







目录
1、什么是级联分类器
此处不做详解,可以参考这个博客:https://www.cnblogs.com/wumh7/p/9403873.html
2、分类器样本创建
样本创建是一个比较耗时耗资源的过程,但是前期做好一个优质的样本,对于后期的样本训练以及想获取到一个精度较高的分类器都是密切相关的。
样本,又分为正样本和负样本。通常样本基数越大,生成的分类器精度越高。如果检测的目标是一个固定物体,没有变化(如特定商标,logo等),这样的物体只要提供一份样本就可以进行训练。 但绝大数时候我们想进行训练的目标是非绝对固定的物体,如对人的检测,包括人脸识别、汽车等等,因此,创建一个合适的样本就十分重要。
2.1、正样本
2.1.1、什么是正样本
所谓正样本就是只包含检测目标的图片(最好背景一致),对于这我个人认为最好是检测目标的最小外接矩,这样可以减少训练的计算量,减少目标检测的干扰,提高检测质量。
2.1.2、正样本收集
获取正样本,可以自己动手,也可以通过网络上的图像数据库,像人脸数据库就已经很全了,不必再自己制作。
2.1.3、正样本处理
将正样本图片进行截取(自己收集的图片,主要是去掉训练时的不必要干扰)-----最小外接矩;
将处理后的图片进行归一化,将所有图像调整成一致大小,我用的“美图看看”这款软件,批量处理的,注意无论原图多大最好都处理成25*25以下的图像,这样计算机训练速度快,而且不容易出现内存不够用;
将归一化后的图像进行灰度处理,可以调用OpenCV中的接口,cv::cvtColor(Mat src, Mat outGray, COLOR_BGR2GRAY),自己c++写个批量处理小程序即可。如下处理后的灰度图片。
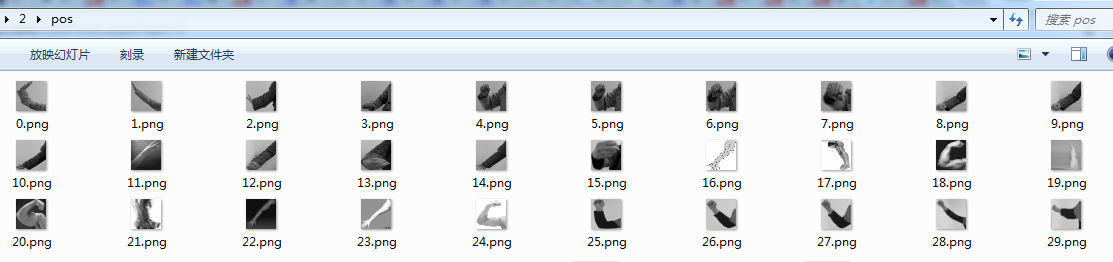
2.1.4、生成pos.txt文件
cmd运行控制台,切换到存放样本图片的文件目录下:输入如下命令

运行结果:
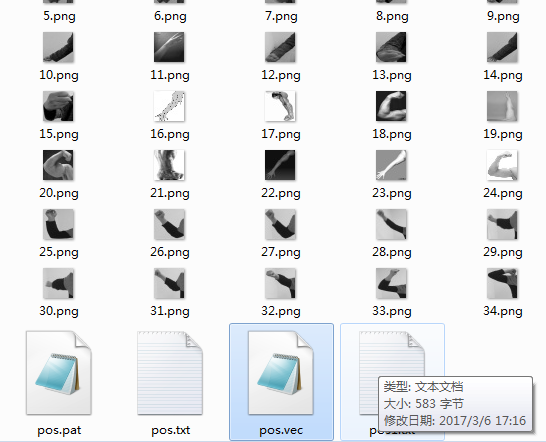
在图像文件中多了个pos.txt文件,内容如下:

在对文件进行处理,使其含有图片信息:通过程序读取存入

格式为:图片路径 检测目标在图片中的个数 起始监测点坐标(x,y) 图片大小(w,h)
2.1.5、训练.vec文件
cmd下运行一下命令(假设当前路径就是pos.txt所在的路径):
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 100 -w 30 -h 30
得到pos.vec文件。
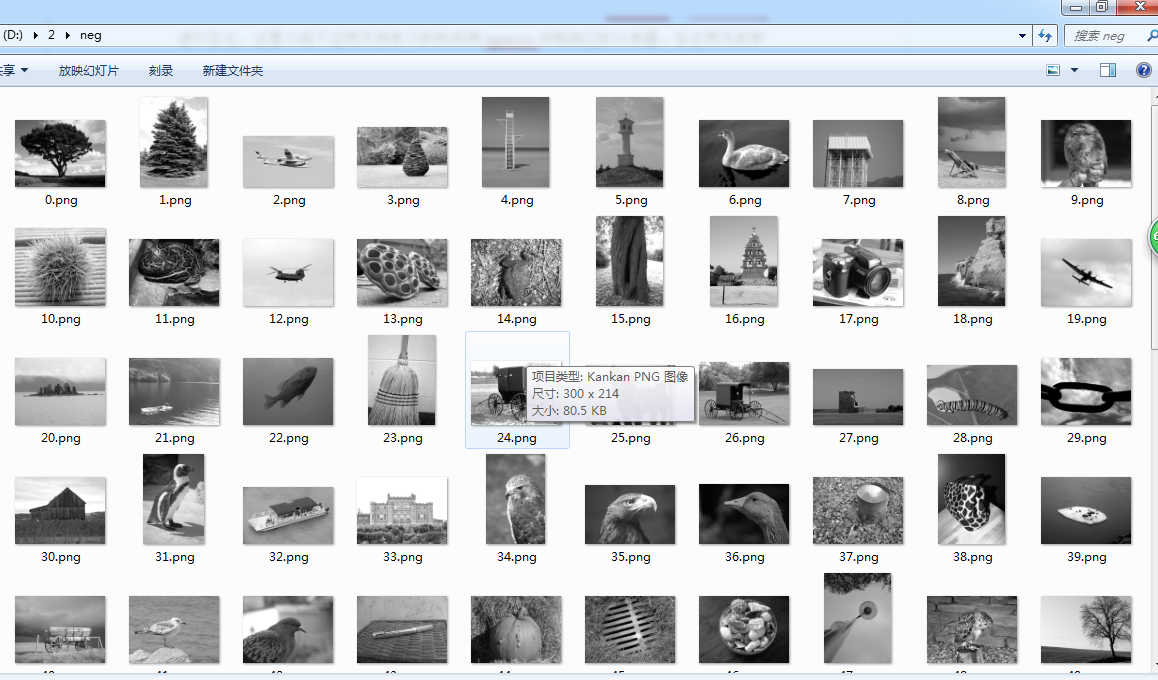
2.2、负样本
负样本,即不包含检测目标的任何图片。主要操作如下:
1、负样本不要求样本尺寸,但要大于等于正样本的大小;且负样本不能重复,要增大负样本的差异性;
2、负样本灰度化,同正样本操作相同。
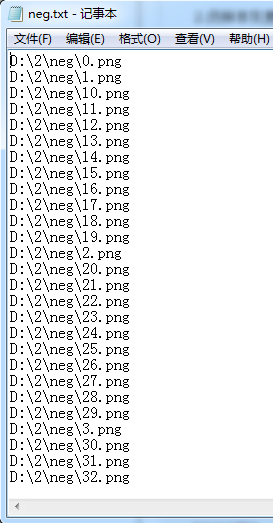
3、运行命令:

最后将pos.vec和neg.txt文件拷贝到同一文件夹下。
3、分类器生成
执行命令:
opencv_haartraining.exe -data xml -vec pos.vec -bg neg.txt -nstages 10 -nsplits 1 -npos 35 -nneg 100 -mem 1280 -mode all -w 30 -h 30
命令讲解:
opencv_haartraining.exe 是一个opencv自带的可执行函数(但此函数已经过时,最新的采用opencv_traincascade),用于实现对分类器的训练。直接在doc下用命令执行即可,Windows的存放路径一般为: ..\opencv\build\x86\vc11\bin。这里我为了找路径方便与样本文件放在同一目录下这样可以找到很容易调取 mlx文件夹,和pos.vec、neg.txt,也可以直接调用。
-data xml 存储训练时的生成的文件。最终生成一个.xml文件,如下图:
xml文件夹内容:
-vec pos.vec 调用.vec文件,与neg.txt放在同一目录下。
-bg neg.txt 负样本生成文件,可以理解成是负样本的索引。
-nstages 10 训练级数
-nsplits 1 2表示弱分类器二叉决策树的分裂数 1表示使用简单stump 分类(只有一个树桩)
-npos 35 正样本数量
-nneg 100 负样本数量
-mem 1280 训练时内存预留的空间1280MB
-mode all 级联器的类型,all代表所有类型
-w 30 图片的宽30像素,必须与之前一致
-h 30 图片的高30像素,必须与之前一致
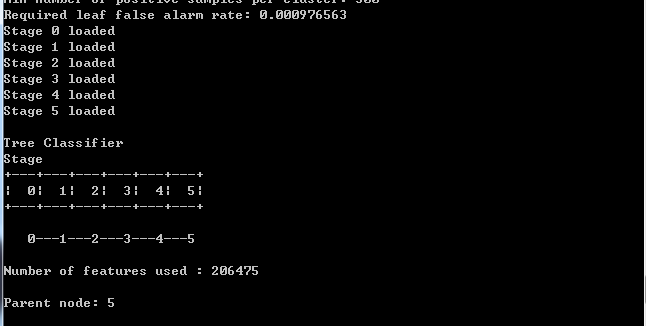
执行结果如下:
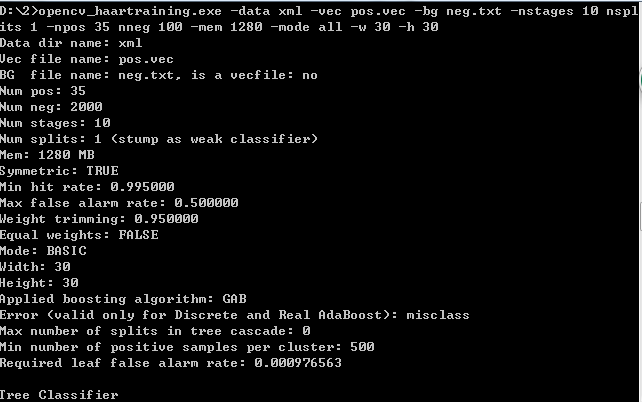
训练结果:
4、分类器测试
待测试。。
注:已以上图片来自于网络,如有侵权联系删除。















 1449
1449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









