= solo参数,例如:celery - A celery_worker. celery worker - - pool= solo - l info2
你可以安装eventlet或gevent库,并在启动celery worker时指定- P eventlet或- P gevent参数,例如:celery - A celery_worker. celery worker - P eventlet - l info14
你可以在你的celery配置文件中设置os. environ. setdefault( 'FORKED_BY_MULTIPROCESSING' , '1' ) 3
celery - A app. celerytask. celery worker - - pool= solo - l DEBUG - P eventlet - Q Godtask - n Godtask - c 5 - O fair - f GOd_worker. log
celery - A app. celerytask. celery worker - - pool= solo - l DEBUG - Q Godtask - n Godtask - c 5 - O fair - f GOd_worker. log
- A app. celerytask. celery:指定celery应用的模块名
worker:指定celery的工作模式
–pool= solo:指定celery使用单进程池来执行任务
- l DEBUG:指定celery的日志级别为DEBUG
- Q Godtask:指定celery从Godtask队列中获取任务
- n Godtask:指定celery的节点名为Godtask
- c 5 :指定celery的并发数为5
- O fair:指定celery使用公平调度策略,即不预取任务
- f GOd_worker. log:指定celery的日志文件名为GOd_worker. log
celery work 是一个用于执行异步任务的工具1 。它由 celery workers 和 celery beat 组成。celery workers 是运行任务的工作进程,它们可以独立于主服务和彼此之间运行。celery beat 是一个调度器,它安排何时运行任务。你可以用它来安排周期性的任务。celery workers 是 celery 的核心1 。
celery work 和其他异步任务工具有一些区别。首先,celery work 是基于分布式消息传递的任务队列,它需要一个消息代理和一个结果后端来进行通信和存储1 。其他的异步任务工具可能不需要这些组件,或者使用不同的技术来实现。其次,celery work 是异步的,但不是“Python async ”的,因为它早于 Python 的 asyncio 出现2 。其他的异步任务工具可能使用 Python 3 + 的 asyncio 和相关的库来编写异步代码。最后,celery work 有一些特殊的功能,比如 celery beat 和 celery canvas,它们可以用来调度周期性的任务和创建复杂的工作流1 。
relery 报错 ValueError: not enough values to unpack ( expected 3 , got 0 ) 的方法。根据搜索结果123 ,你可以尝试以下方法之一:
检查你的函数返回值和接收返回值的参数个数是否一致,如果不一致,修改成一致。这个错误可能是由于返回值和参数个数不匹配导致的。例如:
def example ( x, y) :
a = x - y
b = x + y
c = x * y
return a, b, c
if __name__ == '__main__' :
x, y = example( 1 , 2 )
安装 eventlet 库,并在启动 worker 的时候加上 - P eventlet 参数。这个错误可能是由于 Windows 不支持 celery 的并行处理导致的。例如:
pip install eventlet
celery - A celery_worker. celery worker - l info - P eventlet
使用celery purge命令,可以清除指定或排除指定的任务队列中的所有信息。例如:
celery - A celery_task. celery purge
celery - A celery_task. celery purge - Q default, tasks_A
celery - A celery_task. celery purge - X tasks_B
使用celery revoke命令,可以取消指定的任务ID或任务名称的任务。例如:
celery - A celery_task. celery revoke 8860e78a- b82b- 4715 - 980c- ae125dcab2f9
celery - A celery_task. celery revoke tasks. taskA
使用celery inspect命令,可以查看当前的任务状态和队列情况,然后根据需要取消或清除任务。例如:
celery - A celery_task. celery inspect active
celery - A celery_task. celery inspect reserved
celery - A celery_task. celery inspect scheduled
您需要安装celery和redis,并配置celery实例,指定broker和backend的访问方式,任务模块的申明等1 。
您可以使用@task的装饰器来定义celery任务,并在任务中使用time. sleep( ) 来模拟一个长时间的任务2 。
您可以使用delay( ) 方法来异步调用任务,并使用ready( ) 和result属性来检查任务是否完成和获取任务结果2 。
以便celery可以访问rabbitmq2
您可以使用celery - A test_celery worker - - loglevel= info命令来启动celery worker,并在项目文件夹中运行2 。
cerely是一个基于python开发的分布式异步消息任务队列,它可以通过消息中间件(如redis或rabbitmq)来接收和发送任务消息,以及存储任务结果。你可以使用celery的装饰器@app. task来定义异步任务,并使用delay或apply_async方法来提交任务给worker进程执行。你还可以使用flower web监控工具来查看任务的执行情况和结果。
Flower web监控工具是一个基于web的监控和管理celery的工具。它可以用来查看celery的worker状态和统计,任务进程和历史,任务的详细信息和结果,以及远程控制worker和任务12 。你可以使用pip安装flower,并使用celery - A tasks flower - - broker = redis: // localhost: 6379 / 0 命令来启动flower服务1 。然后你可以访问http: // localhost: 5555 / 来查看flower的web界面2 。
Celery是一个分布式任务队列,可以用来执行异步的工作。Celery中有两个重要的概念:worker和task。Worker是执行任务的进程,task是具体的工作单元。Celery可以配置worker的并发度和多个worker的数量,以提高任务的处理能力。
Worker的并发度是指一个worker进程可以同时执行多少个task。Celery提供了不同的并发实现方式,如prefork(默认)、eventlet、gevent等。Prefork就是多进程的方式去实现并发,每个进程只执行一个task。Eventlet和gevent是基于协程的方式去实现并发,每个进程可以执行多个task,但是需要注意协程的切换和兼容性问题。Celery可以通过- c参数指定worker的并发度,如- c 4 表示一个worker可以同时执行4 个task12。
多个worker是指在不同的机器或者进程上启动多个worker进程,以实现分布式的任务处理。多个worker可以订阅同一个或者不同的队列,根据任务的路由规则接收和执行任务。多个worker可以提高任务的可靠性和容错性,如果一个worker挂掉了,其他的worker还可以继续工作。Celery可以通过- n参数指定worker的名称,如- n worker1@% h表示启动一个名为worker1@主机名的worker1。
综上所述,celery中的worker并发和多个worker是两个不同维度的概念,都可以用来提高celery的性能和稳定性。但是也要注意合理配置worker的数量和并发度,避免资源浪费和竞争。
Flower Dashboard 上的 Active 是指当前正在运行的 Celery 任务的数量1 。如果你想清空 Active 任务,你可以尝试终止或撤销它们2 ,或者重启 Worker 实例1 。不过,你可能需要注意,Flower Dashboard 的数据可能不是持久化的,也就是说,当你刷新页面时,所有的数据可能会丢失3 。如果你想要更可靠的监控方案,你可以考虑使用 Prometheus 和 Grafana 的集成
要终止或撤销任务,你可以在 Flower Dashboard 的 Tasks 页面上,点击你想要操作的任务的 ID,然后在弹出的窗口中,选择 Revoke 或 Terminate 按钮1 。或者,你也可以使用 Celery 的 Python API 来执行 revoke 或 terminate 函数2 。例如,你可以这样写:
from celery. task. control import revoke
revoke( task_id, terminate= True )
其中 task_id 是你想要终止或撤销的任务的 ID。注意,如果你使用 terminate= True 参数,你可能需要配置 CELERYD_FORCE_EXECV 选项为 True2。
Flower Dashboard 的数据不是持久化的,当你刷新页面时,所有的数据可能会丢失1 。
Flower Dashboard 的数据可能和 Celery 的状态不同步,导致显示错误的信息3 。
Flower Dashboard 的数据可能受到 Celery 的配置选项的影响,比如 CELERY_IGNORE_RESULT、CELERY_TRACK_STARTED、CELERY_SEND_EVENTS 等2 。
要解决这个问题,你可以尝试以下方法:
使用 Prometheus 和 Grafana 的集成来监控 Celery 的任务和队列2 。
检查 Celery 的配置选项是否正确,并且和 Flower 兼容2 。
重启 Flower 和 Celery,并清除缓存和数据库13 。
要使用 Prometheus 和 Grafana 的集成,你需要按照以下步骤进行1 :
启动 Celery Broker,比如 RabbitMQ 或 Redis。
设置你的 Celery 应用程序,并确保你的任务有正确的名称。
启动 Flower,访问 localhost: 5555 / metrics 查看 Flower 导出的 Celery 工作和任务的指标。
配置并启动 Prometheus,让它抓取 Flower 的指标。
启动 Grafana,并将 Prometheus 作为数据源添加到 Grafana 中。
在 Grafana 中导入 Celery 监控仪表盘,查看 Celery 的性能和状态。
要检查 Celery 的配置选项,你可以在你的 Celery 应用程序中使用 app. conf 属性来查看或修改配置2 。例如,你可以这样写:
from celery import Celery
app = Celery( 'tasks' , broker= 'amqp://guest@localhost//' )
print ( app. conf. CELERY_IGNORE_RESULT)
app. conf. CELERY_TRACK_STARTED = True
要重启 Flower 和 Celery,并清除缓存和数据库,你可以使用以下命令3 :
killall flower
killall celery
rm - rf / tmp/ celery- flower- cache/ *
rm - rf / tmp/ celery- flower- db/ *
celery - A proj worker - - loglevel= info
celery - A proj flower - - port= 5555
其中 proj 是你的 Celery 应用程序的名称。注意,这些命令可能因你的操作系统和安装方式而有所不同。
celery windows 如何清除缓存和数据库,你可以按照以下步骤进行:
如果你使用的是 Disk Cleanup 工具来清理缓存,你可以在任务栏的搜索框中输入 disk cleanup,然后从结果列表中选择 Disk Cleanup。选择你想要清理的驱动器,然后选择 OK。在 Files to delete 下,选择你想要删除的文件类型,比如 Temporary Files。然后选择 OK1。
如果你使用的是 Redis 作为 Broker 或 Backend,你可以使用 redis- cli 命令来清除 Redis 中的数据。你可以使用 flushdb 命令来清除当前数据库中的数据,或者使用 flushall 命令来清除所有数据库中的数据2 。例如,在你的 shell 中输入:
redis- cli flushall
你也可以尝试使用 celery purge 命令来清除 celery 中等待的任务2 。例如,在你的 shell 中输入:
celery - A proj purge
其中 proj 是你的 celery 应用程序的名称。
写shell需要转义下。闭合后面的特殊符号。redis出来的数据带特殊字符
对代码中的双引号进行转义。
windows不需要前后加\r\n\r\n
celery -A app.celerytask worker --pool = solo -l DEBUG -Q Godtask -n God_task -c 20 -O fair -f GOd_worker.log 已经设置了 -c 为20,为什么 tasks 只有一个在运行的原因可能是
- –pool= solo 指定了使用 solo 池,这是一种单线程的池,它不会创建任何子进程或线程,而是直接在主进程中执行任务。因此,无论你设置多少并发数(-c),它都只能同时执行一个任务。
- 如果你想要使用多进程或多线程的池,你可以使用其他的选项,
比如 --pool = prefork(默认)、
--pool = eventlet 或
--pool = gevent。这些选项会根据你设置的并发数(-c)创建相应数量的子进程或线程来执行任务。
- solo 池的优点是它不会受到 Python 的全局解释器锁(GIL)的影响,也不会有进程或线程之间的通信开销。它适合用于一些简单或快速的任务,或者用于调试目的。
想用celery和amqp一起工作,你需要做以下几步
- 安装celery和amqp的Python库,你可以使用pip或easy_install命令来安装。
- 安装并启动一个amqp的消息代理,比如rabbitmq。你可以从官网下载并安装rabbitmq,或者使用docker来运行它。
- 创建一个celery的实例,我们称之为celery应用或者app。这个实例是你在celery中做任何事情的入口,比如创建任务和管理工作节点。你需要确保其他模块可以导入这个实例。
- 在celery应用中配置broker参数,指定你的amqp的连接信息,比如用户名,密码,虚拟主机等。你可以使用broker_url这个设置来指定一个amqp的连接字符串。
- 创建你的celery任务,并用celery应用来装饰它们。你可以在任何模块中定义你的任务,只要它们可以被celery应用导入。
- 启动一个或多个celery的工作节点,让它们连接到你的amqp代理,并开始执行任务。你可以使用celery worker命令来启动工作节点。
[cerely 的 work 内运行的程序可以使用多线程,但是需要注意一些问题。多线程是一种让程序的不同部分可以并发(同时)执行的技术,可以提高 CPU 的利用率。例如,你可以在一个程序中写代码,同时在另一个程序中听音乐。](https://colaninfotech.com/blog/what-is-celery-why-is-it-a-must-have-skill-for-python-developers/)[1](https://colaninfotech.com/blog/what-is-celery-why-is-it-a-must-have-skill-for-python-developers/)[2](https://stackoverflow.com/questions/10951124/how-exactly-does-multithreading-work)[3](https://www.educative.io/blog/multithreading-and-concurrency-fundamentals)
但是,多线程也有一些缺点和风险,比如:
- 多线程可能会导致竞争条件,死锁,内存泄漏等问题,需要使用同步机制来避免。
- 多线程可能会增加程序的复杂度和调试难度,需要使用一些工具和方法来帮助开发和测试。
- 多线程可能会受到操作系统和硬件的限制,不能无限制地增加线程数目,需要根据实际情况进行优化和调整。
所以,如果你想在 cerely 的 work 内运行的程序中使用多线程,你需要考虑以下几点:
- 你的程序是否真的需要多线程,是否有其他更简单或更合适的方案。
- 你的程序是否能够合理地划分为多个独立或相互协作的线程,是否有明确的并发模型和策略。
- 你的程序是否能够正确地处理多线程可能引起的问题,是否有足够的测试和监控手段。
- 你的程序是否能够适应不同的操作系统和硬件环境,是否有良好的性能和可扩展性。
























 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









