







 本文介绍了如何使用MapReduce处理美国国家气候数据中心的气候数据。通过Linux命令下载并解压数据,然后编写MapReduce程序,包括TemperatureMapper、TemperatureReducer和TemperatureMain类,最后将jar包上传到集群并运行,成功找到最高温度。
本文介绍了如何使用MapReduce处理美国国家气候数据中心的气候数据。通过Linux命令下载并解压数据,然后编写MapReduce程序,包括TemperatureMapper、TemperatureReducer和TemperatureMain类,最后将jar包上传到集群并运行,成功找到最高温度。
使用的数据来自美国国家气候数据中心,首先我们要在Linux上去下载数据,打开linux终端,在终端下写入如下命令:wget -r -c fttp://ftp.ncdc.noaa.gov/pub/data/noaa/,下载数据,由于数据太大,我就只下载了一部分。步骤如下:
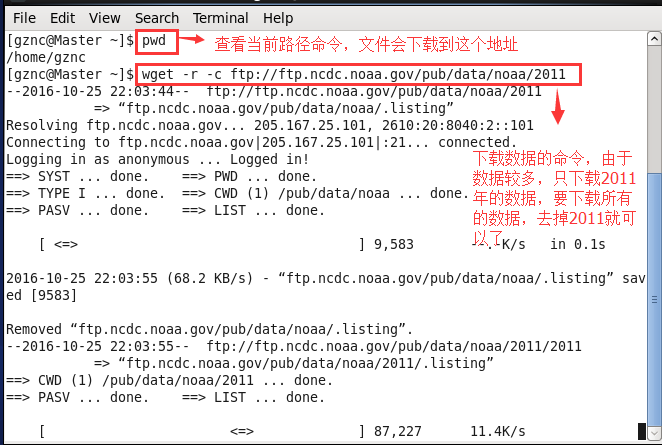
现在就去上面图片中的当前路径:/home/gznc中去查看下载的文件,我只下载了部分文件,看到
文件后将文件解压到桌面的abc.txt文件中,abc.txt文件可以自己随便命名。命令为zcat *.gz > /home/gznc/Desktop/abc.txt
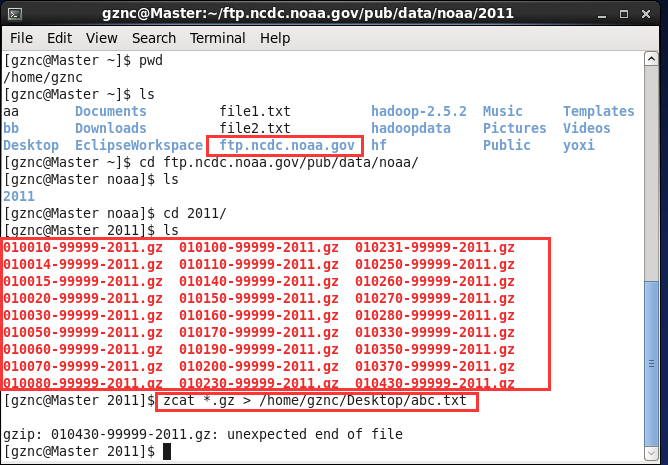
然后看桌面上的,就会有解压的文件
双击打开文件,就可以查看到解压的数据
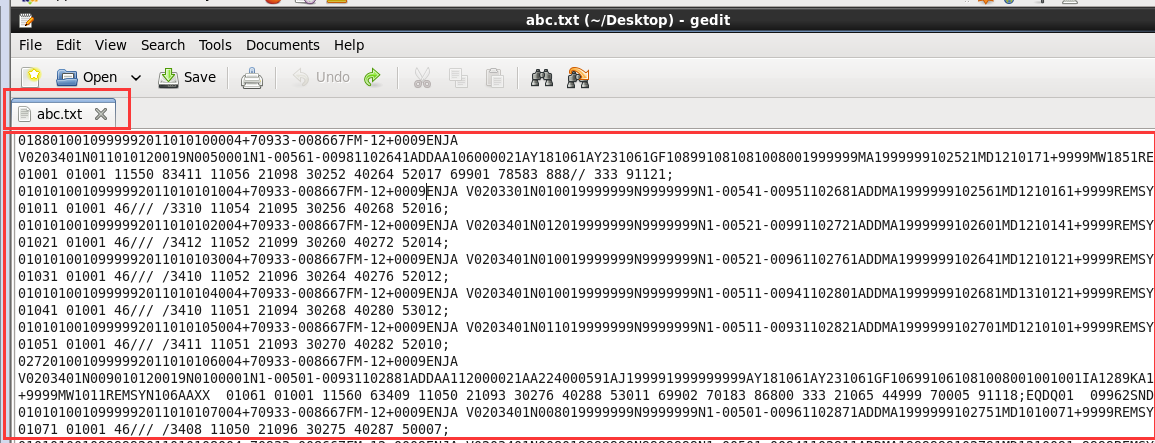
数据格式如下所示:
0188010010999992011010100004+70933-008667FM-12+0009ENJA V0203401N011010120019N0050001N1-00561-00981102641ADDAA106000021AY181061AY231061GF108991081081008001999999MA1999999102521MD1210171
+9999MW1851REMSYN088AAXX 01001 01001 11550 83411 11056 21098 30252 40264 52017 69901 78583 888// 333 91121
这是一行的数据,我们所需要的年份数据在第15个字符到第18个字符,温度在第88个到第92个字符
接下来就是编写代码块
TemperatureMapper类
package maxTemperature;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//创建一个 TemperatureMapper类 继承于Mapper抽象类
public class TemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private static final int MISSING = 9999;
//Mapper抽象类的核心方法,三个参数
public void map(LongWritable key,//首字符偏移量
Text value,//文件的一行内容
Context context//Mapper端的上下文,与OutputCollector和Reporter的功能类似
) throws IOException, Int 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3826
3826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









