






文章目录
前言
在文本中,我们常常需要查找特定的字符串。比如分析日志时我们会更加关注ERROR字样,然后定位到相关的位置。当然一个ctrl + F足以满足我们的需要,但是当我们需要找到以ERROR开头的行时,我们又该怎么做呢?普通的查找会将ERROR位于中间的行一并查找出来。只有正则表达式能够满足我们的要求。
一、正则表达式是什么?
正则表达式是一门编程语言,用户根据正则表达式的语法编写特定的模式,然后去匹配或者不匹配特定的字符串。我们最常用的查找某个字符串就是最简单的正则表达式。更进一步,我们需要查找某一类的字符串,就需要提取这类字符串的共同特征,然后利用正则表达式语法编写成特定的模式。
二、正则表达式的基础
1.高频用法
| 语法 | 效果 |
|---|---|
| . | 点号,匹配除换行符外任意一个字符(注意:一个点号就是匹配一个字符) |
| * | 将前一个规则匹配0次或者多次(记住的办法:0乘以任何数都是0 ) |
| + | 将前一个规则匹配1次或者多次 |
| \d | 匹配一个数字 |
| \w | 匹配任意单词的字元素(此处单词的定义:字母、数字和下划线元素的组合) |
| [a,b,c] | 匹配a、b、c中任意一个字母,类似枚举 |
| [a-z, A-Z] | 匹配26个字母,忽略大小写 |
| {n, m} | 匹配前一个规则n次到m次 |
| {n, } | 匹配前一个规则至少n次 |
| {n } | 匹配前一个规则n次 |
| ? | 匹配前一个规则0次或者1次(具体含义下文例子) |
| \s | 匹配空白字符,包括换行符 |
| \S | 大写S,匹配非空白字符 |
| ^a | 匹配a开头的字符串 |
| z$ | 匹配z结尾的字符串 |
| [^a,b] | 不能匹配a和b字符 |
如上表格中总结了正则表达式的高频基础用法,掌握上述用法足可以应对80%的正则表达式。
读者此时可以根据上述规则每个都尝试一遍,有助于记忆。正则匹配可视化工具:https://www.jyshare.com/front-end/854/?optionGlobl=global
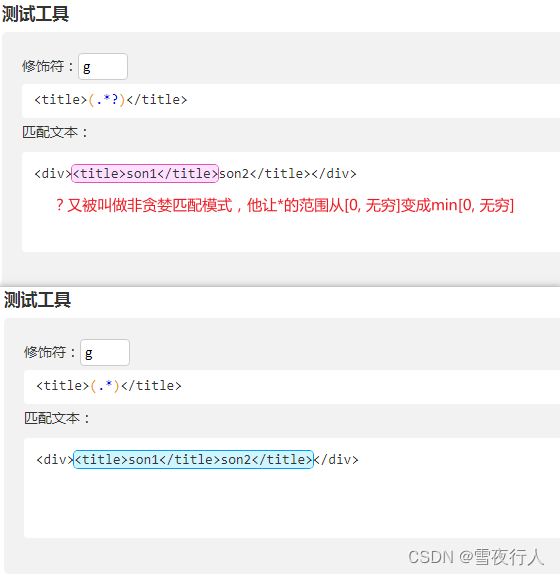
2.捕获分组
正则表达式的应用一般有两种,一种是校验某种字符串是否合法,比密码长度、IP字符串等,第二种就是提取特定的字符串。捕获分组可以帮我们实现这个功能。
比如我们需要匹配一个回文字符串。
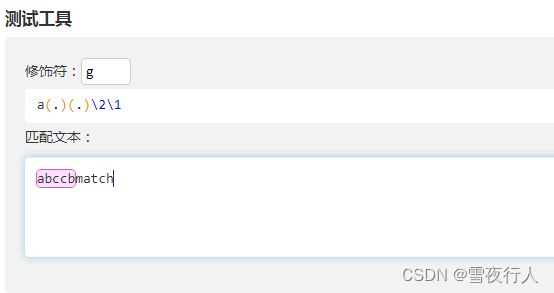
其中\1表示捕获的第一个分组。
另外,分组既然是括号来表示,那么也具有括号的普通功能,即将其视为一个整体。
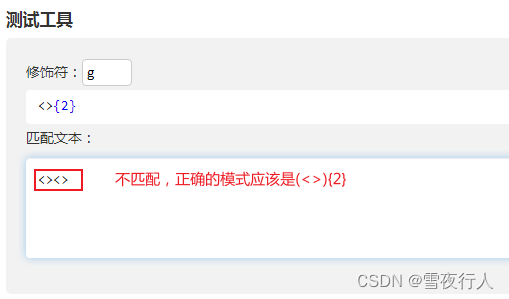
上述图片中匹配文本没变色表示模式没匹配中。
三、Python使用正则表达式
1.search函数
import re
m = re.search(r"(\d+)\s+(\w+)", "5 apples and 1 banana and 2 apples.")
print(m)
# <re.Match object; span=(0, 8), match='5 apples'>
# 没有匹配到2 apples,说明只匹配一次
print("m.group():", m.group())
# m.group(): 5 apples 结论:group表示正则表达式匹配的整体
print("m.group(0):", m.group(0))
# m.group(0): 5 apples 结论:group(0) == group()
print("m.group(1):", m.group(1))
# m.group(1): 5 结论:group(1)表示第一个捕获的分组
print("m.group(2):", m.group(2))
# m.group(2): apples 结论:group(2)表示第二个捕获的分组
print("m.group(1,2):", m.group(1, 2))
# m.group(1,2): ('5', 'apples') 结论:group(1, 2)表示第一、二个捕获的分组,返回元组形式
print("m.groups():", m.groups())
# m.groups(): ('5', 'apples') 结论:groups()表示所有捕获的分组
2.finditer函数
import re
m = re.finditer(r"(\d+)\s+(\w+)", "5 apples and 1 banana and 2 apples.")
for item in m:
print(item)
# 输出
# <_sre.SRE_Match object; span=(0, 8), match='5 apples'>
# <_sre.SRE_Match object; span=(13, 21), match='1 banana'>
# <_sre.SRE_Match object; span=(26, 34), match='2 apples'>
# 根据输出结果,可以发现finditer可以匹配多次
# 其中m表示一个迭代器
m = re.findall(r"(\d+)\s+(\w+)", "5 apples and 1 banana and 2 apples.")
for span in m:
print(span)
# 输出
# ('5', 'apples')
# ('1', 'banana')
# ('2', 'apples')
# 在finditer的基础上,获取每个匹配对象(item)的所有捕获分组
3.match函数
origin = "I have 5 apples and 1 banana and 2 apples."
m = re.match(r"(\d+)\s+(\w+)", origin)
print(m)
# 输出是None,注意match必须从origin字符串开头进行匹配,类似于str.startswith()函数
m = re.fullmatch(r"(\d+)\s+(\w+)", "5 apples and 1 banana and 2 apples.")
print(m)
# 输出是None,因为fullmatch必须全匹配,类似于==
4.字符转义
origin = "\\"
m1 = re.fullmatch("\\\\", origin)
print(m1)
# <_sre.SRE_Match object; span=(0, 1), match='\\'>
m2 = re.fullmatch(r"\\", origin)
print(m2)
# <_sre.SRE_Match object; span=(0, 1), match='\\'>
# 结论想要匹配反斜杠字符,要么使用四个\\\\,要么使用r开头
上述代码的原因在于字符转义。因为Python解释器和正则引擎都会对反斜杠做特殊的处理。
- 代码中的
\在Python中本身就不会被直接输出,反斜杠和n组成换行符,要想python解释器将反斜杠当成一个普通的字符,需要双反斜杠进行转义。这就是origin变量中用双反斜杠表示反斜杠字符的原因。 - 但是,反斜杠在正则表达式中还是有特殊含义,比如
\d,所以还要进行一次转义,所以就是四个反斜杠了。
r字符的含义就是告诉Python解释器把这些字符当成普通字符即可。
第一次接触match、search、find时很容易搞混每种函数的作用,但是转念一想,三个函数名称的语义已经暗含了这个意思:
匹配:鞋子匹不匹配肯定是从脚尖或者脚后跟开始比较,只要鞋子略长于脚即可,一般不会刚刚好(fullmatch)
搜索:第一个匹配了我就返回了,因为搜索到了
查找:必须找到全部匹配的,因为是查找,必须搞清有多少个
5、修饰符
m = re.match("A", "a", re.I)
print(m)
# 输出
# <_sre.SRE_Match object; span=(0, 1), match='a'>
# re.I是正则表达式的额外匹配策略,I表示ignore忽略大小写进行匹配
m = re.match(".", "\n", re.S)
print(m)
# <_sre.SRE_Match object; span=(0, 1), match='\n'>
# 结论:re.S使得.号可以匹配换行符
m = re.search("^X", "A\nB\nX", re.MULTILINE)
print(m)
# 输出
# <_sre.SRE_Match object; span=(4, 5), match='X'>
# 表面看上去X是在字符串中间,不是在开头,所以^X无法匹配,但是因为`re.MULTILINE`导致^去匹配每一行的开头,而非整个字符串开头
总结
本文仅仅简单介绍了正则表达式的基础用法,然后结合python编程语言的re模块举了几个例子。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









