







索引支持在MongoDB中高效执行查询。如果没有索引,MongoDB必须执行集合扫描,即扫描集合中的每个文档,以选择那些匹配查询语句的文档。如果查询存在适当的索引,MongoDB可以使用该索引来限制它必须检查的文档数量。
索引是一种特殊的数据结构[1],它以一种易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段的值排序。索引项的排序支持高效的相等匹配和基于范围的查询操作。另外,MongoDB可以使用索引中的排序返回排序后的结果。
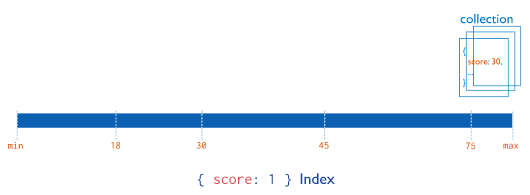
下图演示了使用索引选择和排序匹配文档的查询:

从根本上说,MongoDB中的索引与其他数据库系统中的索引类似。MongoDB在集合级别定义索引,并支持MongoDB集合中文档的任何字段或子字段上的索引。
1.默认_id指数
在创建集合期间,MongoDB在_id字段上创建一个惟一的索引。_id索引防止客户机为_id字段插入两个具有相同值的文档。您不能在_id字段上删除此索引。
请注意:
在分片集群中,如果不使用_id字段作为分片键,则应用程序必须确保_id字段中值的唯一性,以防止错误。这通常是通过使用标准的自动生成的ObjectId来实现的。
2.生成一个索引
Mongo Shell
要在Mongo Shell中创建索引,请使用db.collection.createIndex()。
db.collection.createIndex( <key and index type specification>, <options> )下面的示例在name字段上创建一个键降序索引:
db.collection.createIndex( { name: -1 } )db.collection.createIndex方法只在相同规范的索引不存在的情况下创建索引。
Java(Sync)
要使用Java驱动程序创建索引,请使用com.mongodb.client.MongoCollection.createIndex。
collection.createIndex( <key and index type specification>, <options> )下面的示例在name字段上创建一个键降序索引:
collection.createIndex(Indexes.descending("name"));com.mongodb.client.MongoCollection.createIndex.method仅在同一规范的索引不存在的情况下创建索引。
2.1 索引名称
索引的默认名称是使用下划线作为分隔符的索引键和索引中每个键的方向(即1或-1)的连接。例如,在{item: 1, quantity: -1}上创建的索引名为item_1_quantity_1。
您可以创建具有自定义名称的索引,例如比默认名称更易于阅读的索引。例如,考虑一个经常查询产品集合以填充现有库存数据的应用程序。下面的createIndex()方法为库存创建一个名为query的项目和数量索引:
db.products.createIndex(
{ item: 1, quantity: -1 } ,
{ name: "query for inventory" }
)可以使用db.collection.getIndexes()方法查看索引名。创建索引后不能重命名。相反,您必须删除并使用新名称重新创建索引。
3. 索引类型
MongoDB提供了许多不同的索引类型来支持特定类型的数据和查询。
3.1单个字段
除了MongoDB定义的_id索引之外,MongoDB还支持在文档的单个字段上创建用户定义的升序/降序索引。
对于单字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以按任意方向遍历索引。
3.2 复合索引
MongoDB还支持用户在多个字段上定义索引,即复合索引。
复合索引中列出字段的顺序具有显著性。例如,如果一个复合索引包含{userid: 1, score: -1},那么该索引首先按userid排序,然后在每个userid值内按分数排序。

对于复合索引和排序操作,索引键的排序顺序(即升序或降序)可以决定索引是否支持排序操作。有关索引顺序对复合索引结果影响的更多信息,请参见排序顺序。
3.3 多键索引
MongoDB使用多键索引来索引数组中存储的内容。如果索引一个包含数组值的字段,MongoDB会为数组的每个元素创建单独的索引项。这些多键索引允许查询通过匹配一个或多个数组元素来选择包含数组的文档。MongoDB自动决定是否创建一个多键索引,如果索引字段包含一个数组值;您不需要显式地指定多密钥类型。

3.4地理空间索引
为了支持对地理空间坐标数据的高效查询,MongoDB提供了两个特殊的索引:在返回结果时使用平面几何的2d索引和使用球面几何返回结果的2dsphere索引。
3.5文本索引
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”),并对集合中的单词进行词干处理,只存储根单词。
3.6散列索引
为了支持基于哈希的分片,MongoDB提供了一个散列索引类型,用于索引字段值的散列。这些索引的值在其范围内的分布更加随机,但是只支持相等匹配,不支持基于范围的查询。
4.指标特性
4.1唯一索引
索引的惟一属性导致MongoDB拒绝索引字段的重复值。除了unique约束之外,unique索引在功能上可以与其他MongoDB索引互换。
4.2部分指标
新版本3.2。
只对满足指定筛选器表达式的集合中的文档进行部分索引。通过为集合中的一个文档子集建立索引,部分索引具有更低的存储需求,并降低了索引创建和维护的性能成本。
部分索引提供了稀疏索引功能的超集,应该优先于稀疏索引。
4.3稀疏索引
索引的稀疏属性确保索引只包含具有索引字段的文档的条目。索引跳过没有索引字段的文档。
可以将稀疏索引选项与惟一索引选项组合使用,以防止插入具有重复索引字段值的文档,并跳过缺少索引字段的索引文档。
4.4TTL索引
TTL索引是特殊的索引,MongoDB可以使用它在一段时间后自动从集合中删除文档。这对于某些类型的信息非常理想,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
5.索引使用
索引可以提高读取操作的效率。分析查询性能教程提供了一个带有和不带有索引的查询执行统计数据的示例。
6.索引和排序
新版本3.4。
排序规则允许用户为字符串比较指定特定于语言的规则,例如针对lettercase和重音符号的规则。
Mongo Shell
若要为字符串比较使用索引,操作还必须指定相同的排序规则。也就是说,如果具有排序规则的索引指定了不同的排序规则,则不支持对索引字段执行字符串比较的操作。
例如,集合myColl在排序区域设置为“fr”的字符串字段类别上有一个索引。
db.myColl.createIndex( { category: 1 }, { collation: { locale: "fr" } } )下面的查询操作指定了与索引相同的排序规则,可以使用索引:
db.myColl.find( { category: "cafe" } ).collation( { locale: "fr" } )但是,下面的查询操作,在默认情况下使用“简单”的二进制排序器,不能使用索引:
db.myColl.find( { category: "cafe" } )对于索引前缀键不是字符串、数组和嵌入文档的复合索引,指定不同排序规则的操作仍然可以使用索引来支持对索引前缀键的比较。
例如,集合myColl在数值字段score和price以及字符串字段类别上有一个复合索引;索引是用排序区域设置“fr”创建的,用于字符串比较:
db.myColl.createIndex(
{ score: 1, price: 1, category: 1 },
{ collation: { locale: "fr" } } )以下操作使用“简单”的二进制排序规则进行字符串比较,可以使用索引:
db.myColl.find( { score: 5 } ).sort( { price: 1 } )
db.myColl.find( { score: 5, price: { $gt: NumberDecimal( "10" ) } } ).sort( { price: 1 } )下面的操作使用“简单”的二进制排序规则对索引的类别字段进行字符串比较,可以使用该索引仅满足分数:查询的5部分:
db.myColl.find( { score: 5, category: "cafe" } )以下索引只支持简单的二进制比较,不支持排序:
- 文本索引,
- 2d索引和
- geoHaystack索引。
7.覆盖查询
当查询条件和查询的投影只包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档放入内存。这些查询可能非常有效。

8.指数的十字路口
MongoDB可以使用索引的交集来实现查询。对于指定复合查询条件的查询,如果一个索引可以满足查询条件的一部分,而另一个索引可以满足查询条件的另一部分,那么MongoDB可以使用两个索引的交集来满足查询。使用复合索引还是使用索引交集更有效取决于特定的查询和系统。
9.限制
某些限制适用于索引,如索引键的长度或每个集合的索引数量。有关详细信息,请参见索引限制。
10.额外的注意事项
虽然索引可以提高查询性能,但是索引也提供了一些操作方面的考虑。有关更多信息,请参见索引的操作注意事项。
应用程序在构建索引时可能会遇到性能下降,包括对集合的读写访问受限。有关索引构建过程的更多信息,请参见已填充集合的索引构建,包括复制环境中的索引构建部分。
一些驱动程序可能指定索引,使用NumberLong(1)而不是1作为规范。这对结果索引没有任何影响。
一、单字段索引
MongoDB提供了对文档集合中任何字段上的索引的完整支持。默认情况下,所有集合在_id字段上都有一个索引,应用程序和用户可以添加额外的索引来支持重要的查询和操作。
本文档描述单个字段上的升序/降序索引。

1.在单个字段上创建升序索引
考虑一个名为records的集合,其中包含类似以下示例文档的文档:
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}下面的操作在记录收集的score字段上创建一个升序索引:
db.records.createIndex( { score: 1 } )索引规范中的字段值描述了该字段的索引类型。例如,值1指定按升序排列项目的索引。值-1指定按降序排列项目的索引。有关其他索引类型,请参见索引类型。
创建的索引将支持查询,选择字段得分,如以下:
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )2.在嵌入字段上创建索引
可以在嵌入文档的字段上创建索引,就像可以在文档中索引顶级字段一样。嵌入字段上的索引与嵌入文档上的索引不同,后者包括索引中嵌入文档的最大索引大小的完整内容。相反,嵌入字段上的索引允许您使用“点表示法”来内省到嵌入的文档中。
考虑一个名为records的集合,其中包含类似以下示例文档的文档:
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}下面的操作在位置上创建一个索引。状态:
db.records.createIndex( { "location.state": 1 } )创建的索引将支持在字段位置上选择的查询。状态,如以下:
db.records.find( { "location.state": "CA" } )
db.records.find( { "location.city": "Albany", "location.state": "NY" } )3.在嵌入的文档上创建索引
您还可以在整个嵌入式文档上创建索引。
考虑一个名为records的集合,其中包含类似以下示例文档的文档:
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}location字段是一个嵌入的文档,包含嵌入的字段city和state。下面的命令在location字段上创建一个完整的索引:
db.records.createIndex( { location: 1 } )以下查询可以使用location字段上的索引:
db.records.find( { location: { city: "New York", state: "NY" } } )请注意:
虽然查询可以使用索引,但是结果集不包括上面的示例文档。当对嵌入的文档执行相等匹配时,字段顺序很重要,并且嵌入的文档必须精确匹配。有关查询嵌入式文档的更多信息,请参见查询嵌入式文档。
4.额外的注意事项
应用程序在构建索引时可能会遇到性能下降,包括对集合的读写访问受限。有关索引构建过程的更多信息,请参见已填充集合的索引构建,包括复制环境中的索引构建部分。
一些驱动程序可能指定索引,使用NumberLong(1)而不是1作为规范。这对结果索引没有任何影响。
二、复合索引
MongoDB支持复合索引,其中单个索引结构保存对集合文档中多个字段[1]的引用。下图展示了两个字段的复合索引示例:

[1] mongodb对任何复合索引施加32个字段的限制。
复合索引可以支持在多个字段上匹配的查询。
1.创建一个复合索引
要创建复合索引,请使用类似以下原型的操作:
db.collection.createIndex( { <field1>: <type>, <field2>: <type2>, ... } )索引规范中的字段值描述了该字段的索引类型。例如,值1指定按升序排列项目的索引。值-1指定按降序排列项目的索引。有关其他索引类型,请参见索引类型。
重要的:
不能创建具有散列索引类型的复合索引。如果试图创建包含散列索引字段的复合索引,则会收到一个错误。
考虑一个名为products的集合,其中包含类似于以下文档的文档:
{
"_id": ObjectId(...),
"item": "Banana",
"category": ["food", "produce", "grocery"],
"location": "4th Street Store",
"stock": 4,
"type": "cases"
}下面的操作在item和stock字段上创建一个升序索引:
db.products.createIndex( { "item": 1, "stock": 1 } )复合索引中列出的字段的顺序很重要。索引将包含对文档的引用,这些文档首先按项目字段的值排序,然后在项目字段的每个值内按股票字段的值排序。有关更多信息,请参见排序顺序。
除了支持在所有索引字段上匹配的查询外,复合索引还可以支持在索引字段的前缀上匹配的查询。也就是说,该索引支持对item字段以及item和stock字段的查询:
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana", stock: { $gt: 5 } } )2.排序顺序
索引以升序(1)或降序(-1)的顺序存储对字段的引用。对于单字段索引,键的排序顺序并不重要,因为MongoDB可以在任意方向遍历索引。但是,对于复合索引,排序顺序在决定索引是否支持排序操作时很重要。
考虑一个集合事件,其中包含字段为username和date的文档。应用程序可以发出查询,查询返回的结果按升序用户名值排序,然后按降序(即从最近到最后)日期值排序,如:
db.events.find().sort( { username: 1, date: -1 } )或者返回按用户名降序排序然后按日期升序排序的结果的查询,例如:
db.events.find().sort( { username: -1, date: 1 } )下面的索引可以支持这两种排序操作:
db.events.createIndex( { "username" : 1, "date" : -1 } )但是,上面的索引不支持按升序用户名值排序,然后按升序日期值排序,例如:
db.events.find().sort( { username: 1, date: 1 } )3.前缀
索引前缀是索引字段的起始子集。例如,考虑以下复合索引:
{ "item": 1, "location": 1, "stock": 1 }索引有以下索引前缀:
{ item: 1 }{ item: 1, location: 1 }
对于复合索引,MongoDB可以使用索引来支持对索引前缀的查询。因此,MongoDB可以对以下字段使用索引查询:
- 项目字段、
- 项目字段和位置字段、
- 项目字段和位置字段和股票字段。
MongoDB还可以使用索引来支持对item和stock字段的查询,因为item字段对应一个前缀。但是,在支持查询方面,索引的效率不如仅针对项和股票的索引。
但是,MongoDB不能使用索引来支持包含以下字段的查询,因为没有item字段,列出的字段都不对应于前缀索引:
- 位置字段、
- 股票字段或
- 位置和股票字段。
如果你有一个集合,复合索引和索引的前缀(例如:{1,b: 1}和{:1}),如果指数都没有稀疏或唯一约束,那么你可以删除索引的前缀(例如{:1})。MongoDB将在所有使用前缀索引的情况下使用复合索引。
4.指数的十字路口
从2.6版开始,MongoDB可以使用index intersection来实现查询。创建支持查询的复合索引还是依赖于索引交集,这取决于系统的具体情况。有关详细信息,请参阅索引交集和复合索引。
5.其他注意事项
构建索引时可能会遇到性能下降,包括对集合的读写访问受限。有关索引构建过程的更多信息,请参见已填充集合的索引构建,包括复制环境中的索引构建部分。
一些驱动程序可能指定索引,使用NumberLong(1)而不是1作为规范。这对结果索引没有任何影响。
三、多值索引
要索引包含数组值的字段,MongoDB为数组中的每个元素创建一个索引键。这些多键索引支持对数组字段的高效查询。多键索引可以在数组上构造,数组包含标量值[1](例如字符串、数字)和嵌套文档。

[1]标量值是指既不是嵌入文档也不是数组的值。
1.创建多键索引
要创建多键索引,请使用db.collection.createIndex()方法:
db.coll.createIndex( { <field>: < 1 or -1 > } )如果任何索引字段是一个数组,MongoDB会自动创建一个多键索引;您不需要显式地指定多密钥类型。
3.4版本的变化:仅针对WiredTiger和内存存储引擎,
从MongoDB 3.4开始,对于使用MongoDB 3.4或更高版本创建的多键索引,MongoDB跟踪哪个索引字段或哪些字段导致索引成为多键索引。通过跟踪这些信息,MongoDB查询引擎可以使用更严格的索引限制。
2.指数范围
如果一个索引是多键的,那么索引边界的计算遵循特殊的规则。有关多键索引边界的详细信息,请参阅多键索引边界。
3.唯一的多键索引
对于惟一索引,惟一约束适用于集合中不同的文档,而不是单个文档。
因为惟一约束适用于单独的文档,对于惟一的多键索引,只要文档的索引键值不重复另一个文档的索引键值,文档就可能有导致重复索引键值的数组元素。
4.限制
4.1复合多键索引
对于复合多键索引,每个索引文档最多只能有一个索引字段,其值是一个数组。那就是:
- 如果文档中有多个要索引的字段是数组,则不能创建复合多键索引。例如,考虑一个包含以下文档的集合:
{ _id: 1, a: [ 1, 2 ], b: [ 1, 2 ], category: "AB - both arrays" }不能在集合上创建复合多键索引{a: 1, b: 1},因为a和b字段都是数组。
- 或者,如果已经存在复合多键索引,则不能插入违反此限制的文档。考虑一个包含以下文档的集合:
{ _id: 1, a: [1, 2], b: 1, category: "A array" }
{ _id: 2, a: 1, b: [1, 2], category: "B array" }允许使用复合多键索引{A: 1, b: 1},因为对于每个文档,只有一个由复合多键索引索引的字段是数组;也就是说,没有文档包含a和b字段的数组值。
但是,在创建复合多键索引之后,如果您试图插入一个a和b字段都是数组的文档,MongoDB将无法插入。
如果一个字段是一个文档数组,您可以为嵌入的字段建立索引,以创建复合索引。例如,考虑一个包含以下文档的集合:
{ _id: 1, a: [ { x: 5, z: [ 1, 2 ] }, { z: [ 1, 2 ] } ] }
{ _id: 2, a: [ { x: 5 }, { z: 4 } ] }可以在{"a "上创建复合索引。x”: 1、“。z”: 1}。最多一个索引字段可以是一个数组的限制也适用。
4.2排序
由于在MongoDB 3.6中对数组字段的排序行为的改变,当对一个用多键索引索引的数组进行排序时,查询计划包括一个阻塞排序阶段。新的排序行为可能会对性能产生负面影响。
在阻塞排序中,排序步骤必须消耗所有输入,然后才能产生输出。在非阻塞或索引排序中,排序步骤扫描索引以按请求的顺序产生结果。
4.3 Shard Keys
不能将多键索引指定为碎片键索引。
但是,如果碎片键索引是一个复合索引的前缀,那么如果其他键(即不属于碎片键的键)中的一个索引是一个数组,则复合索引可以成为一个复合多键索引。复合多键索引会影响性能。
4.4 散列索引
散列索引不能是多键的。
4.5覆盖查询
多键索引不能覆盖数组字段上的查询。
但是,从3.6开始,如果索引跟踪导致索引为多键的字段,多键索引可以覆盖非数组字段的查询。在MongoDB 3.4或更高版本的存储引擎上创建的多键索引(MMAPv1[#]_)跟踪这些数据。
[2]从4.2版本开始,MongoDB删除了不支持的MMAPv1存储引擎。
4.6 查询整个数组字段
当查询过滤器为整个数组指定精确匹配时,MongoDB可以使用多键索引来查找查询数组的第一个元素,但不能使用多键索引扫描来查找整个数组。相反,在使用多键索引查找查询数组的第一个元素之后,MongoDB检索关联的文档,并筛选其数组与查询中的数组匹配的文档。
例如,考虑一个包含以下文档的库存集合:
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] }
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] }
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] }
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] }
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ] }集合在评级字段上有一个多键索引:
db.inventory.createIndex( { ratings: 1 } )下面的查询查找评级字段为数组[5,9]的文档:MongoDB可以使用多键索引来查找评级数组中任意位置有5个键的文档。然后,MongoDB检索这些文档并过滤其评级数组等于查询数组的文档[5,9]。
4.7$expr
$expr不支持多键索引。
5. 例子
指数基本数组
考虑使用以下文件收集调查:
{ _id: 1, item: "ABC", ratings: [ 2, 5, 9 ] }在现场评级上创建一个索引:
db.survey.createIndex( { ratings: 1 } )因为ratings字段包含一个数组,所以ratings上的索引是多键的。multikey索引包含以下三个索引键,每个都指向同一个文档:
2,5, and9.
5.1嵌入文档的索引数组
可以在包含嵌套对象的数组字段上创建多键索引。
考虑以下列形式的文件收集存货:
{
_id: 1,
item: "abc",
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
}
{
_id: 2,
item: "def",
stock: [
{ size: "S", color: "blue", quantity: 20 },
{ size: "M", color: "blue", quantity: 5 },
{ size: "M", color: "black", quantity: 10 },
{ size: "L", color: "red", quantity: 2 }
]
}
{
_id: 3,
item: "ijk",
stock: [
{ size: "M", color: "blue", quantity: 15 },
{ size: "L", color: "blue", quantity: 100 },
{ size: "L", color: "red", quantity: 25 }
]
}
...下面的操作在股票上创建一个多键索引。大小和股票。数量字段:
db.inventory.createIndex( { "stock.size": 1, "stock.quantity": 1 } )复合多键索引可以支持包含两个索引字段的谓词的查询,也可以支持只包含索引前缀“stock”的谓词的查询。,例如:
db.inventory.find( { "stock.size": "M" } )
db.inventory.find( { "stock.size": "S", "stock.quantity": { $gt: 20 } } )有关MongoDB如何组合多键索引边界的详细信息,请参阅多键索引边界。有关复合索引和前缀的行为的更多信息,请参见复合索引和前缀。
复合多键索引也可以支持排序操作,例如:
db.inventory.find( ).sort( { "stock.size": 1, "stock.quantity": 1 } )
db.inventory.find( { "stock.size": "M" } ).sort( { "stock.quantity": 1 } )四.多键索引范围
索引扫描的范围定义了在查询期间要搜索的索引部分。当一个索引上存在多个谓词时,MongoDB将尝试通过交叉或组合组合这些谓词的边界,以产生一个具有更小边界的扫描。
1.多键索引的相交边界
边界相交指的是多个边界的逻辑连接(即AND)。例如,给定两个界限[[3,∞]]和[[-∞,6]],界限的交集产生[[3,6]]。
给定一个索引数组字段,考虑一个查询,该查询指定数组上的多个谓词,并且可以使用一个多键索引。如果$elemMatch加入谓词,MongoDB可以交叉多键索引边界。
例如,一个集合调查包含一个字段项和一个数组字段评级的文档:
{ _id: 1, item: "ABC", ratings: [ 2, 9 ] }
{ _id: 2, item: "XYZ", ratings: [ 4, 3 ] }在评级数组上创建一个多键索引:
db.survey.createIndex( { ratings: 1 } )下面的查询使用$elemMatch要求数组至少包含一个匹配这两个条件的元素:
db.survey.find( { ratings : { $elemMatch: { $gte: 3, $lte: 6 } } } )单独使用谓词:
- 大于或等于3谓词(即$gte: 3)的界限是[[3,∞]];
- 小于或等于6的谓词(即$lte: 6)的界限是[[-∞,6]]。
因为查询使用$elemMatch来连接这些谓词,所以MongoDB可以将边界相交到:
ratings: [ [ 3, 6 ] ]查询在评级数组中搜索至少一个大于或等于3的元素和至少一个小于或等于6的元素。因为单个元素不需要同时满足两个条件,所以MongoDB不相交边界,使用[[3,Infinity]]或[[-Infinity, 6]]。MongoDB不能保证它选择这两个边界中的哪一个。
2.多键索引的复合边界
复合边界是指对复合索引的多个键使用边界。例如,给定一个复合索引{a: 1, b: 1},其a字段上的界限为[[3,∞]],b字段上的界限为[[-∞,6]],复合这些界限会导致两个界限的使用:
{ a: [ [ 3, Infinity ] ], b: [ [ -Infinity, 6 ] ] }如果MongoDB不能复合这两个界限,MongoDB总是通过它的前导字段上的界限来约束索引扫描,在这种情况下,a: [[3, Infinity]]。
2.1数组字段上的复合索引
考虑一个复合多键索引;一个复合索引,其中一个索引字段是一个数组。例如,一个集合调查包含一个字段项和一个数组字段评级的文档:
{ _id: 1, item: "ABC", ratings: [ 2, 9 ] }
{ _id: 2, item: "XYZ", ratings: [ 4, 3 ] }在项目字段和评级字段上创建一个复合索引:
db.survey.createIndex( { item: 1, ratings: 1 } )下面的查询在索引的两个键上指定了一个条件:
db.survey.find( { item: "XYZ", ratings: { $gte: 3 } } )单独使用谓词:
- 项目的界限:“XYZ”谓词是[[“XYZ”,“XYZ”]];
- 额定值:{$gte: 3}谓词的界限是[[3,∞]]。
MongoDB可以复合这两个边界,使用组合边界:
{ item: [ [ "XYZ", "XYZ" ] ], ratings: [ [ 3, Infinity ] ] }2.2 标量索引字段上的范围查询(WiredTiger)
3.4版本的变化:仅针对WiredTiger和内存存储引擎,
从MongoDB 3.4开始,对于使用MongoDB 3.4或更高版本创建的多键索引,MongoDB跟踪哪个索引字段或哪些字段导致索引成为多键索引。通过跟踪这些信息,MongoDB查询引擎可以使用更严格的索引限制。
上述复合索引是在标量字段[1]项和数组字段评级:
db.survey.createIndex( { item: 1, ratings: 1 } )对于WiredTiger和内存存储引擎,如果查询操作在MongoDB 3.4或更高版本中创建的复合多键索引的索引标量字段上指定多个谓词,则MongoDB将与该字段的边界相交。
例如,以下操作指定标量字段上的范围查询以及数组字段上的范围查询:
db.survey.find( {
item: { $gte: "L", $lte: "Z"}, ratings : { $elemMatch: { $gte: 3, $lte: 6 } }
} )MongoDB将相交项目的界限为[["L", "Z"]],评级为[[3.0,6.0]],使用的组合界限为:
"item" : [ [ "L", "Z" ] ], "ratings" : [ [3.0, 6.0] ]对于另一个示例,考虑标量字段属于嵌套文档的何处。例如,一个收集调查包含以下文件:
{ _id: 1, item: { name: "ABC", manufactured: 2016 }, ratings: [ 2, 9 ] }
{ _id: 2, item: { name: "XYZ", manufactured: 2013 }, ratings: [ 4, 3 ] }在标量字段“item.name”、“item”上创建复合多键索引。和阵列现场评级:
db.survey.createIndex( { "item.name": 1, "item.manufactured": 1, ratings: 1 } )考虑以下在标量字段上指定查询谓词的操作:
db.survey.find( {
"item.name": "L" ,
"item.manufactured": 2012
} )对于这个查询,MongoDB可以使用以下的组合边界:
"item.name" : [ ["L", "L"] ], "item.manufactured" : [ [2012.0, 2012.0] ]MongoDB的早期版本不能组合标量字段的这些边界。
[1]标量字段是其值既不是文档也不是数组的字段;例如,值为字符串或整数的字段是标量字段。
只要字段本身不是数组或文档,则标量字段可以是嵌套在文档中的字段。例如,在文档{a: {b: {c: 5, d: 5}}中,c和d是标量字段,而a和b不是。
2.3 对嵌入文档数组中的字段进行复合索引
如果数组包含嵌入式文档,要对嵌入式文档中包含的字段建立索引,请使用索引规范中的点字段名。例如,给定以下嵌入文档的数组:
ratings: [ { score: 2, by: "mn" }, { score: 9, by: "anon" } ]score字段的点字段名是“ratings.score”。
2.4 非数组字段和数组字段的复合边界
考虑一个collection survey2包含一个字段项和一个数组字段评级的文档:
{
_id: 1,
item: "ABC",
ratings: [ { score: 2, by: "mn" }, { score: 9, by: "anon" } ]
}
{
_id: 2,
item: "XYZ",
ratings: [ { score: 5, by: "anon" }, { score: 7, by: "wv" } ]
}为非数组字段项以及来自数组额定值的两个字段创建复合索引。分数和ratings.by:
db.survey2.createIndex( { "item": 1, "ratings.score": 1, "ratings.by": 1 } )下面的查询指定了三个字段的条件:
db.survey2.find( { item: "XYZ", "ratings.score": { $lte: 5 }, "ratings.by": "anon" } )单独使用谓词:
- 项目的界限:“XYZ”谓词是[[“XYZ”,“XYZ”]];
- 分数的界限:{$lte: 5}谓词是[[-∞,5]];
- by: "anon"谓词的界限是["anon", "anon"]。
MongoDB可以将项目键的界限与“评级”的界限结合起来。评分或评分的界限。通过“,取决于查询谓词和索引键值。MongoDB不保证它与item字段复合的边界。例如,MongoDB将选择将项目边界与“评级”组合在一起。分数”界限:
{
"item" : [ [ "XYZ", "XYZ" ] ],
"ratings.score" : [ [ -Infinity, 5 ] ],
"ratings.by" : [ [ MinKey, MaxKey ] ]
}或者,MongoDB可以选择将项目边界与“额定值”组合在一起。通过“界限:
{
"item" : [ [ "XYZ", "XYZ" ] ],
"ratings.score" : [ [ MinKey, MaxKey ] ],
"ratings.by" : [ [ "anon", "anon" ] ]
}然而,复合的界限为“评级”。得分“与界限”评级。通过“”,查询必须使用$elemMatch。有关更多信息,请参见数组中索引字段的复合边界。
2.5数组中索引字段的复合边界
复合边界的索引键从相同的数组:
- 索引键必须共享相同的字段路径,但不包括字段名,
- 查询必须使用该路径上的$elemMatch指定字段上的谓词。
对于嵌入文档中的字段,请使用点字段名,如“a.b.c”。d”,是d的字段路径。要复合来自相同数组的索引键的边界,$elemMatch必须位于但不包括字段名称本身的路径上;即。“a.b.c”。
例如,在评级上创建一个复合索引。评分和评分。字段:
db.survey2.createIndex( { "ratings.score": 1, "ratings.by": 1 } )字段”评级。分数”和“评级。通过“分享字段路径评级”。下面的查询在字段评级上使用$elemMatch,要求数组至少包含一个匹配这两种情况的元素:
db.survey2.find( { ratings: { $elemMatch: { score: { $lte: 5 }, by: "anon" } } } )单独使用谓词:
- 分数的界限:{$lte: 5}谓词是[-Infinity, 5];
- by: "anon"谓词的界限是["anon", "anon"]。
MongoDB可以复合这两个边界,使用组合边界:
{ "ratings.score" : [ [ -Infinity, 5 ] ], "ratings.by" : [ [ "anon", "anon" ] ] }2.6 查询没有elemMatch美元
如果查询没有使用$elemMatch连接索引数组字段上的条件,MongoDB就不能复合它们的边界。考虑以下查询:
db.survey2.find( { "ratings.score": { $lte: 5 }, "ratings.by": "anon" } )因为数组中的单个嵌入文档不需要满足这两个条件,所以MongoDB没有复合边界。在使用复合索引时,如果MongoDB不能约束索引的所有字段,MongoDB总是约束索引的前导字段,在这种情况下“ratings.score”:
{
"ratings.score": [ [ -Infinity, 5 ] ],
"ratings.by": [ [ MinKey, MaxKey ] ]
}2.7 不完整路径上的$elemMatch
如果查询没有在嵌入字段的路径上指定$elemMatch,直到但不包括字段名,MongoDB就不能从相同的数组中复合索引键的边界。
例如,一个collection survey3包含一个字段项和一个数组字段评级的文档:
{
_id: 1,
item: "ABC",
ratings: [ { scores: [ { q1: 2, q2: 4 }, { q1: 3, q2: 8 } ], loc: "A" },
{ scores: [ { q1: 2, q2: 5 } ], loc: "B" } ]
}
{
_id: 2,
item: "XYZ",
ratings: [ { scores: [ { q1: 7 }, { q1: 2, q2: 8 } ], loc: "B" } ]
}在ratings.scores.q1上创建一个复合索引和ratings.scores.q2 :
db.survey3.createIndex( { "ratings.scores.q1": 1, "ratings.scores.q2": 1 } )ratings.scores.q1字段和"ratings.scores.q2" 分享球场路径”评级。而$elemMatch必须在该路径上。
但是,下面的查询使用了$elemMatch,但不在所需的路径上:
db.survey3.find( { ratings: { $elemMatch: { 'scores.q1': 2, 'scores.q2': 8 } } } )因此,MongoDB不能复合边界和“ratings.scores.q2”字段将在索引扫描期间不受约束。要复合边界,查询必须使用“ratings.scores”路径上的$elemMatch:
db.survey3.find( { 'ratings.scores': { $elemMatch: { 'q1': 2, 'q2': 8 } } } )五、全文索引
1.概述
MongoDB提供文本索引来支持对字符串内容的文本搜索查询。文本索引可以包含值为字符串或字符串元素数组的任何字段。
Versions
text Index Version | Description |
|---|---|
| Version 3 | MongoDB引入了文本索引的版本3。版本3是在MongoDB 3.2及以后版本中创建的文本索引的默认版本。 |
| Version 2 | MongoDB 2.6引入了文本索引的版本2。版本2是在MongoDB 2.6和3.0系列中创建的文本索引的默认版本。 |
| Version 1 | MongoDB 2.4引入了文本索引的版本1。MongoDB 2.4只能支持版本1。 |
要覆盖默认版本并指定一个不同的版本,在创建索引时包括选项{"textIndexVersion": <version>}。
2.创建文本索引
重要的:
一个集合最多可以有一个文本索引。
要创建文本索引,请使用db.collection.createIndex()方法。若要索引包含字符串或字符串元素数组的字段,请在索引文档中包含该字段并指定字符串文字“text”,如下面的示例所示:
db.reviews.createIndex( { comments: "text" } )可以为文本索引建立多个字段的索引。下面的例子在字段subject和comments上创建了一个文本索引:
db.reviews.createIndex(
{
subject: "text",
comments: "text"
}
)复合索引可以包含文本索引键和升序/降序索引键。有关更多信息,请参见复合索引。
要删除文本索引,请使用索引名。有关更多信息,请参见使用索引名删除文本索引。
2.1 指定权重
对于文本索引,索引字段的权重表示该字段相对于其他索引字段在文本搜索得分方面的重要性。
对于文档中的每个索引字段,MongoDB将匹配项的数量乘以权重并对结果求和。使用这个总和,MongoDB然后计算文档的分数。查看$meta操作符获取关于返回和按文本分数排序的详细信息。
索引字段的默认权重为1。要调整索引字段的权重,请在db.collection.createIndex()方法中包含weights选项。
有关使用权重控制文本搜索结果的更多信息,请参见使用权重控制搜索结果。
2.2 通配符文本索引
请注意:
通配符文本索引不同于通配符索引。通配符索引不能使用$text操作符支持查询。
虽然通配符文本索引和通配符索引共享通配符$**字段模式,但它们是不同的索引类型。只有通配符文本索引支持$ Text操作符。
在多个字段上创建文本索引时,还可以使用通配符说明符($**)。使用通配符文本索引,MongoDB为集合中每个文档包含字符串数据的每个字段建立索引。下面的示例使用通配符说明符创建文本索引:
db.collection.createIndex( { "$**": "text" } )该索引允许对所有包含字符串内容的字段进行文本搜索。对于高度非结构化的数据,如果不清楚文本索引中应该包含哪些字段或用于特殊查询,那么这种索引可能非常有用。
通配符文本索引是多个字段上的文本索引。因此,您可以在创建索引时为特定字段分配权重,以控制结果的排名。有关使用权重控制文本搜索结果的更多信息,请参见使用权重控制搜索结果。
与所有文本索引一样,通配符文本索引可以是复合索引的一部分。例如,下面的代码在字段a上创建了一个复合索引以及通配符说明符:
db.collection.createIndex( { a: 1, "$**": "text" } )与所有复合文本索引一样,由于a在文本索引键之前,因此要使用此索引执行$text搜索,查询谓词必须包含相等匹配条件a。有关复合文本索引的信息,请参见复合文本索引。
3.不区分大小写
在3.2版本中进行了更改。
version 3文本索引支持通用的C、简单的S,对于土耳其语言,支持Unicode 8.0字符数据库大小写折叠中指定的特殊的T大小写折叠。
此案的褶皱扩展文本索引包括字符不区分大小写的区分标志,如e和e,从非拉丁字母和字符,如“И”和“и”西里尔字母。
版本3的文本索引也是变音符不敏感的。同样,指数也不区分 é, É, e, and E.
以前版本的文本索引只对[A-z]不区分大小写;例如,大小写不敏感的非变音符拉丁字符。对于所有其他字符,早期版本的文本索引将它们视为不同的。
4.可区别的不敏感
在3.2版本中进行了更改。
在版本3中,文本索引对变音符不敏感。也就是说,索引不区分包含变音符号的字符和没有标记的对应字符,比如e、e和e。更具体地说,文本索引将Unicode 8.0字符数据库支持列表中归类为变音符号的字符去除。
文本索引的版本3也不区分大小写。同样,指数也不区分 é, É, e, and E。
以前版本的文本索引将带变音符号的字符视为不同的。
5.标记分隔符
在3.2版本中进行了更改。
对于标记化,version 3文本索引使用Unicode 8.0字符数据库支持列表中的分隔符,这些分隔符分类在Dash、连字符、Pattern_Syntax、Quotation_Mark、terminal_和White_Space之下。
例如,如果给定一个字符串“Il a dit qu'il«etait le meilleur joueur du monde»”,文本索引将«、»和空格作为分隔符。
以前的索引版本将«作为术语“«etait”的一部分,»作为术语“monde»”的一部分。
6. 索引项
文本索引对索引项的索引字段中的术语进行标记和词干处理。文本索引为集合中每个文档的每个索引字段中的每个惟一词干项存储一个索引项。索引使用简单的特定于语言的后缀词干。
7.支持语言和停止文字
MongoDB支持各种语言的文本搜索。文本索引删除特定于语言的停止词(例如,在英语中,the, an, a, and等),并使用简单的特定于语言的后缀词干。有关受支持语言的列表,请参阅文本搜索语言。
如果您指定的语言值为“none”,那么文本索引将使用简单的标记,没有停止词列表,也没有词干提取。
若要为文本索引指定语言,请参见为文本索引指定语言。
8.稀疏特性(sparse Property)
文本索引总是稀疏的,忽略稀疏选项。如果文档缺少文本索引字段(或者字段为null或空数组),MongoDB不会将文档条目添加到文本索引中。对于插入,MongoDB插入文档,但不添加到文本索引。
对于包含文本索引键和其他类型键的复合索引,只有文本索引字段确定索引是否引用文档。其他键不确定索引是否引用文档。
9.限制
每个集合一个文本索引
一个集合最多可以有一个文本索引。
文本搜索和提示
如果查询包含$text查询表达式,则不能使用hint()。
文本索引和排序
排序操作无法从文本索引获取排序顺序,即使是从复合文本索引;例如,排序操作不能使用文本索引中的排序。
复合索引
复合索引可以包含文本索引键和升序/降序索引键。但是,这些复合指数有以下限制:
- 复合文本索引不能包含任何其他特殊索引类型,如多键或地理空间索引字段。
- 如果复合文本索引包含在文本索引键之前的键,则要执行$text搜索,查询谓词必须包含在前面键上的相等匹配条件。
- 在创建复合文本索引时,所有文本索引键必须在索引规范文档中邻接地列出。
删除文本索引
要删除文本索引,请将索引的名称传递给db.collection.dropIndex()方法。要获取索引的名称,请运行db.collection.getIndexes()方法。
有关文本索引的默认命名方案以及覆盖默认名称的信息,请参见为文本索引指定名称。
排序选项
文本索引只支持简单的二进制比较,不支持排序。
要在具有非简单排序规则的集合上创建文本索引,您必须在创建索引时显式地指定{collation: {locale: "simple"}}。
10.存储需求和性能成本
文本索引有以下存储需求和性能成本:
- 文本索引可以很大。对于插入的每个文档,每个索引字段中的每个唯一的后词干词都包含一个索引条目。
- 构建文本索引与构建大型多键索引非常相似,并且要比在相同数据上构建简单的有序(标量)索引花费更长的时间。
- 在现有集合上构建大型文本索引时,请确保对打开的文件描述符有足够高的限制。请参阅推荐的设置。
- 文本索引将影响插入吞吐量,因为MongoDB必须为每个新源文档的每个索引字段中的每个唯一的后词干词添加一个索引条目。
- 此外,文本索引不存储短语或关于文档中单词的邻近性的信息。因此,当整个集合都在RAM中时,短语查询的运行效率将大大提高。
11.文本搜索支持
文本索引支持$text查询操作。有关文本搜索的示例,请参阅$text reference页面。有关聚合管道中的$text操作的示例,请参见聚合管道中的文本搜索。
六、为文本索引指定一种语言
本教程介绍如何指定与文本索引关联的默认语言,以及如何为包含不同语言文档的集合创建文本索引。
1.为文本索引指定默认语言
与索引数据关联的默认语言确定解析词根(即词干分析)和忽略停止词的规则。索引数据的默认语言是英语。
要指定不同的语言,请在创建文本索引时使用default_language选项。有关default_language可用的语言,请参阅文本搜索语言。
下面的示例为quotes集合创建一个内容字段上的文本索引,并将default_language设置为西班牙语:
db.quotes.createIndex(
{ content : "text" },
{ default_language: "spanish" }
)2.用多种语言为集合创建文本索引
2.1指定文档中的索引语言
如果集合包含不同语言的文档或嵌入文档,则在文档或嵌入文档中包含一个名为language的字段,并将该字段的值指定为该文档或嵌入文档的语言。
当构建文本索引时,MongoDB将为该文档或嵌入的文档使用指定的语言:
- 文档中的指定语言覆盖文本索引的默认语言。
- 嵌入文档中的指定语言将覆盖封闭文档中指定的语言或索引的默认语言。
例如,集合引号包含多语言文档,其中包括文档中的语言字段和/或需要时嵌入的文档:
{
_id: 1,
language: "portuguese",
original: "A sorte protege os audazes.",
translation:
[
{
language: "english",
quote: "Fortune favors the bold."
},
{
language: "spanish",
quote: "La suerte protege a los audaces."
}
]
}
{
_id: 2,
language: "spanish",
original: "Nada hay más surrealista que la realidad.",
translation:
[
{
language: "english",
quote: "There is nothing more surreal than reality."
},
{
language: "french",
quote: "Il n'y a rien de plus surréaliste que la réalité."
}
]
}
{
_id: 3,
original: "is this a dagger which I see before me.",
translation:
{
language: "spanish",
quote: "Es este un puñal que veo delante de mí."
}
}如果使用默认的英语语言在quote字段上创建文本索引。
db.quotes.createIndex( { original: "text", "translation.quote": "text" } )然后,对于包含语言字段的文档和嵌入文档,文本索引使用该语言来解析词干和其他语言特征。
对于不包含语言字段的嵌入文档,
- 如果所包含的文档包含语言字段,那么索引将对嵌入的文档使用文档的语言。
- 否则,索引将使用嵌入文档的默认语言。
对于不包含语言字段的文档,索引使用默认语言,即英语。
2.2 使用任何字段来指定文档的语言
若要使用名称不是language的字段,请在创建索引时包含language_override选项。
例如,使用下面的命令来使用idioma作为字段名,而不是语言:
db.quotes.createIndex( { quote : "text" },
{ language_override: "idioma" } )引用集合的文档可以使用idioma字段指定一种语言:
{ _id: 1, idioma: "portuguese", quote: "A sorte protege os audazes" }
{ _id: 2, idioma: "spanish", quote: "Nada hay más surrealista que la realidad." }
{ _id: 3, idioma: "english", quote: "is this a dagger which I see before me" }3.为文本索引指定名称
在MONGODB 4.2中更改:
从4.2版本开始,为了使featureCompatibilityVersion设置为“4.2”或更大,MongoDB删除了127字节的最大索引名长度限制。在以前的版本或者特性兼容度版本(fCV)设置为“4.0”的MongoDB版本中,索引名必须在限制之内。
索引的默认名称由与_text连接的每个索引字段名组成。例如,下面的命令在字段content、users.comments和users.profiles上创建一个文本索引:
db.collection.createIndex(
{
content: "text",
"users.comments": "text",
"users.profiles": "text"
}
)索引的默认名称是:
"content_text_users.comments_text_users.profiles_text"4.为文本索引指定一个名称
您可以将name选项传递给db.collection.createIndex()方法:
db.collection.createIndex(
{
content: "text",
"users.comments": "text",
"users.profiles": "text"
},
{
name: "MyTextIndex"
}
)5.使用索引名来删除文本索引
无论文本索引是否具有默认名称,或者您为文本索引指定了名称,若要删除文本索引,请将索引名称传递给db.collection.dropIndex()方法。
例如,考虑以下操作创建的索引:
db.collection.createIndex(
{
content: "text",
"users.comments": "text",
"users.profiles": "text"
},
{
name: "MyTextIndex"
}
)然后,要删除这个文本索引,将名称“MyTextIndex”传递给db.collection.dropIndex()方法,如下所示:
db.collection.dropIndex("MyTextIndex")要获取索引的名称,可以使用db.collection.getIndexes()方法。
6.使用权重控制搜索结果
文本搜索为索引字段中包含搜索项的每个文档分配分数。分数决定了文档与给定搜索查询的相关性。
对于文本索引,索引字段的权重表示该字段相对于其他索引字段在文本搜索得分方面的重要性。
对于文档中的每个索引字段,MongoDB将匹配项的数量乘以权重并对结果求和。使用这个总和,MongoDB然后计算文档的分数。查看$meta操作符获取关于返回和按文本分数排序的详细信息。
索引字段的默认权重为1。要调整索引字段的权重,请在db.collection.createIndex()方法中包含weights选项。
警告:
仔细选择权重,以防止需要重新索引。
A collection blog has the following documents:
{
_id: 1,
content: "This morning I had a cup of coffee.",
about: "beverage",
keywords: [ "coffee" ]
}
{
_id: 2,
content: "Who doesn't like cake?",
about: "food",
keywords: [ "cake", "food", "dessert" ]
}要为content字段和keywords字段创建具有不同字段权重的文本索引,请包含createIndex()方法的weights选项。例如,下面的命令在三个字段上创建一个索引,并为其中两个字段分配权重:
db.blog.createIndex(
{
content: "text",
keywords: "text",
about: "text"
},
{
weights: {
content: 10,
keywords: 5
},
name: "TextIndex"
}
)文本索引有以下字段和权重:
- content的权重为10,
- keywords的权重为5,
- about的默认权重为1。
这些权值表示索引字段之间的相对重要性。例如,内容字段中的术语匹配有:
- 2倍(即10:5)的影响作为一个关键词匹配字段和关键字
- 10倍(即10:1)在about字段中作为一个术语匹配的影响。
7.限制扫描条目的数量
本教程介绍如何创建索引来限制扫描查询(包括$text表达式和相等条件)的索引条目的数量。
collection 清单包含以下文件:
{ _id: 1, dept: "tech", description: "lime green computer" }
{ _id: 2, dept: "tech", description: "wireless red mouse" }
{ _id: 3, dept: "kitchen", description: "green placemat" }
{ _id: 4, dept: "kitchen", description: "red peeler" }
{ _id: 5, dept: "food", description: "green apple" }
{ _id: 6, dept: "food", description: "red potato" }考虑由各个部门执行文本搜索的常见用例,例如:
db.inventory.find( { dept: "kitchen", $text: { $search: "green" } } )为了限制文本搜索只扫描特定部门内的文档,创建一个复合索引,首先在字段dept上指定一个升序/降序索引键,然后在字段description上指定一个文本索引键:
db.inventory.createIndex(
{
dept: 1,
description: "text"
}
)然后,在特定部门内的文本搜索将限制对索引文档的扫描。例如,下面的查询只扫描dept等于kitchen的文档:
db.inventory.find( { dept: "kitchen", $text: { $search: "green" } } )请注意
- 复合文本索引不能包含任何其他特殊索引类型,如多键或地理空间索引字段。
- 如果复合文本索引包含在文本索引键之前的键,则要执行$text搜索,查询谓词必须包含在前面键上的相等匹配条件。
- 在创建复合文本索引时,所有文本索引键必须在索引规范文档中邻接地列出。
七、通配符索引
MongoDB支持在一个或一组字段上创建索引来支持查询。由于MongoDB支持动态模式,所以应用程序可以查询名称不能预先知道或任意的字段。
新版本MongoDB: 4.2
MongoDB 4.2引入了通配符索引来支持针对未知或任意字段的查询。
考虑这样一个应用程序,它捕获userMetadata字段下的用户定义数据,并支持对该数据的查询:
{ "userMetadata" : { "likes" : [ "dogs", "cats" ] } }
{ "userMetadata" : { "dislikes" : "pickles" } }
{ "userMetadata" : { "age" : 45 } }
{ "userMetadata" : "inactive" }管理员希望创建索引来支持对userMetadata的任何子字段的查询。
userMetadata上的通配符索引可以支持userMetadata上的单字段查询,userMetadata.likes,userMetadata.dislikes,userMetadata.age:
db.userData.createIndex( { "userMetadata.$**" : 1 } )该索引可以支持以下查询:
db.userData.find({ "userMetadata.likes" : "dogs" })
db.userData.find({ "userMetadata.dislikes" : "pickles" })
db.userData.find({ "userMetadata.age" : { $gt : 30 } })
db.userData.find({ "userMetadata" : "inactive" })userMetadata上的非通配符索引只能支持userMetadata值上的查询。
重要的:
通配符索引不是用来替代基于工作负载的索引规划的。有关创建索引以支持查询的更多信息,请参见创建索引以支持查询。有关通配符索引限制的完整文档,请参阅通配符索引限制。
1.创建通配符索引
重要的:
mongod特性兼容版本必须是4.2才能创建通配符索引。有关设置fCV的说明,请参阅MongoDB 4.2部署上的Set特性兼容性版本。
可以使用createIndexes数据库命令或它的shell帮助程序、createIndex()或createIndexes()创建通配符索引。
1.1 在字段上创建通配符索引
索引特定字段的值:
db.collection.createIndex( { "fieldA.$**" : 1 } )使用这个通配符索引,MongoDB将索引fieldA的所有值。如果字段是嵌套的文档或数组,通配符索引将递归到文档/数组中,并存储文档/数组中所有字段的值。
例如,product_catalog集合中的文档可能包含一个product_attributes字段。product_attributes字段可以包含任意嵌套的字段,包括嵌入的文档和数组:
{
"product_name" : "Spy Coat",
"product_attributes" : {
"material" : [ "Tweed", "Wool", "Leather" ]
"size" : {
"length" : 72,
"units" : "inches"
}
}
}
{
"product_name" : "Spy Pen",
"product_attributes" : {
"colors" : [ "Blue", "Black" ],
"secret_feature" : {
"name" : "laser",
"power" : "1000",
"units" : "watts",
}
}
}下面的操作在product_attributes字段上创建一个通配符索引:
db.products_catalog.createIndex( { "product_attributes.$**" : 1 } )通配符索引可以支持对product_attributes或其嵌入字段的任意单字段查询:
db.products_catalog.find( { "product_attributes.size.length" : { $gt : 60 } } )
db.products_catalog.find( { "product_attributes.material" : "Leather" } )
db.products_catalog.find( { "product_attributes.secret_feature.name" : "laser" } )请注意:
特定于路径的通配符索引语法与通配符投影选项不兼容。有关更多信息,请参见通配符索引选项。
1.2 在所有字段上创建通配符索引
若要索引文档中所有字段的值(不包括_id),请指定“$**”作为索引键:
db.collection.createIndex( { "$**" : 1 } )使用这个通配符索引,MongoDB为集合中每个文档的所有字段建立索引。如果给定字段是嵌套的文档或数组,通配符索引将递归到文档/数组中,并存储文档/数组中所有字段的值。
例如,请参见在所有字段路径上创建通配符索引。
请注意:
通配符索引默认省略_id字段。要将_id字段包含在通配符索引中,您必须显式地将它包含在通配符投影文档中。有关更多信息,请参见通配符索引选项。
1.3 在多个特定字段上创建通配符索引
索引文档中多个特定字段的值:
db.collection.createIndex(
{ "$**" : 1 },
{ "wildcardProjection" :
{ "fieldA" : 1, "fieldB.fieldC" : 1 }
}
)使用这个通配符索引,MongoDB为集合中每个文档的指定字段索引所有值。如果给定字段是嵌套的文档或数组,通配符索引将递归到文档/数组中,并存储文档/数组中所有字段的值。
请注意:
通配符索引不支持在wildcardProjection文档中混合包含和排除语句,除非显式包含_id字段。有关wildcardProjection的更多信息,请参见通配符索引的选项。
1.4 创建一个通配符索引,该索引排除多个特定字段
索引文件中除特定字段路径外所有字段的字段:
db.collection.createIndex(
{ "$**" : 1 },
{ "wildcardProjection" :
{ "fieldA" : 0, "fieldB.fieldC" : 0 }
}
)使用这个通配符索引,MongoDB为集合中每个文档的所有字段建立索引(不包括指定的字段路径)。如果给定字段是嵌套的文档或数组,通配符索引将递归到文档/数组中,并存储文档/数组中所有字段的值。
例如,请参见从通配符索引覆盖中删除特定字段。
请注意:
通配符索引不支持在wildcardProjection文档中混合包含和排除语句,除非显式包含_id字段。有关wildcardProjection的更多信息,请参见通配符索引的选项。
2.注意事项
- 通配符索引在任何给定查询谓词中最多只能支持一个字段。有关通配符索引查询支持的更多信息,请参见通配符索引查询/排序支持。
- mongod特性兼容版本必须是4.2才能创建通配符索引。有关设置fCV的说明,请参阅MongoDB 4.2部署上的Set特性兼容性版本。
- 通配符索引默认省略_id字段。要将_id字段包含在通配符索引中,您必须显式地将它包含在wildcardProjection文档中(即{"_id": 1})。
- 可以在集合中创建多个通配符索引。
- 通配符索引可能与集合中的其他索引覆盖相同的字段。
- 通配符索引是稀疏索引,仅包含具有索引字段的文档的条目,即使索引字段包含空值。
3.行为
通配符索引在索引对象(即嵌入文档)或数组的字段时具有特定的行为:
- 如果字段是对象,通配符索引将下降到对象,并对其内容进行索引。通配符索引继续下降到它遇到的任何其他嵌入文档中。
- 如果字段是一个数组,那么通配符索引遍历数组并为每个元素建立索引:
- 如果数组中的一个元素是一个对象,通配符索引将下降到对象中,对其内容进行索引,如上所述。
- 如果元素是一个数组(即直接嵌入到父数组中的数组),那么通配符索引将不遍历嵌入的数组,而是将整个数组作为单个值进行索引。
- 对于所有其他字段,将原语(非对象/数组)值记录到索引中。
通配符索引继续遍历任何其他嵌套的对象或数组,直到它到达原始值(即不是对象或数组的字段)。然后,它对这个原始值以及到该字段的完整路径进行索引。
例如,考虑以下文件:
{
"parentField" : {
"nestedField" : "nestedValue",
"nestedObject" : {
"deeplyNestedField" : "deeplyNestedValue"
},
"nestedArray" : [
"nestedArrayElementOne",
[ "nestedArrayElementTwo" ]
]
}
}包含parentField的通配符索引记录了以下条目:
"parentField.nestedField" : "nestedValue""parentField.nestedObject.deeplyNestedField" : "deeplyNestedValue""parentField.nestedArray" : "nestedArrayElementOne""parentField.nestedArray" : ["nestedArrayElementTwo"]
注意parentField的记录。nestedArray不包含每个元素的数组位置。通配符索引在将元素记录到索引中时忽略数组元素位置。通配符索引仍然可以支持包含显式数组索引的查询。有关更多信息,请参见带有显式数组索引的查询。
有关嵌套对象的通配符索引行为的更多信息,请参见嵌套对象。
有关嵌套数组的通配符索引行为的更多信息,请参见嵌套数组。
3.1 嵌套对象
当通配符索引遇到嵌套的对象时,它向下进入该对象并对其内容进行索引。例如:
{
"parentField" : {
"nestedField" : "nestedValue",
"nestedArray" : ["nestedElement"]
"nestedObject" : {
"deeplyNestedField" : "deeplyNestedValue"
}
}
}一个通配符索引,其中包括parentField下降到对象遍历和索引其内容:
- 对于每个本身就是对象的字段(即嵌入的文档),向下到对象以索引其内容。
- 对于每个作为数组的字段,遍历数组并索引其内容。
- 对于所有其他字段,将原语(非对象/数组)值记录到索引中。
通配符索引继续遍历任何其他嵌套的对象或数组,直到它到达原始值(即不是对象或数组的字段)。然后,它对这个原始值以及到该字段的完整路径进行索引。
给定示例文档,通配符索引将以下记录添加到索引中:
"parentField.nestedField" : "nestedValue""parentField.nestedObject.deeplyNestedField" : "deeplyNestedValue""parentField.nestedArray" : "nestedElement"
3.2 嵌套的数组
当通配符索引遇到嵌套的数组时,它尝试遍历该数组以索引其元素。如果数组本身是父数组(即嵌入数组)中的一个元素,通配符索引将把整个数组记录为一个值,而不是遍历其内容。例如:
{
"parentArray" : [
"arrayElementOne",
[ "embeddedArrayElement" ],
"nestedObject" : {
"nestedArray" : [
"nestedArrayElementOne",
"nestedArrayElementTwo"
]
}
]
}包含parentArray的通配符索引向下进入数组,遍历并索引其内容:
- 对于数组中的每个元素(即嵌入式数组),将整个数组作为一个值建立索引。
- 对于作为对象的每个元素,向下到对象中遍历并索引其内容。
- 对于所有其他字段,将原语(非对象/数组)值记录到索引中。
通配符索引继续遍历任何其他嵌套的对象或数组,直到它到达原始值(即不是对象或数组的字段)。然后,它对这个原始值以及到该字段的完整路径进行索引。
给定示例文档,通配符索引将以下记录添加到索引中:
"parentArray" : "arrayElementOne""parentArray" : ["embeddedArrayElement"]"parentArray.nestedObject.nestedArray" : "nestedArrayElementOne""parentArray.nestedObject.nestedArray" : "nestedArrayElementTwo"
注意parentField的记录。nestedArray不包含每个元素的数组位置。通配符索引在将元素记录到索引中时忽略数组元素位置。通配符索引仍然可以支持包含显式数组索引的查询。有关更多信息,请参见带有显式数组索引的查询。
3.3 限制条件
- 不能使用通配符索引对集合进行切分。在要分割的字段上创建非通配符索引。有关碎片密钥选择的更多信息,请参见碎片密钥。
- 不能创建复合索引。
- 不能为通配符索引指定下列属性:
不能使用通配符语法创建以下索引类型:
重要的:
通配符索引与通配符文本索引不同且不兼容。通配符索引不能使用$text操作符支持查询。
4.通配符索引查询/排序支持
4.1覆盖查询
通配符索引只能在以下条件都为真时才能支持覆盖查询:
- 查询计划器选择通配符索引来满足查询谓词。
- 查询谓词指定通配符索引覆盖的一个字段。
- 该投影显式地排除了_id,只包含查询字段。
- 指定的查询字段从来不是数组。
考虑雇员集合上的以下通配符索引:
db.products.createIndex( { "$**" : 1 } )接下来的单个作用域lastName的查询操作和从结果文档中投影出所有其他字段:
db.products.find(
{ "lastName" : "Doe" },
{ "_id" : 0, "lastName" : 1 }
)4.2 包含多个字段的查询谓词
通配符索引最多只能支持一个查询谓词字段。那就是:
- MongoDB不能使用非通配符索引来满足查询谓词的一部分,也不能使用通配符索引来满足另一部分。
- MongoDB不能使用一个通配符索引来满足查询谓词的一部分,而使用另一个通配符索引来满足另一部分。
- 即使一个通配符索引可以支持多个查询字段,MongoDB也可以使用通配符索引只支持一个查询字段。所有剩余的字段都不使用索引进行解析。
但是,MongoDB可以使用相同的通配符索引来满足查询$or或聚合$or操作符的每个独立参数。
4.3 查询和排序
MongoDB可以使用通配符索引来满足sort(),只有在以下所有条件都为真时:
- 查询计划器选择通配符索引来满足查询谓词。
- sort()只指定查询谓词字段。
- 指定的字段从来不是数组。
如果不满足上述条件,MongoDB就不能使用通配符索引进行排序。MongoDB不支持需要不同于查询谓词的索引的排序操作。有关更多信息,请参见索引交集和排序。
考虑产品集合上的以下通配符索引:
db.products.createIndex( { "product_attributes.$**" : 1 } )下面的操作查询单个字段product_attributes。同一领域的价格和种类:
db.products.find(
{ "product_attributes.price" : { $gt : 10.00 } },
).sort(
{ "product_attributes.price" : 1 }
)假设指定的价格不是一个数组,MongoDB可以使用product_attributes。$**通配符索引,用于同时满足find()和sort()。
4.4 不支持的查询模式
- 通配符索引不支持检查字段是否不存在的查询条件。
- 通配符索引不支持检查字段是否等于文档或数组的查询条件
- 通配符索引不支持检查字段是否不等于null的查询条件。
4.5 具有显式数组索引的查询
在索引期间,MongoDB通配符索引不会记录数组中任何给定元素的数组位置。但是,MongoDB仍然可以选择通配符索引来回答包含一个或多个显式数组索引的字段路径的查询(例如,parentArray.0.nestedArray.0)。由于为每个连续嵌套数组定义索引边界的复杂性不断增加,所以MongoDB不考虑通配符索引来回答查询中的给定字段路径(如果该路径包含超过8个显式数组索引)。MongoDB仍然可以考虑通配符索引来回答查询中的其他字段路径。
例如:
{
"parentObject" : {
"nestedArray" : [
"elementOne",
{
"deeplyNestedArray" : [ "elementTwo" ]
}
]
}
}MongoDB可以选择一个通配符索引,其中包括parentObject,以满足以下查询:
- “parentObject.nestedArray。0”:“elementOne”
- :“parentObject.nestedArray.1.deeplyNestedArray.0 elementTwo”
如果查询谓词中的给定字段路径指定了超过8个显式数组索引,则MongoDB不考虑用于回答该字段路径的通配符索引。相反,MongoDB要么选择另一个合适的索引来回答查询,要么执行收集扫描。
注意,通配符索引本身对索引文档时遍历文档的深度没有任何限制;此限制仅适用于显式指定精确数组索引的查询。通过发出没有显式数组索引的相同查询,MongoDB可以选择通配符索引来回答查询:
"parentObject.nestedArray" : "elementOne""parentObject.nestedArray.deeplyNestedArray" : "elementTwo"
通配符指数限制
5.不兼容的索引类型或属性
通配符索引不支持以下索引类型或属性:
请注意:
通配符索引与通配符文本索引不同且不兼容。通配符索引不能使用$text操作符支持查询。
6.不支持的查询和聚合模式
6.1字段不存在
通配符索引是稀疏的,不会索引空字段。因此,通配符索引不支持查询不存在字段的文档。
例如,考虑一个在product_attributes上带有通配符索引的集合库存。通配符索引不能支持以下查询:
db.inventory.find( {"product_attributes" : { $exists : false } } )
db.inventory.aggregate([
{ $match : { "product_attributes" : { $exists : false } } }
])6.2字段等于文档或数组
通配符索引为文档或数组的内容生成条目,而不是文档/数组本身。因此,通配符索引不能支持精确的文档/数组相等匹配。通配符索引可以支持在字段等于空文档{}时进行查询。
例如,考虑一个在product_attributes上带有通配符索引的集合库存。通配符索引不能支持以下查询:
db.inventory.find({ "product_attributes" : { "price" : 29.99 } } )
db.inventory.find({ "product_attributes.tags" : [ "waterproof", "fireproof" ] } )
db.inventory.aggregate([{
$match : { "product_attributes" : { "price" : 29.99 } }
}])
db.inventory.aggregate([{
$match : { "product_attributes.tags" : ["waterproof", "fireproof" ] } }
}])6.3 字段不等于文档或数组
通配符索引为文档或数组的内容生成条目,而不是文档/数组本身。因此,通配符索引不能支持精确的文档/数组不等式匹配。
例如,考虑一个在product_attributes上带有通配符索引的集合库存。通配符索引不能支持以下查询:
db.inventory.find( { $ne : [ "product_attributes", { "price" : 29.99 } ] } )
db.inventory.find( { $ne : [ "product_attributes.tags", [ "waterproof", "fireproof" ] ] } )
db.inventory.aggregate([{
$match : { $ne : [ "product_attributes", { "price" : 29.99 } ] }
}])
db.inventory.aggregate([{
$match : { $ne : [ "product_attributes.tags", [ "waterproof", "fireproof" ] ] }
}])6.4 字段不等于null
如果给定字段是集合中任何文档中的数组,通配符索引不支持对该字段不等于null的文档进行查询。
例如,考虑一个在product_attributes上带有通配符索引的集合库存。如果product_attributes,通配符索引不能支持以下查询。标签是集合中任何文档中的一个数组:
db.inventory.find( { $ne : [ "product_attributes.tags", null ] } )
db.inventory.aggregate([{
$match : { $ne : [ "product_attributes.tags", null ] }
}])7.分区
不能使用通配符索引对集合进行切分。在要分割的字段上创建非通配符索引。有关碎片密钥选择的更多信息,请参见碎片密钥。
八、2 dsphere索引
概述:
2dsphere索引支持在类地球体上计算几何图形的查询。2dsphere索引支持所有MongoDB地理空间查询:包含查询、交叉查询和邻近查询。有关地理空间查询的更多信息,请参见地理空间查询。
2dsphere索引支持存储为GeoJSON对象和遗留坐标对的数据(也请参阅2dsphere索引字段限制)。对于遗留坐标对,索引将数据转换为GeoJSON点。
1.Versions
2dsphere Index Version | Description |
|---|---|
| Version 3 | MongoDB 3.2引入了2dsphere索引的版本3。版本3是在MongoDB 3.2及以后版本中创建的2dsphere索引的默认版本。 |
| Version 2 | MongoDB 2.6引入了2dsphere索引的版本2。版本2是在MongoDB 2.6和3.0系列中创建的2dsphere索引的默认版本。 |
若要覆盖默认版本并指定不同的版本,请在创建索引时包含选项{"2dsphereIndexVersion": <version>}。
1.1 稀疏特性
版本2和以后的2dsphere索引总是稀疏的,并且忽略稀疏选项。如果文档缺少2dsphere索引字段(或者该字段为null或空数组),MongoDB不会将文档项添加到索引中。对于insert, MongoDB插入文档,但不添加到2dsphere索引。
对于包含2dsphere索引键和其他类型键的复合索引,只有2dsphere索引字段确定索引是否引用文档。
MongoDB的早期版本只支持2dsphere(版本1)索引。2dsphere(版本1)索引在默认情况下不是稀疏的,并且将拒绝具有空位置字段的文档。
1.2额外GeoJSON对象
版本2和更高版本的2dsphere索引包括对附加的GeoJSON对象的支持:多点、多线字符串、多多边形和几何集合。有关所有受支持的GeoJSON对象的详细信息,请参阅GeoJSON对象。
2.注意事项
2.1 geoNear和$geoNear限制
从MongoDB 4.0开始,可以为$geoNear管道阶段指定一个键选项,以指示要使用的索引字段路径。这使得$geoNear阶段可以用于具有多个2dsphere索引和/或多个2d索引的集合:
- 如果集合有多个2dsphere索引和/或多个2d索引,则必须使用key选项指定要使用的索引字段路径。
- 如果不指定键,就不能有多个2dsphere索引和/或多个2d索引,因为没有键,多个2d索引或2dsphere索引之间的索引选择是不明确的。
请注意:
如果您没有指定键,并且最多只有一个2dsphere索引索引和/或只有一个2dsphere索引索引,MongoDB首先查找要使用的2d索引。如果不存在2d索引,则MongoDB将查找要使用的2dsphere索引。
2.2 碎片关键限制
在对集合进行分片时,不能使用2dsphere索引作为分片键。但是,可以使用不同的字段作为切分键,在切分集合上创建地理空间索引。
2.3 2dsphere索引字段限制
带有2dsphere索引的字段必须以坐标对或GeoJSON数据的形式保存几何数据。如果您试图在一个2dsphere索引字段中插入一个包含非几何数据的文档,或者在一个集合上构建一个2dsphere索引,其中索引字段包含非几何数据,那么操作将失败。
3.创建一个2dsphere索引
要创建一个2dsphere索引,使用db.collection.createIndex()方法并指定字符串文字“2dsphere”作为索引类型:
db.collection.createIndex( { <location field> : "2dsphere" } )其中,<location字段>的值是一个GeoJSON对象或一个遗留坐标对。
与可以引用一个位置字段和另一个位置字段的复合2d索引不同,复合2dsphere索引可以引用多个位置字段和非位置字段。
对于以下示例,考虑一个集合位置,其中的文档将位置数据存储为一个名为loc的字段中的GeoJSON点:
db.places.insert(
{
loc : { type: "Point", coordinates: [ -73.97, 40.77 ] },
name: "Central Park",
category : "Parks"
}
)
db.places.insert(
{
loc : { type: "Point", coordinates: [ -73.88, 40.78 ] },
name: "La Guardia Airport",
category : "Airport"
}
)3.1 创建一个2dsphere索引
下面的操作在location字段loc上创建一个2dsphere索引:
db.places.createIndex( { loc : "2dsphere" } )3.2使用2dsphere索引键创建一个复合索引
复合索引可以包括与非地理空间索引键组合的2dsphere索引键。例如,下面的操作创建了一个复合索引,其中第一个键loc是2dsphere索引键,其余的键类别和名称是非地理空间索引键,分别是降序(-1)和升序(1)键。
db.places.createIndex( { loc : "2dsphere" , category : -1, name: 1 } )与2d索引不同,复合2dsphere索引不需要location字段作为第一个索引字段。例如:
db.places.createIndex( { category : 1 , loc : "2dsphere" } )4.查询一个2dsphere索引
4.1 一个多边形边界的GeoJSON对象
$geoWithin操作符查询在GeoJSON多边形中找到的位置数据。您的位置数据必须以GeoJSON格式存储。使用以下语法:
db.<collection>.find( { <location field> :
{ $geoWithin :
{ $geometry :
{ type : "Polygon" ,
coordinates : [ <coordinates> ]
} } } } )下面的示例选择完全存在于GeoJSON多边形中的所有点和形状:
db.places.find( { loc :
{ $geoWithin :
{ $geometry :
{ type : "Polygon" ,
coordinates : [ [
[ 0 , 0 ] ,
[ 3 , 6 ] ,
[ 6 , 1 ] ,
[ 0 , 0 ]
] ]
} } } } )GeoJSON对象的交集
$geoIntersects操作符查询与指定的GeoJSON对象相交的位置。如果交点是非空的,则位置与该对象相交。这包括具有共享边缘的文档。
4.2 $geoIntersects操作符使用以下语法:
db.<collection>.find( { <location field> :
{ $geoIntersects :
{ $geometry :
{ type : "<GeoJSON object type>" ,
coordinates : [ <coordinates> ]
} } } } )下面的示例使用$geoIntersects选择与坐标数组定义的多边形相交的所有索引点和形状。
db.places.find( { loc :
{ $geoIntersects :
{ $geometry :
{ type : "Polygon" ,
coordinates: [ [
[ 0 , 0 ] ,
[ 3 , 6 ] ,
[ 6 , 1 ] ,
[ 0 , 0 ]
] ]
} } } } )4.3 接近GeoJSON点
接近查询返回最接近定义点的点,并根据距离对结果进行排序。对GeoJSON数据的接近查询需要一个2dsphere索引。
要查询GeoJSON点的邻近性,可以使用$near操作符。距离的单位是米。
$near使用以下语法:
db.<collection>.find( { <location field> :
{ $near :
{ $geometry :
{ type : "Point" ,
coordinates : [ <longitude> , <latitude> ] } ,
$maxDistance : <distance in meters>
} } } )例如,参见$near。
还请参阅$nearSphere操作符和:pipeline:$geoNear聚合管道阶段。
4.4 球面上定义的圆内的点
要选择球体上“球形盖”中的所有网格坐标,请使用$geoWithin和$centerSphere操作符。指定一个数组,其中包含:
- 圆中心点的网格坐标
- 以弧度计算的圆的半径。要计算弧度,请参阅使用球面几何计算距离。
使用以下语法:
db.<collection>.find( { <location field> :
{ $geoWithin :
{ $centerSphere :
[ [ <x>, <y> ] , <radius> ] }
} } )下面的示例查询网格坐标,并返回经度88 W和纬度30 n范围内的所有文档。
db.places.find( { loc :
{ $geoWithin :
{ $centerSphere :
[ [ -88 , 30 ] , 10 / 3963.2 ]
} } } )5. 2 d索引
对于存储为二维平面上的点的数据,使用2d索引。2d索引用于MongoDB 2.2及更早版本中使用的遗留坐标对。
如果:使用2d索引:
- 您的数据库有来自MongoDB 2.2或更早版本的遗留坐标对,
- 您不打算将任何位置数据存储为GeoJSON对象。
5.1 注意事项
从MongoDB 4.0开始,可以为$geoNear管道阶段指定一个键选项,以指示要使用的索引字段路径。这使得$geoNear阶段可以用于具有多个2d索引和/或多个2dsphere索引的集合:
- 如果集合有多个2d索引和/或多个2dsphere索引,则必须使用key选项指定要使用的索引字段路径。
- 如果不指定键,就不能有多个2d索引和/或多个2dsphere索引,因为没有该键,多个2d索引或2dsphere索引之间的索引选择是不明确的。
请注意:
如果您没有指定键,并且最多只有一个2d索引索引和/或只有一个2d索引索引,MongoDB首先查找要使用的2d索引。如果不存在2d索引,则MongoDB将查找要使用的2dsphere索引。
如果您的位置数据包含GeoJSON对象,则不要使用2d索引。要在遗留坐标对和GeoJSON对象上建立索引,可以使用2dsphere索引。
在对集合进行分片时,不能使用2d索引作为分片键。但是,可以使用不同的字段作为切分键,在切分集合上创建地理空间索引。
5.2 行为
二维索引支持在平坦的欧几里得平面上进行计算。2d索引还支持球体上的距离计算(即$nearSphere),但对于球体上的几何计算(如$geoWithin),将数据存储为GeoJSON对象并使用2dsphere索引。
一个2d索引可以引用两个字段。第一个必须是location字段。2d复合索引构造首先在location字段上选择的查询,然后根据附加条件过滤这些结果。复合2d索引可以覆盖查询。
5.3 sparse Property
2d索引总是稀疏的,忽略稀疏选项。如果文档缺少2d索引字段(或者字段为null或空数组),MongoDB不会将文档条目添加到2d索引中。对于insert, MongoDB插入文档,但不添加到2d索引。
对于包含2d索引键和其他类型键的复合索引,只有2d索引字段确定索引是否引用文档。
5.4 排序选项
2d索引只支持简单的二进制比较,不支持排序选项。
要在具有非简单排序规则的集合上创建2d索引,您必须在创建索引时显式地指定{collation: {locale: "simple"}}。
6.创建2d索引
要构建地理空间2d索引,请使用db.collection.createIndex()方法并指定2d。使用以下语法:
db.<collection>.createIndex( { <location field> : "2d" ,
<additional field> : <value> } ,
{ <index-specification options> } )2d索引使用以下可选的索引规范选项:
{ min : <lower bound> , max : <upper bound> ,
bits : <bit precision> }6.1 定义2d索引的位置范围
默认情况下,2d索引采用经度和纬度,边界为-180(包括)和180(不包括)。如果文档包含超出指定范围的坐标数据,MongoDB将返回一个错误。
重要的:
默认边界允许应用程序插入纬度大于或小于-90的无效文档。没有定义具有此类无效点的地理空间查询的行为。
在2d索引中,您可以更改位置范围。
您可以使用非默认的位置范围构建一个2d地理空间索引。创建索引时使用min和max选项。使用以下语法:
db.collection.createIndex( { <location field> : "2d" } ,
{ min : <lower bound> , max : <upper bound> } )6.2 为2d索引定义位置精度
默认情况下,遗留坐标对上的2d索引使用26位精度,这大致相当于使用默认范围-180到180的2英尺或60厘米的精度。精度是通过用于存储位置数据的geohash值的位大小来度量的。您可以配置最多32位精度的地理空间索引。
索引精度不影响查询精度。最终的查询处理总是使用实际的网格坐标。精度较低的优点是插入操作的处理开销较低,并且使用的空间较少。更高精度的一个优点是,查询扫描索引的更小部分来返回结果。
若要配置默认之外的位置精度,请在创建索引时使用bits选项。使用下面的语法:
db.<collection>.createIndex( {<location field> : "<index type>"} ,
{ bits : <bit precision> } )7.查询2d索引
以下部分描述2d索引支持的查询。
7.1 在平面上定义的形状内的点
要选择平面上给定形状中的所有遗留坐标对,请使用$geoWithin操作符和形状操作符。使用以下语法:
db.<collection>.find( { <location field> :
{ $geoWithin :
{ $box|$polygon|$center : <coordinates>
} } } )以下是对左上角[0,0]和右上角[100,100]定义的矩形内的文档的查询。
db.places.find( { loc :
{ $geoWithin :
{ $box : [ [ 0 , 0 ] ,
[ 100 , 100 ] ]
} } } )以下是对左上角[0,0]和右上角[100,100]定义的矩形内的文档的查询。
db.places.find( { loc :
{ $geoWithin :
{ $box : [ [ 0 , 0 ] ,
[ 100 , 100 ] ]
} } } )对于以[-74,40.74]为圆心、半径为10的圆内的文档进行以下查询:
db.places.find( { loc: { $geoWithin :
{ $center : [ [-74, 40.74 ] , 10 ]
} } } )每种形状的语法和示例如下:
7.2 球面上定义的圆内的点
由于遗留问题,MongoDB支持基本的平面2d索引球形查询。通常,球面计算应该使用2dsphere索引,如2dsphere索引中所述。
要查询球体上“球形盖”中的遗留坐标对,可以使用$geoWithin和$centerSphere操作符。指定一个数组,其中包含:
- 圆中心点的网格坐标
- 以弧度计算的圆的半径。要计算弧度,请参阅使用球面几何计算距离。
使用以下语法:
db.<collection>.find( { <location field> :
{ $geoWithin :
{ $centerSphere : [ [ <x>, <y> ] , <radius> ] }
} } )下面的示例查询返回经度88 W和纬度30 n的半径为10英里范围内的所有文档。
db.<collection>.find( { loc : { $geoWithin :
{ $centerSphere :
[ [ 88 , 30 ] , 10 / 3963.2 ]
} } } )7.3 接近平面上的一点
接近查询返回最接近定义点的遗留坐标对,并根据距离对结果进行排序。可以使用$near操作符。操作符需要一个2d索引。
$near操作符使用以下语法:
db.<collection>.find( { <location field> :
{ $near : [ <x> , <y> ]
} } )7.4 在平面上精确匹配
不能使用2d索引来返回坐标对的精确匹配。在存储坐标的字段上使用升序或降序的标量索引来返回精确的匹配。
在下面的例子中,如果您有一个{'loc': 1}索引,find()操作将返回一个位置上的精确匹配:
db.<collection>.find( { loc: [ <x> , <y> ] } )此查询将返回值为[<x>, <y>]的任何文档。
8. 2d指数内部
本文档更深入地解释了MongoDB的2d地理空间索引的内部机制。对于正常的操作或应用程序开发来说,这些材料不是必需的,但是对于故障排除和进一步的理解可能是有用的。
8.1 计算二维索引的Geohash值
在遗留坐标对上创建地理空间索引时,MongoDB为指定位置范围内的坐标对计算geohash值,然后索引geohash值。
要计算geohash值,递归地将二维映射划分为象限。然后给每个象限分配一个2位的值。例如,4个象限的2位表示是:
01 11
00 10这些两位的值(00、01、10和11)表示每个象限和每个象限内的所有点。对于具有两位分辨率的geohash,左下角象限中的所有点的geohash值都是00。左上角象限的geohash值为01。右下角和右上角的geohash值分别为10和11。
为了提供额外的精度,继续将每个象限划分为子象限。每个子象限将包含象限的geohash值与子象限的值连接起来。右上角象限的geohash值为11,而子象限的geohash值为(从左上角顺时针方向):1101、1111、1110和1100。
8.2 2d索引的多位置文档
请注意:
2dsphere索引可以覆盖文档中的多个地理空间字段,并且可以使用多点嵌入文档来表示点列表。
虽然2d地理空间索引在文档中不支持多个地理空间字段,但是可以使用多键索引在单个文档中索引多个坐标对。在最简单的例子中,你可能有一个字段(例如locs),它包含一个坐标数组,如下例所示:
db.places.save( {
locs : [ [ 55.5 , 42.3 ] ,
[ -74 , 44.74 ] ,
{ lng : 55.5 , lat : 42.3 } ]
} )数组的值可以是数组(如[55.5,42.3]),也可以是嵌入文档(如{lng: 55.5, lat: 42.3})。
然后可以在locs字段上创建地理空间索引,如下所示:
db.places.createIndex( { "locs": "2d" } )您还可以将位置数据建模为嵌入文档中的字段。在这种情况下,文档将包含一个字段(例如地址),它包含一个文档数组,其中每个文档都有一个字段(例如loc:),它包含位置坐标。例如:
db.records.save( {
name : "John Smith",
addresses : [ {
context : "home" ,
loc : [ 55.5, 42.3 ]
} ,
{
context : "work",
loc : [ -74 , 44.74 ]
}
]
} )然后可以在地址上创建地理空间索引。loc字段如下例所示:
db.records.createIndex( { "addresses.loc": "2d" } )9. 使用球面几何计算距离
警告:
对于球形查询,使用2dsphere索引结果。
对球形查询使用2d索引可能会导致不正确的结果,例如对围绕极点的球形查询使用2d索引。
2d索引支持在欧几里得平面(平面)上计算距离的查询。该索引还支持以下查询操作符和命令,使用球面几何计算距离:
请注意:
虽然2d索引支持使用球面距离的基本查询,但是如果您的数据主要是经度和纬度,那么可以考虑移动到2dsphere索引。
$nearSphere$centerSphere$near$geoNearpipeline stage with thespherical: trueoption
重要的:
上述操作使用弧度表示距离。其他球形查询操作符则不需要,比如$geoWithin。
要使球形查询操作符正常工作,必须将距离转换为弧度,并将弧度转换为应用程序使用的距离单位。
转换:
- 到弧度的距离:用距离除以球体(如地球)的半径,单位与测量距离相同。
- 弧度到距离:在单位系统中将弧度乘以球体(例如地球)的半径,然后将距离转换为。
地球的赤道半径约为3,963.2英里或6,378.1公里。
下面的查询将从中心所描述的半径为100英里的圆[- 74,40.74]内的places集合返回文档:
db.places.find( { loc: { $geoWithin: { $centerSphere: [ [ -74, 40.74 ] ,
100 / 3963.2 ] } } } )请注意:
如果指定经纬度坐标,首先列出经度,然后是纬度:
- 有效经度值在-180和180之间,两者都包括在内。
- 有效纬度值在-90和90之间,两者都包括在内。
九、geoHaystack索引
geoHaystack索引是一种特殊的索引,经过优化后可以在小范围内返回结果。geoHaystack索引可以提高使用平面几何结构的查询的性能。
对于使用球面几何的查询,2dsphere索引是比haystack索引更好的选择。2dsphere索引允许字段重新排序;geoHaystack索引要求第一个字段是location字段。此外,geoHaystack索引只能通过命令使用,因此总是一次返回所有结果。
1.行为
geoHaystack索引创建来自相同地理区域的“桶”文档,以提高局限于该区域的查询的性能。geoHaystack索引中的每个bucket都包含指定经度和纬度范围内的所有文档。
1.1 稀疏特性
geoHaystack索引默认是稀疏的,忽略了sparse: true选项。如果一个文档缺少一个geoHaystack索引字段(或者该字段为null或一个空数组),MongoDB就不会将该文档的条目添加到geoHaystack索引中。对于insert, MongoDB插入文档,但不添加到geoHaystack索引。
geoHaystack索引包括一个geoHaystack索引键和一个非地理空间索引键;但是,只有geoHaystack索引字段确定索引是否引用文档。
1.2 排序选项
geoHaystack索引只支持简单的二进制比较,不支持排序。
要在具有非简单排序规则的集合上创建geoHaystack索引,您必须在创建索引时显式地指定{collation: {locale: "simple"}}。
2.创建geoHaystack索引
要创建一个geoHaystack索引,请参见创建一个Haystack索引。有关查询草堆索引的信息和示例,请参见查询草堆索引。
3.创建一个Haystack索引
一个Haystack索引必须引用两个字段:location字段和第二个字段。第二个字段用于精确匹配。Haystack索引根据位置返回文档,并根据单个附加条件返回精确匹配的文档。这些索引不一定适合将最近的文档返回到特定位置。
要构建一个haystack索引,请使用以下语法:
db.coll.createIndex( { <location field> : "geoHaystack" ,
<additional field> : 1 } ,
{ bucketSize : <bucket value> } )要构建一个草堆索引,您必须在创建索引时指定bucketSize选项。bucketSize 5创建一个索引,该索引将在指定经度和纬度的5个单位内的位置值分组。bucketSize还决定了索引的粒度。您可以根据数据的分布调整参数,以便通常只搜索非常小的区域。桶定义的区域可以重叠。一个文档可以存在于多个桶中。
例子:
如果你有一个包含类似以下字段的文档集合:
{ _id : 100, pos: { lng : 126.9, lat : 35.2 } , type : "restaurant"}
{ _id : 200, pos: { lng : 127.5, lat : 36.1 } , type : "restaurant"}
{ _id : 300, pos: { lng : 128.0, lat : 36.7 } , type : "national park"}下面的操作创建一个带有存储桶的草堆索引,这些桶将键存储在一个经度或纬度单位内。
db.places.createIndex( { pos : "geoHaystack", type : 1 } ,
{ bucketSize : 1 } )这个索引用_id字段存储文档,该字段在两个不同的桶中有值200:
- 在一个包含_id字段值为100的文档的bucket中
- 在一个包含_id字段值为300的文档的bucket中
要使用haystack索引进行查询,可以使用geoSearch命令。参见查询草堆索引。
默认情况下,使用haystack索引的查询返回50个文档。
4.查询Haystack 索引
Haystack索引是一种特殊的二维地理空间索引,经过优化后可在小范围内返回结果。要创建草堆索引,请参见创建Haystack索引。
要查询Haystack索引,请使用geearch命令。您必须指定地理搜索的坐标和附加字段。例如,要返回所有带有示例点附近type字段中的值restaurant的文档,命令如下:
db.runCommand( { geoSearch : "places" ,
search : { type: "restaurant" } ,
near : [-74, 40.74] ,
maxDistance : 10 } )请注意
Haystack索引不适合查询最接近特定位置的完整文档列表。与存储桶大小相比,最近的文档可能更遥远。
请注意
目前haystack索引不支持球形查询操作。
find()方法不能访问haystack索引。
十、散列索引
散列索引使用索引字段值的散列来维护条目。
哈希索引支持使用哈希分片键分片。基于散列的分片使用字段的散列索引作为切分键来跨sharded集群分区数据。
使用散列切分键对集合进行切分会导致数据分布更加随机。更多细节见散列分片。
1.哈希函数
散列索引使用散列函数来计算索引字段值的散列。哈希函数可以折叠嵌入的文档并计算整个值的哈希值,但不支持多键(如数组)索引。
提示:
MongoDB在使用散列索引解析查询时自动计算散列。应用程序不需要计算哈希值。
从4.0版本开始,mongo shell提供了convertShardKeyToHashed()方法。此方法使用与散列索引相同的散列函数,可用于查看键的散列值。
2.创建散列索引
要创建散列索引,请指定散列作为索引键的值,如下面的示例所示:
db.collection.createIndex( { _id: "hashed" } )3.注意事项
MongoDB支持任何单个字段的散列索引。哈希函数可以折叠嵌入的文档并计算整个值的哈希值,但不支持多键(即数组)索引。
您不能创建具有散列索引字段的复合索引,也不能为散列索引指定唯一的约束;但是,您可以在同一个字段上创建散列索引和升序/降序(即非散列)索引:MongoDB将对范围查询使用标量索引。
3.1 ![]()
警告
MongoDB散列索引在散列之前将浮点数截断为64位整数。例如,散列索引将为一个值为2.3、2.2和2.9的字段存储相同的值。为了防止冲突,不要对不能可靠地转换为64位整数(然后再转换回浮点数)的浮点数使用散列索引。MongoDB散列索引不支持大于![]() 的浮点值。
的浮点值。
要查看键的散列值是什么,请参见convertShardKeyToHashed()。
3.2 ![]()
对于散列索引,MongoDB 4.2确保PowerPC上的浮点值![]() 的散列值与其他平台一致。
的散列值与其他平台一致。
虽然不支持在可能包含大于![]() 的浮点值的字段上使用散列索引,但是客户端仍然可以在索引字段为
的浮点值的字段上使用散列索引,但是客户端仍然可以在索引字段为![]() 的地方插入文档。
的地方插入文档。
要列出部署中所有集合的所有散列索引,可以在mongo shell中使用以下操作:
db.adminCommand("listDatabases").databases.forEach(function(d){
let mdb = db.getSiblingDB(d.name);
mdb.getCollectionInfos({ type: "collection" }).forEach(function(c){
let currentCollection = mdb.getCollection(c.name);
currentCollection.getIndexes().forEach(function(idx){
let idxValues = Object.values(Object.assign({}, idx.key));
if (idxValues.includes("hashed")) {
print("Hashed index: " + idx.name + " on " + idx.ns);
printjson(idx);
};
});
});
});要检查索引字段是否包含值![]() ,请对集合和索引字段执行以下操作:
,请对集合和索引字段执行以下操作:
- 如果索引字段类型是标量,而不是文档:
// substitute the actual collection name for <collection>
// substitute the actual indexed field name for <indexfield>
db.<collection>.find( { <indexfield>: Math.pow(2,63) } );- 如果索引字段类型是文档(或标量),您可以运行:
// substitute the actual collection name for <collection>
// substitute the actual indexed field name for <indexfield>
db.<collection>.find({
$where: function() {
function findVal(obj, val) {
if (obj === val)
return true;
for (const child in obj) {
if (findVal(obj[child], val)) {
return true;
}
}
return false;
}
return findVal(this.<indexfield>, Math.pow(2, 63));
}
})十一、索引属性
1. TTL索引
TTL索引是一种特殊的单字段索引,MongoDB可以使用它在一定的时间或特定的时钟时间后自动从集合中删除文档。数据过期对于某些类型的信息非常有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
要创建TTL索引,可以使用db.collection.createIndex()方法和expireAfterSeconds选项来创建一个字段,该字段的值要么是一个日期,要么是一个包含日期值的数组。
例如,要在eventlog集合的lastModifiedDate字段上创建TTL索引,请在mongo shell中使用以下操作:
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )1.1 表现
1.1.1 过期的数据
TTL索引在索引字段值之后经过指定的秒数后过期文档;也就是说,过期阈值是索引字段值加上指定的秒数。
如果字段是一个数组,并且索引中有多个日期值,MongoDB使用数组中最低(即最早)的日期值来计算过期阈值。
如果文档中的索引字段不是保存日期值的日期或数组,文档将不会过期。
如果文档不包含索引字段,文档将不会过期。
1.1.2 删除操作
mongod中的一个后台线程读取索引中的值并从集合中删除过期的文档。
当TTL线程处于活动状态时,您将在db.currentOp()的输出或数据库分析器收集的数据中看到删除操作。
a.删除操作的定时
一旦索引在主数据库上完成构建,MongoDB就开始删除过期的文档。有关索引构建过程的更多信息,请参见已填充集合的索引构建。
TTL索引不保证过期的数据将在过期后立即删除。从文档过期到MongoDB从数据库中删除文档之间可能有一个延迟。
删除过期文档的后台任务每60秒运行一次。因此,在文档过期和后台任务运行期间,文档可能会保留在集合中。
因为删除操作的持续时间取决于mongod实例的工作负载,所以过期的数据可能会在后台任务运行之间的60秒周期之外存在一段时间。
b.副本集
在复制集成员上,TTL后台线程只在成员处于主状态时删除文档。当一个成员处于二级状态时,TTL后台线程是空闲的。次要成员从主要成员复制删除操作。
1.1.3 支持查询
TTL索引以与非TTL索引相同的方式支持查询。
1.2 限制条件
- TTL索引是单字段索引。复合索引不支持TTL并忽略expireAfterSeconds选项。
- _id字段不支持TTL索引。
- 您不能在一个有上限的集合上创建TTL索引,因为MongoDB不能从一个有上限的集合中删除文档。
- 您不能使用createIndex()来更改现有索引的expireAfterSeconds值。而是将collMod数据库命令与索引收集标记结合使用。否则,要更改现有索引的选项的值,必须首先删除索引并重新创建。
- 如果某个字段已经存在非TTL单字段索引,则不能在同一字段上创建TTL索引,因为不能创建具有相同键规范且仅根据选项不同的索引。要将非TTL单字段索引更改为TTL索引,必须先删除索引,然后使用expireAfterSeconds选项重新创建索引。
2. 通过设置TTL使集合中的数据过期
本文档介绍了MongoDB的“生存时间”(time to live)或TTL收集特性。TTL集合使在MongoDB中存储数据成为可能,并使mongod在指定的秒数或特定的时钟时间后自动删除数据。
数据过期对于某些类型的信息非常有用,包括机器生成的事件数据、日志和会话信息,这些信息只需要持续一段有限的时间。
一个特殊的TTL索引属性支持TTL集合的实现。TTL特性依赖于mongod中的一个后台线程,该线程读取索引中日期类型的值并从集合中删除过期的文档。
2.1 程序
要创建TTL索引,可以使用db.collection.createIndex()方法和expireAfterSeconds选项来创建一个字段,该字段的值要么是一个日期,要么是一个包含日期值的数组。
请注意:
TTL索引是单个字段索引。复合索引不支持TTL属性。有关TTL索引的更多信息,请参见TTL索引。
可以使用collMod命令修改现有TTL索引的expireAfterSeconds。
2.1.1 在指定的秒数后过期文档
若要在索引字段之后经过指定的秒数后过期数据,请在保存BSON日期类型值或BSON日期类型对象数组的字段上创建TTL索引,并在expireAfterSeconds字段中指定一个正的非零值。当expireAfterSeconds字段中的秒数超过其索引字段中指定的时间后,文档将过期。[1]
例如,下面的操作在log_events集合的createdAt字段上创建一个索引,并指定3600的expireAfterSeconds值,将过期时间设置为createdAt指定时间之后的一个小时。
db.log_events.createIndex( { "createdAt": 1 }, { expireAfterSeconds: 3600 } )向log_events集合添加文档时,将createdAt字段设置为当前时间:
db.log_events.insert( {
"createdAt": new Date(),
"logEvent": 2,
"logMessage": "Success!"
} )当文档的createdAt值[1]大于expireAfterSeconds中指定的秒数时,MongoDB将自动从log_events集合中删除文档。
【1】(1,2)如果字段包含一个BSON日期类型对象的数组,那么如果至少有一个BSON日期类型对象比expireAfterSeconds中指定的秒数更早,则数据过期。
2.1.2 在特定的时钟时间过期文档
要在特定的时钟时间使文档过期,首先在一个字段上创建TTL索引,该字段保存BSON日期类型的值或BSON日期类型对象的数组,并指定expireAfterSeconds值为0。对于集合中的每个文档,将索引的日期字段设置为与文档到期时间对应的值。如果索引的日期字段包含过去的日期,则MongoDB认为该文档已过期。
例如,下面的操作在log_events集合的expireAt字段上创建一个索引,并指定expireAfterSeconds值为0:
db.log_events.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 0 } )对于每个文档,将expireAt的值设置为对应于文档到期的时间。例如,下面的insert()操作添加了一个应该在2013年7月22日1400:00到期的文档。
db.log_events.insert( {
"expireAt": new Date('July 22, 2013 14:00:00'),
"logEvent": 2,
"logMessage": "Success!"
} )当文档的expireAt值大于expireAfterSeconds中指定的秒数时,MongoDB将自动从log_events集合中删除文档,在本例中为0秒。因此,数据在指定的expireAt值处过期。
3. 唯一索引
唯一索引可确保索引字段不会存储重复值;即对索引字段实施唯一性。默认情况下, 在创建集合期间,MongoDB在_id字段上创建唯一索引。
新的内部格式:
从MongoDB 4.2开始,对于4.2(或更高版本)的featureCompatibilityVersion(fCV),MongoDB使用新的内部格式来存储与早期MongoDB版本不兼容的唯一索引。新格式适用于现有的唯一索引以及新创建/重建的唯一索引。
3.1 创建唯一索引
要创建惟一的索引,请使用db.collection.createIndex()方法,并将惟一选项设置为true。
db.collection.createIndex( <key and index type specification>, { unique: true } )3.1.1 单个字段上的唯一索引
例如,要在成员集合的user_id字段上创建惟一的索引,请在mongo shell中使用以下操作:
db.members.createIndex( { "user_id": 1 }, { unique: true } )3.1.2 独特的复合索引
您还可以对复合索引强制一个惟一的约束。如果您对一个复合索引使用惟一约束,那么MongoDB将对索引键值的组合强制惟一性。
例如,要在成员集合的groupNumber、lastname和firstname字段上创建惟一的索引,请在mongo shell中使用以下操作:
db.members.createIndex( { groupNumber: 1, lastname: 1, firstname: 1 }, { unique: true } )创建的索引对groupNumber、lastname和firstname值的组合强制惟一性。
另一个例子,考虑一个具有以下文档的集合:
{ _id: 1, a: [ { loc: "A", qty: 5 }, { qty: 10 } ] }在a上创建唯一的复合多键索引。loc a.qty:
db.collection.createIndex( { "a.loc": 1, "a.qty": 1 }, { unique: true } )惟一索引允许将下列文档插入到集合中,因为索引对a的组合强制惟一性。疯狂的和。数量值:
db.collection.insert( { _id: 2, a: [ { loc: "A" }, { qty: 5 } ] } )
db.collection.insert( { _id: 3, a: [ { loc: "A", qty: 10 } ] } )3.2 表现
3.2.1 限制
如果集合已经包含了违反索引唯一约束的数据,MongoDB就不能在指定的索引字段上创建唯一索引。
您不能在散列索引上指定唯一的约束。
3.2.2 在复制集和分片集群上构建惟一索引
对于复制集和分片集群,使用滚动过程来创建惟一的索引要求在此过程中停止对集合的所有写操作。如果在过程中无法停止对集合的所有写操作,则不要使用滚动过程。相反,建立你的唯一索引的集合:
- 对于复制集,在主节点上发布db.collection.createIndex(),
- 对于切分集群,在mongos上发布db.collection.createIndex()。
3.2.3 跨不同文档的唯一约束
唯一约束适用于集合中的单独文档。也就是说,惟一索引防止不同的文档对索引键使用相同的值。
因为该约束适用于单独的文档,所以对于惟一的多键索引,只要该文档的索引键值不重复另一个文档的索引键值,文档就可能有导致重复索引键值的数组元素。在本例中,重复索引项仅插入索引一次。
例如,考虑一个包含以下文档的集合:
{ _id: 1, a: [ { loc: "A", qty: 5 }, { qty: 10 } ] }
{ _id: 2, a: [ { loc: "A" }, { qty: 5 } ] }
{ _id: 3, a: [ { loc: "A", qty: 10 } ] }创建唯一的复合多键索引a.loc和a.qty:
db.collection.createIndex( { "a.loc": 1, "a.qty": 1 }, { unique: true } )如果集合中没有其他文档的索引键值为{"a ",则惟一索引允许将以下文档插入集合中。loc”:“B”、“a。数量”:零}。
如果在集合中没有其它的文档有索引键值为{ "a.loc": "B", "a.qty": null },则惟一索引允许将以下文档插入到集合中:
db.collection.insert( { _id: 4, a: [ { loc: "B" }, { loc: "B" } ] } )3.2.4 唯一索引和缺失字段
如果文档在唯一索引中没有索引字段的值,那么该索引将为该文档存储一个空值。由于惟一的约束,MongoDB只允许一个缺少索引字段的文档。如果有多个文档没有索引字段的值,或者缺少索引字段,那么索引构建将失败,并出现重复键错误。
例如,一个集合在x上有一个唯一的索引:
db.collection.createIndex( { "x": 1 }, { unique: true } )唯一索引允许插入一个没有字段x的文档,如果集合没有包含一个缺少字段x的文档:
db.collection.insert( { y: 1 } )但是,如果集合中已经包含一个缺少字段x的文档,那么在插入没有字段x的文档时出现惟一索引错误:
db.collection.insert( { z: 1 } )由于违反了字段x值的唯一约束,操作无法插入文档:
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 11000,
"errmsg" : "E11000 duplicate key error index: test.collection.$a.b_1 dup key: { : null }"
}
})3.2.5 独特的部分指标
新版本3.2。
只对满足指定筛选器表达式的集合中的文档进行部分索引。如果同时指定partialFilterExpression和惟一约束,则惟一约束仅适用于满足筛选器表达式的文档。
带有唯一约束的部分索引并不阻止在文档不满足筛选条件时插入不满足唯一约束的文档。有关示例,请参见具有唯一约束的部分索引。
3.2.6 分片集群和惟一索引
不能在散列索引上指定唯一的约束。
对于范围分片集合,只有以下索引是惟一的:
- 碎片键上的索引
- 以碎片键为前缀的复合索引
- 默认的_id索引;但是,如果_id字段不是碎片键或碎片键的前缀,则_id索引只对每个碎片强制唯一性约束。
惟一性和_ID索引:
如果_id字段不是分片键或分片键的前缀,则_id索引只对每个分片强制唯一性约束,而不是跨分片强制唯一性约束。
例如,考虑一个分片收集(用钥匙碎片{x: 1}),横跨两个碎片a和B,因为_id关键不是碎片关键的一部分,收集可能_id值1的文档碎片和_id值1的另一个文档碎片B。
如果_id字段不是分片键,也不是分片键的前缀,MongoDB期望应用程序强制执行_id值ac的唯一性
唯一索引约束意味着:
- 对于要切分的集合,如果集合具有其他惟一索引,则不能对该集合进行切分。
- 对于已切分的集合,不能在其他字段上创建惟一索引。
4. 部分索引
新版本3.2。
只对满足指定筛选器表达式的集合中的文档进行部分索引。通过为集合中的一个文档子集建立索引,部分索引具有更低的存储需求,并降低了索引创建和维护的性能成本。
4.1 创建部分索引
要创建部分索引,请使用带有partialFilterExpression选项的db.collection.createIndex()方法。partialFilterExpression选项接受一个文档,该文档使用以下命令指定过滤条件:
例如,下面的操作创建一个复合索引,该索引仅对评级字段大于5的文档进行索引。
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)您可以为所有的MongoDB索引类型指定一个partialFilterExpression选项。
4.1 表现
4.1.1 查询范围
如果使用索引会导致不完整的结果集,MongoDB将不会对查询或排序操作使用部分索引。
要使用部分索引,查询必须包含筛选器表达式(或指定筛选器表达式子集的修改筛选器表达式)作为其查询条件的一部分。
例如,给定如下索引:
db.restaurants.createIndex(
{ cuisine: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)下面的查询可以使用索引,因为查询谓词包括条件评级:{$gte: 8},它匹配由索引筛选器表达式评级:{$gt: 5}匹配的文档子集:
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )但是,下面的查询不能使用cuisine字段上的部分索引,因为使用索引会导致不完整的结果集。具体来说,查询谓词包括条件评级:{$lt: 8},而索引有过滤评级:{$gt: 5}。也就是说,查询{cuisine:“Italian”,rating: {$lt: 8}匹配的文档(例如,评级为1的意大利餐厅)比索引的要多。
db.restaurants.find( { cuisine: "Italian", rating: { $lt: 8 } } )类似地,下面的查询不能使用部分索引,因为查询谓词不包含筛选器表达式,使用索引将返回不完整的结果集。
db.restaurants.find( { cuisine: "Italian" } )4.1.2 与稀疏索引比较
提示:
部分索引表示稀疏索引提供的功能的超集,应该优先于稀疏索引。
与稀疏索引相比,部分索引提供了一种更具表达性的机制,可以通过索引来指定要索引哪些文档。
稀疏索引仅根据索引字段的存在来选择文档进行索引,对于复合索引,则根据索引字段的存在进行索引。
部分索引根据指定的筛选器确定索引项。筛选器可以包含索引键以外的字段,并且可以指定存在性检查之外的条件。例如,部分索引可以实现与稀疏索引相同的行为:
db.contacts.createIndex(
{ name: 1 },
{ partialFilterExpression: { name: { $exists: true } } }
)这个部分索引支持与name字段上的稀疏索引相同的查询。
但是,部分索引还可以在索引键之外的字段上指定筛选器表达式。例如,下面的操作创建一个部分索引,其中索引在name字段上,而筛选器表达式在email字段上:
db.contacts.createIndex(
{ name: 1 },
{ partialFilterExpression: { email: { $exists: true } } }
)为了让查询优化器选择这个部分索引,查询谓词必须在name字段上包含一个条件,并在email字段上包含一个非空匹配。
例如,下面的查询可以使用索引,因为它既包含name字段上的条件,也包含email字段上的非空匹配:
db.contacts.find( { name: "xyz", email: { $regex: /\.org$/ } } )但是,下面的查询不能使用索引,因为它在email字段上包含一个空匹配,这是过滤器表达式{email: {$exists: true}}不允许的:
db.contacts.find( { name: "xyz", email: { $exists: false } } )4.2 限制
在MongoDB中,您不能创建仅在选项上不同的索引的多个版本。因此,您不能创建仅因筛选器表达式而不同的多个部分索引。
您不能同时指定partialFilterExpression选项和sparse选项。
MongoDB 3.0或更早版本不支持部分索引。要使用部分索引,必须使用MongoDB 3.2或更高版本。对于分片集群或副本集,所有节点都必须是3.2或更高版本。
_id索引不能是部分索引。
切分键索引不能是部分索引。
4.3 例子
4.3.1 在集合上创建部分索引
考虑一个包含类似于以下文档的集合餐厅
{
"_id" : ObjectId("5641f6a7522545bc535b5dc9"),
"address" : {
"building" : "1007",
"coord" : [
-73.856077,
40.848447
],
"street" : "Morris Park Ave",
"zipcode" : "10462"
},
"borough" : "Bronx",
"cuisine" : "Bakery",
"rating" : { "date" : ISODate("2014-03-03T00:00:00Z"),
"grade" : "A",
"score" : 2
},
"name" : "Morris Park Bake Shop",
"restaurant_id" : "30075445"
}您可以在行政区和烹饪领域添加部分索引,只选择索引评级的文档。等级字段为A:
db.restaurants.createIndex(
{ borough: 1, cuisine: 1 },
{ partialFilterExpression: { 'rating.grade': { $eq: "A" } } }
)然后,以下针对餐馆集合的查询使用部分索引返回带有评级的布朗克斯区餐馆。等于A级:
db.restaurants.find( { borough: "Bronx", 'rating.grade': "A" } )但是,以下查询不能使用部分索引,因为查询表达式不包含评级。等级:
db.restaurants.find( { borough: "Bronx", cuisine: "Bakery" } )4.3.2 带唯一约束的部分索引
只对满足指定筛选器表达式的集合中的文档进行部分索引。如果同时指定partialFilterExpression和惟一约束,则惟一约束仅适用于满足筛选器表达式的文档。带有唯一约束的部分索引并不阻止在文档不满足筛选条件时插入不满足唯一约束的文档。
例如,一个集合用户包含以下文档:
{ "_id" : ObjectId("56424f1efa0358a27fa1f99a"), "username" : "david", "age" : 29 }
{ "_id" : ObjectId("56424f37fa0358a27fa1f99b"), "username" : "amanda", "age" : 35 }
{ "_id" : ObjectId("56424fe2fa0358a27fa1f99c"), "username" : "rajiv", "age" : 57 }下面的操作创建一个索引,该索引指定用户名字段上的唯一约束和一个部分筛选器表达式age: {$gte: 21}。
db.users.createIndex(
{ username: 1 },
{ unique: true, partialFilterExpression: { age: { $gte: 21 } } }
)索引防止插入以下文档,因为已经存在具有指定用户名且年龄字段大于21的文档:
db.users.insert( { username: "david", age: 27 } )
db.users.insert( { username: "amanda", age: 25 } )
db.users.insert( { username: "rajiv", age: 32 } )但是,由于惟一约束只适用于年龄大于或等于21岁的文档,所以允许使用重复用户名的文档。
db.users.insert( { username: "david", age: 20 } )
db.users.insert( { username: "amanda" } )
db.users.insert( { username: "rajiv", age: null } )5.不分大小写索引
新版本3.4。
不区分大小写的索引支持执行不考虑大小写的字符串比较的查询。
可以使用db.collection.createIndex()创建不区分大小写的索引,方法是将排序规则参数指定为一个选项。例如:
db.collection.createIndex( { "key" : 1 },
{ collation: {
locale : <locale>,
strength : <strength>
}
} )要为区分大小写的索引指定排序规则,请包括:
- locale:指定语言规则。有关可用区域列表,请参见“排序区域”。
- strength:决定比较规则。值1或2表示不区分大小写的排序规则。
5.1 行为
使用大小写不敏感的索引不会影响查询的结果,但可以提高性能;有关索引的成本和收益的详细讨论,请参见索引。
要使用指定排序规则的索引,查询和排序操作必须指定与索引相同的排序规则。如果集合定义了排序规则,所有查询和索引都将继承该排序规则,除非它们显式地指定了不同的排序规则。
5.2 例子
5.2.1 创建不区分大小写的索引
若要在没有默认排序规则的集合上使用不区分大小写的索引,请创建具有排序规则的索引,并将强度参数设置为1或2(有关强度参数的详细描述,请参见排序规则)。要使用索引级排序规则,必须在查询级指定相同的排序规则。
下面的示例创建一个没有默认排序规则的集合,然后在type字段上添加一个不区分大小写的排序规则索引。
db.createCollection("fruit")
db.fruit.createIndex( { type: 1},
{ collation: { locale: 'en', strength: 2 } } )要使用索引,查询必须指定相同的排序规则。
db.fruit.insert( [ { type: "apple" },
{ type: "Apple" },
{ type: "APPLE" } ] )
db.fruit.find( { type: "apple" } ) // does not use index, finds one result
db.fruit.find( { type: "apple" } ).collation( { locale: 'en', strength: 2 } )
// uses the index, finds three results
db.fruit.find( { type: "apple" } ).collation( { locale: 'en', strength: 1 } )
// does not use the index, finds three results5.2.2 具有默认排序规则的集合上的不区分大小写索引
当您创建一个具有默认排序规则的集合时,您随后创建的所有索引都将继承该排序规则,除非您指定了不同的排序规则。没有指定不同排序规则的所有查询也继承默认排序规则。
下面的示例使用默认排序规则创建名为names的集合,然后在first_name字段上创建索引。
db.createCollection("names", { collation: { locale: 'en_US', strength: 2 } } )
db.names.createIndex( { first_name: 1 } ) // inherits the default collation插入一小组名称:
db.names.insert( [ { first_name: "Betsy" },
{ first_name: "BETSY"},
{ first_name: "betsy"} ] )此集合上的查询默认使用指定的排序规则,如果可能,也使用索引。
db.names.find( { first_name: "betsy" } )
// inherits the default collation: { collation: { locale: 'en_US', strength: 2 } }
// finds three results上面的操作使用集合的默认排序规则并查找所有三个文档。它使用first_name字段上的索引以获得更好的性能。
通过在查询中指定不同的排序规则,仍然可以对这个集合执行区分大小写的搜索:
db.names.find( { first_name: "betsy" } ).collation( { locale: 'en_US' } )
// does not use the collection's default collation, finds one result上面的操作只找到一个文档,因为它使用了一个没有指定强度值的排序规则。它不使用集合的默认排序规则或索引。
6.稀疏索引
稀疏索引仅包含具有索引字段的文档的条目,即使索引字段包含空值。索引跳过任何缺少索引字段的文档。索引是“稀疏的”,因为它不包括一个集合的所有文档。相反,非稀疏索引包含一个集合中的所有文档,为那些不包含索引字段的文档存储空值。
重要的:
版本3.2中的变化:从MongoDB 3.2开始,MongoDB提供了创建部分索引的选项。部分索引提供了稀疏索引功能的超集。如果您使用的是MongoDB 3.2或更高版本,应该优先选择部分索引,而不是稀疏索引。
6.1创建一个稀疏索引
若要创建稀疏索引,请使用db.collection.createIndex()方法,并将稀疏选项设置为true。例如,mongo shell中的以下操作在地址集合的xmpp_id字段上创建一个稀疏索引:
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )索引不索引不包含xmpp_id字段的文档。
请注意:
不要将MongoDB中的稀疏索引与其他数据库中的块级索引混淆。可以将它们看作带有特定过滤器的密集索引。
6.2 行为
6.2.1稀疏指数和不完整的结果
如果稀疏索引会导致查询和排序操作的结果集不完整,MongoDB将不会使用该索引,除非hint()显式地指定了索引。
例如,查询{x: {$exists: false}不会在x字段上使用稀疏索引,除非有明确的提示。有关详细说明行为的示例,请参阅集合上的稀疏索引无法返回完整结果。
在3.4版本中进行了更改。
如果在执行集合中所有文档的count()(即使用空查询谓词)时包含一个hint(),它指定一个稀疏索引,那么即使稀疏索引导致一个不正确的计数,也会使用稀疏索引。
db.collection.insert({ _id: 1, y: 1 } );
db.collection.createIndex( { x: 1 }, { sparse: true } );
db.collection.find().hint( { x: 1 } ).count();要获得正确的计数,在对集合中的所有文档进行计数时,不要使用稀疏索引提示()。
db.collection.find().count();
db.collection.createIndex({ y: 1 });
db.collection.find().hint({ y: 1 }).count();6.2.2 默认为稀疏的索引
2dsphere(版本2)、2d、geoHaystack和文本索引总是稀疏的。
6.2.3 稀疏的复合索引
只包含升序/降序索引键的稀疏复合索引将索引一个文档,只要该文档包含至少一个键。
对于包含地理空间键(即2dsphere、2d或geoHaystack索引键)和升序/降序索引键的稀疏复合索引,只有文档中地理空间字段的存在才能决定索引是否引用文档。
对于包含文本索引键和升序/降序索引键的稀疏复合索引,只有文本索引字段的存在才能确定索引是否引用文档。
6.2.4 稀疏性和唯一性
同时具有稀疏性和唯一性的索引可以防止集合中出现具有重复字段值的文档,但允许多个文档省略该键。
6.3 例子
6.3.1 在集合上创建一个稀疏索引
考虑包含以下文档的集合分数:
{ "_id" : ObjectId("523b6e32fb408eea0eec2647"), "userid" : "newbie" }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }集合在字段得分上有一个稀疏的索引:
db.scores.createIndex( { score: 1 } , { sparse: true } )然后,下面针对分数集合的查询使用稀疏索引返回分数字段小于($lt) 90的文档:
db.scores.find( { score: { $lt: 90 } } )因为userid“newbie”的文档不包含score字段,因此不符合查询条件,所以查询可以使用稀疏索引来返回结果:
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }6.3.2 集合上的稀疏索引不能返回完整的结果
考虑包含以下文档的集合分数:
{ "_id" : ObjectId("523b6e32fb408eea0eec2647"), "userid" : "newbie" }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }集合在字段得分上有一个稀疏的索引:
db.scores.createIndex( { score: 1 } , { sparse: true } )因为userid“newbie”的文档不包含分数字段,所以稀疏索引不包含该文档的条目。
考虑以下查询来返回score集合中的所有文档,按score字段排序:
db.scores.find().sort( { score: -1 } )即使排序是通过索引字段,MongoDB也不会选择稀疏索引来完成查询,以返回完整的结果:
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }
{ "_id" : ObjectId("523b6e32fb408eea0eec2647"), "userid" : "newbie" }要使用稀疏索引,请使用hint()显式指定索引:
db.scores.find().sort( { score: -1 } ).hint( { score: 1 } )使用索引只会返回带有score字段的文档:
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }6.3.3 具有唯一约束的稀疏索引
考虑包含以下文档的集合分数:
{ "_id" : ObjectId("523b6e32fb408eea0eec2647"), "userid" : "newbie" }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }您可以创建一个索引与唯一的约束和稀疏过滤器的得分字段使用以下操作:
db.scores.createIndex( { score: 1 } , { sparse: true, unique: true } )这个索引将允许插入对于score字段具有唯一值的文档,或者不包含score字段的文档。因此,对于score集合中的现有文档,索引允许进行以下插入操作:
db.scores.insert( { "userid": "AAAAAAA", "score": 43 } )
db.scores.insert( { "userid": "BBBBBBB", "score": 34 } )
db.scores.insert( { "userid": "CCCCCCC" } )
db.scores.insert( { "userid": "DDDDDDD" } )但是,该指数不允许增加下列文件,因为已经存在的文件得分为82和90:
db.scores.insert( { "userid": "AAAAAAA", "score": 82 } )
db.scores.insert( { "userid": "BBBBBBB", "score": 90 } )十二、索引建立在已填充的集合上
版本MongoDB的变化:4.2
针对已填充的集合构建MongoDB索引时,需要对集合使用独占读写锁。需要对集合执行读或写锁的操作必须等待mongod释放锁。MongoDB 4.2使用了一个优化的构建过程,它只在索引构建的开始和结束时持有独占锁。构建过程的其余部分将转化为交叉的读和写操作。
构建过程总结如下:
a.初始化
mongod对被索引的集合采取独占锁。这将阻塞对集合的所有读写操作,直到mongod释放锁。应用程序在此期间无法访问集合。
b.数据摄取和处理
mongod在对被索引的集合执行一系列意图锁之前,释放由索引构建过程获取的所有锁。在此期间,应用程序可以对集合发出读和写操作。
c.清理
mongod在对被索引的集合使用排他锁之前,释放所有由索引构建过程获取的锁。这将阻塞对集合的所有读写操作,直到mongod释放锁。应用程序在此期间无法访问集合。
d.完成
mongod将索引标记为可以使用,并释放由索引构建过程获取的所有锁。
有关索引构建锁定行为的详细描述,请参见索引构建过程。有关MongoDB锁行为的更多信息,请参见FAQ: Concurrency。
1.1 行为
MongoDB 4.2的索引构建完全取代了以前MongoDB版本中支持的索引构建过程。如果指定createIndexes或其shell帮助程序createIndex()和createIndexes(), MongoDB将忽略后台索引构建选项。
需要FEATURECOMPATIBILITYVERSION 4.2:
对于从4.0升级到4.2的MongoDB集群,必须将特性兼容性版本(fcv)设置为4.2才能启用优化的构建过程。有关fCV设置的更多信息,请参见setFeatureCompatibilityVersion。
运行fCV 4.0的MongoDB 4.2集群只支持4.0索引构建。
1.1.1 与前台和后台构建进行比较
以前的MongoDB版本支持在前台或后台构建索引。前台索引构建非常快,并且生成了更高效的索引数据结构,但是需要在构建期间阻塞对被索引的集合的父数据库的所有读写访问。后台索引构建速度较慢,效率也较低,但是在构建过程中允许对数据库及其集合进行读写访问。
版本MongoDB的变化:4.2
在构建过程的开始和结束阶段,索引构建仅对被索引的集合获取独占锁,以保护元数据的更改。构建过程的其余部分使用后台索引构建的生成行为,以便在构建期间最大化对集合的读写访问。4.2尽管有更宽松的锁定行为,但索引构建仍然可以生成高效的索引数据结构。
索引构建的性能至少与后台索引构建相当。对于构建过程中很少或没有收到更新的工作负载,4.2索引构建构建可以与基于相同数据的前台索引构建一样快。
使用db.currentOp()来监视正在进行的索引构建的进度。
1.1.2 在索引构建期间违反约束
对于那些对集合施加约束的索引,比如惟一索引,mongod会在索引构建完成后检查所有已存在的和并发编写的文档,看看是否违反了这些约束。违反索引约束的文档可以在索引构建期间存在。如果任何文档在构建结束时违反了索引约束,mongod将终止构建并抛出一个错误。
例如,考虑一个已填充的集合库存。管理员希望在product_sku字段上创建惟一的索引。如果集合中的任何文档具有product_sku的重复值,那么索引构建仍然可以成功启动。如果在构建结束时仍然存在任何违反,mongod将终止构建并抛出一个错误。
类似地,在索引构建过程中,应用程序可以使用product_sku的重复值成功地将文档写入库存集合。如果在构建结束时仍然存在任何违反,mongod将终止构建并抛出一个错误。
为了减少由于违反约束而导致索引构建失败的风险:
- 验证集合中没有文档违反索引约束。
- 停止无法保证无冲突写操作的应用程序对集合的所有写操作。
1.2 索引构建对数据库性能的影响
1.2.1 在写大量工作负载时构建索引
在目标集合处于高写负载下的时间段构建索引会导致写性能下降和更长的索引构建。
考虑指定一个维护窗口,在此期间应用程序停止或减少对集合的写操作。在此维护窗口期间启动索引构建,以减轻构建过程的潜在负面影响。
1.2.2 可用系统内存(RAM)不足
createIndexes支持在一个集合上构建一个或多个索引。createIndexes使用内存和磁盘上临时文件的组合来完成索引构建。createIndexes的默认内存使用限制是500 mb,在使用一个createIndexes命令构建的所有索引之间共享。达到内存限制后,createIndexes使用——dbpath目录中名为_tmp的子目录中的临时磁盘文件来完成构建。
您可以通过设置maxIndexBuildMemoryUsageMegabytes服务器参数来覆盖内存限制。设置更高的内存限制可能导致更快地完成大于500兆字节的索引构建。但是,与系统中未使用的RAM相比,将此限制设置得过高可能会导致内存错误。
如果主机有有限的可用空闲RAM,在修改mongod RAM的使用之前,您可能需要安排一个维护周期来增加整个系统RAM。
1.3 在复制环境中构建索引
为了尽量减少建立索引的影响:
- 复制集,使用在复制集上构建索引中描述的滚动索引构建过程。
- 使用碎片复制集的分片集群,使用在分片集群上构建索引中描述的滚动索引构建过程。
您也可以在主服务器上启动索引构建。索引构建完成后,二级服务器复制并开始索引构建。在开始复制索引构建之前,请考虑以下风险:
1.3.1 二级市场可能会失去同步
如果事务包含对被索引的集合的写操作,则二级索引构建将阻塞sharded集群上复制事务的应用程序。类似地,针对被索引的集合的复制元数据操作也会在索引构建之后停止。在索引构建完成之前,mongod不能应用任何进一步的oplog条目。
如果索引构建在操作或命令时持有排他锁,则对被索引的集合的复制写操作也会在索引构建后停止。在索引构建释放独占锁之前,mongod不能应用任何进一步的oplog条目。如果该辅助服务器上的复制停止时间长于oplog窗口,则该辅助服务器将失去同步,需要重新同步才能恢复。
在每个复制集成员上使用rs.printReplicationInfo()来验证在开始索引构建之前为该成员配置的oplog大小所覆盖的时间。您可以增加oplog的大小来降低二次不同步的可能性。例如,设置一个可以覆盖72小时操作的oplog窗口大小,可以确保次要服务器至少能够忍受那么多的复制延迟。
或者,在应用程序停止发出分布式事务、写操作或影响被索引的集合的元数据命令的维护窗口期间构建索引。
1.3.2 二级索引构建可能会导致读写操作停滞
MongoDB 4.2索引构建在构建过程的开始和结束时获得对被索引的集合的独占锁。虽然二级索引构建持有独占锁,但是在构建释放该锁之前,依赖于二级失速的任何读或写操作。
1.3.3 二级进程索引在索引构建完成后下降
在二级服务器完成复制的索引构建之前删除主服务器上的索引并不会终止二级服务器上的索引构建。当二级复制索引删除时,它必须等到索引构建完成后才能应用删除。此外,由于索引删除是集合上的元数据操作,所以索引删除会阻止在该辅助服务器上的复制。
1.4 构建失败和恢复
1.4.1 中断索引建立在独立的mongod上
如果mongod在索引构建期间关闭,则索引构建作业和所有进展都将丢失。重新启动mongod不会重新启动索引构建。您必须重新发出createIndex()操作来重新启动索引构建。
1.4.2 中断索引建立在主mongod上
如果主服务器在索引构建期间关闭或关闭,则索引构建作业和所有进展都将丢失。重新启动mongod不会重新启动索引构建。您必须重新发出createIndex()操作来重新启动索引构建。
1.4.3 中断索引建立在二级mongod上
如果二级服务器在索引构建期间关闭,则索引构建作业将被持久化。重新启动mongod恢复索引构建并从头开始。
启动过程在任何恢复的索引构建之后都会停止。所有其他操作,包括复制,都要等到索引构建完成。如果辅助服务器的oplog没有覆盖完成索引构建所需的时间,则辅助服务器可能与复制集的其余部分不同步,需要重新同步。
如果您以独立的方式重新启动mongod(即删除或注释掉复制)。(replSetName或省略——replSetName), mongod仍然可以从头恢复索引构建。你可以使用存储。indexBuildRetry配置文件设置或——noIndexBuildRetry命令行选项,用于在启动时跳过索引构建。
MONGODB 4.0 +
不能指定存储。indexBuildRetry或——noIndexBuildRetry用于一个mongod,它是一个副本集的一部分。
1.4.4 构建过程中的回滚
从4.0版本开始,MongoDB在开始回滚之前会等待任何正在进行的索引构建完成。
1.5 监视正在构建的索引
要查看索引构建操作的状态,可以使用mongo shell中的db.currentOp()方法。若要筛选索引创建操作的当前操作,请参阅活动索引操作的示例。
msg字段包括索引构建过程中当前阶段的百分比完整度量。
1.6 在构建进度索引时终止
若要终止在主mongod或独立mongod上构建的正在进行的索引,请使用mongo shell中的db.killOp()方法。在终止索引构建时,db.killOp()的影响可能不会立即出现,而且可能在大部分索引构建操作完成后很久才出现。
不能在复制集的次要成员上终止复制的索引构建。必须首先删除主要成员上的索引。二级服务器将复制drop操作,并在索引构建完成后删除索引。在索引构建和删除之后的所有其他复制块。
要最小化在复制集和带有复制集碎片的分片集群上构建索引的影响,请参见:
1.7 指数的构建过程
下表描述了索引构建过程的各个阶段:
| Stage | Description |
|---|---|
| Lock | mongod在被索引的集合上获得一个独占的X锁。这将阻塞集合上的所有读写操作,包括针对集合的任何复制写操作或元数据命令的应用程序。mongod没有交出这把锁。 |
| Initialization | mongod在初始状态下创建三个数据结构:
|
| Lock | mongod将独占的X收集锁降级为一个意图独占的IX锁。mongod周期性地将这个锁转换为交叉的读写操作。 |
| Scan Collection | 对于集合中的每个文档,mongod为该文档生成一个键,并将该键转储到外部排序器中。 如果mongod在收集扫描期间生成密钥时遇到重复的密钥错误,它会将该密钥存储在约束违反表中,以供以后处理。 如果mongod在生成密钥时遇到任何其他错误,则构建将失败并出现错误。 mongod完成收集扫描后,将排序后的键转储到索引中。 |
| 进程端写表 | mongod使用先进先出的优先级对侧写表进行排水。 如果mongod在处理侧写表中的键时遇到重复的键错误,它会将该键存储在约束违反表中,以供以后处理。 如果mongod在处理密钥时遇到任何其他错误,则构建将失败并出现错误。 对于在构建过程中写入到集合中的每个文档,mongod将为该文档生成一个键,并将其存储在侧写表中,供以后处理。mongod使用快照系统来设置要处理的键的数量限制。 |
| Lock | mongod将集合上的专用IX锁升级为共享S锁。这将阻塞对集合的所有写操作,包括针对集合的任何复制的写操作或元数据命令的应用程序。 |
| 完成处理临时边写表 | mongod继续耗尽侧写表中的剩余记录。mongod可能会在此阶段暂停复制。 如果mongod在处理侧写表中的键时遇到重复的键错误,它会将该键存储在约束违反表中,以供以后处理。 如果mongod在处理密钥时遇到任何其他错误,则构建将失败并出现错误。 |
| Lock | mongod将集合上的共享S锁升级为集合上的独占X锁。这将阻塞集合上的所有读写操作,包括针对集合的任何复制写操作或元数据命令的应用程序。mongod没有交出这把锁。 |
| Drop Side Write Table | mongod在删除边写表之前应用它的所有剩余操作。 如果mongod在处理侧写表中的键时遇到重复的键错误,它会将该键存储在约束违反表中,以供以后处理。 如果mongod在处理密钥时遇到任何其他错误,则构建将失败并出现错误。 此时,索引包括写入集合的所有数据。 |
| 流程约束违反表 | mongod使用先进先出优先级抽干约束违反表。然后mongod放下了桌子。 如果约束冲突表中的任何键仍然产生一个重复的键错误,mongod将中止构建并抛出一个错误。 mongod一旦耗尽约束冲突表,或者在处理过程中遇到重复的密钥冲突,就会放弃约束冲突表。 |
| 将索引标记为Ready | mongod更新索引元数据,将索引标记为可以使用。 |
| Lock | mongod释放了集合上的X锁。 |
2. 在复制集上构建索引
要最小化构建索引对复制集部署的影响,请使用以下过程以滚动方式构建索引。要在sharded集群上构建索引,请参见在sharded集群上构建索引。
下面的复制集部署过程一次只从复制集中取出一个成员。但是,这个过程一次只影响集合中的一个成员,而不是同时影响所有的附属国。
2.1 注意事项
2.1.1 唯一索引
要使用以下过程创建惟一的索引,您必须在此过程中停止对集合的所有写操作。
如果在此过程中无法停止对集合的所有写操作,请不要在此页面上使用此过程。相反,通过在复制集的主节点上发出db.collection.createIndex(),在集合上构建惟一的索引。
2.1.2 Oplog大小
确保您的oplog足够大,可以完成索引或重新索引操作,而不会落后太远而无法赶上。有关更多信息,请参阅oplog分级文档。
2.2 先决条件
2.2.1 用于构建惟一索引
要使用以下过程创建惟一的索引,您必须在索引构建期间停止对集合的所有写操作。否则,您可能会在副本集成员之间得到不一致的数据。
警告:
如果无法停止对集合的所有写操作,请不要使用以下过程来创建惟一索引。
2.3 过程
重要的
以下以滚动方式构建索引的过程适用于复制集部署,而不是切分集群。有关使用复制集碎片构建分片集群的过程,请参见在分片集群上构建索引。
2.3.1 A .停止一个备用服务器并作为独立服务器重新启动
停止与次要服务器关联的mongod进程。进行以下配置更新后重新启动:
(1)配置文件形式
如果您正在使用配置文件,请进行以下配置更新:
- 注释掉replication.replSetName选项。
- 改变net.port到一个不同的端口。[1]将原始端口设置作为注释记录下来。
- 在setParameter部分将参数disableLogicalSessionCacheRefresh设置为true。
例如,一个复制集成员的更新配置文件将包括如下内容:
net:
bindIp: localhost,<hostname(s)|ip address(es)>
port: 27217
# port: 27017
#replication:
# replSetName: myRepl
setParameter:
disableLogicalSessionCacheRefresh: true其他设置(如储存)。dbPath等)保持不变。
并重新启动:
mongod --config <path/To/ConfigFile>(1,2)通过在不同的端口上运行mongod,可以确保在构建索引时,复制集的其他成员和所有客户端不会与该成员联系。
(2) 以命令行的形式进行配置:
如果使用命令行选项,进行以下配置更新:
- 删除--复制集。
- 修改--端口到另一个端口。[1]
- 在setParameter选项中,将参数disableLogicalSessionCacheRefresh设置为true。
例如,如果您的复制集成员通常运行在默认端口27017和--replSet选项上,您将指定一个不同的端口,省略--replSet选项,并将disableLogicalSessionCacheRefresh参数设置为true:
mongod --port 27217 --setParameter disableLogicalSessionCacheRefresh=true其他设置(例如——dbpath等)保持不变。
(1,2)通过在不同的端口上运行mongod,可以确保在构建索引时,复制集的其他成员和所有客户端不会与该成员联系。
2.3.2 B.建立索引
直接连接到在新端口上作为独立运行的mongod实例,并为该实例创建新索引。
例如,将mongo shell连接到实例,并使用createIndex()在记录集合的username字段上创建升序索引:
db.records.createIndex( { username: 1 } )2.3.3 C.作为复制集成员重新启动程序mongod
当索引构建完成时,关闭mongod实例。撤消在作为独立程序启动时所做的配置更改,以返回其原始配置并作为复制集的成员重新启动。
重要的:
请确保删除disableLogicalSessionCacheRefresh参数。
例如,要重新启动你的复制集成员:
(1)如果使用配置文件
如果你正在使用一个配置文件:
- 恢复到原来的端口号。
- 取消replication.replSetName。
- 在setParameter部分中删除参数disableLogicalSessionCacheRefresh。
举例:
net:
bindIp: localhost,<hostname(s)|ip address(es)>
port: 27017
replication:
replSetName: myRepl其他设置(如storage.dbPath等)保持不变。
并重新启动:
mongod --config <path/To/ConfigFile>允许复制赶上此成员。
(2)使用命令行配置
如果使用命令行选项,
- 恢复到原来的端口号
- 包括——replSet选项。
- 删除参数disableLogicalSessionCacheRefresh。
例如:
mongod --port 27017 --replSet myRepl其他设置(例如——dbpath等)保持不变。
允许复制赶上此成员。
2.3.4 D.对剩余的次要的重复上述步骤
一旦成员赶上了集合中的其他成员,对其余的次要成员一次重复一个成员的过程:
- a .停止一个备用服务器并作为独立服务器重新启动
- B.建立索引
- C.作为复制集成员重新启动程序mongod
2.3.5 E.在主服务器上构建索引
当所有次要服务器都有了新索引时,退出主服务器,使用上面描述的过程作为一个独立的程序重新启动它,并在前一个主服务器上构建索引:
- 使用mongo shell中的rs.stepDown()方法来逐步退出主进程。成功下步后,当前主服务器将成为一个辅助服务器,而复制集成员将选择一个新的主服务器。
- A .停止一个备用服务器并作为独立服务器重新启动
- B.建立索引
- C.作为复制集成员重新启动程序mongod
3. 在分片的集群上构建索引
要最小化使用复制集碎片在分片集群上构建索引的影响,请使用以下过程以滚动方式构建索引。若要在复制集部署上构建索引,请参阅在复制集上构建索引。
对于分片集群的部署,下面的过程一次只取出分片副本集的一个成员。但是,这一程序一次只影响一名成员,而不是同时影响所有的附属机构。
3.1 注意事项
3.1.1 唯一索引
要使用以下过程创建惟一的索引,您必须在此过程中停止对集合的所有写操作。
如果在此过程中无法停止对集合的所有写操作,请不要在此页面上使用此过程。相反,通过在mongos上为切分集群发布db.collection.createIndex(),在集合上构建惟一的索引。
3.1.2 Oplog大小
确保您的oplog足够大,可以完成索引或重新索引操作,而不会落后太远而无法赶上。有关更多信息,请参阅oplog分级文档。
3.2 先决条件
3.2.1 用于构建惟一索引
要使用以下过程创建惟一的索引,您必须在索引构建期间停止对集合的所有写操作。否则,您可能会在副本集成员之间得到不一致的数据。如果无法停止对集合的所有写操作,请不要使用以下过程来创建惟一索引。
警告:
如果无法停止对集合的所有写操作,请不要使用以下过程来创建惟一索引。
3.3 过程
A.停止平衡器
将一个mongo shell连接到切分集群中的mongos实例,并运行sh.stopBalancer()来禁用这个平衡器:[1]
sh.stopBalancer()请注意:
如果迁移正在进行中,系统将在停止平衡器之前完成正在进行的迁移。
要验证平衡器是否被禁用,可以运行sh.getBalancerState(),如果平衡器被禁用,它将返回false:
sh.getBalancerState()从MongoDB 4.2开始,sh.stopBalancer()也禁用了分片集群的自动分割。
B.确定集合的分布
从连接到mongos的mongo shell中,刷新该mongos的缓存路由表,以避免返回集合的陈旧分布信息。刷新后,为希望构建索引的集合运行db.collection.getShardDistribution()。
例如,如果您想对测试数据库中的记录集合执行升序索引:
db.adminCommand( { flushRouterConfig: "test.records" } );
db.records.getShardDistribution();该方法输出分片分布。例如,考虑一个包含3个切分shardA、shardB和shardC的切分集群,db.collection.getShardDistribution()返回以下内容:
Shard shardA at shardA/s1-mongo1.example.net:27018,s1-mongo2.example.net:27018,s1-mongo3.example.net:27018
data : 1KiB docs : 50 chunks : 1
estimated data per chunk : 1KiB
estimated docs per chunk : 50
Shard shardC at shardC/s3-mongo1.example.net:27018,s3-mongo2.example.net:27018,s3-mongo3.example.net:27018
data : 1KiB docs : 50 chunks : 1
estimated data per chunk : 1KiB
estimated docs per chunk : 50
Totals
data : 3KiB docs : 100 chunks : 2
Shard shardA contains 50% data, 50% docs in cluster, avg obj size on shard : 40B
Shard shardC contains 50% data, 50% docs in cluster, avg obj size on shard : 40B在输出中,您只构建用于测试的索引。关于shardA和shardC的记录。
C.在包含收集块的碎片上构建索引
对于包含集合块的每个碎片,按照以下步骤在碎片上构建索引。
C1.停止一个备用服务器并作为独立服务器重新启动
对于受影响的碎片,停止与其某个次要碎片关联的mongod进程。进行以下配置更新后重新启动:
(1)以配置文件的形式
如果您正在使用配置文件,请进行以下配置更新:
- 将net.port改成另一个端口。[2]将原始端口设置作为注释记录下来。
- 注释掉replication.replSetName选项。
- 注释掉sharding.clusterRole选项。
- 在setParameter部分将参数skipshardingconfigurationcheck(也适用于MongoDB 3.6.3+、3.4.11+、3.2.19+)设置为true。
- 在setParameter部分将参数disableLogicalSessionCacheRefresh设置为true。
例如,对于一个碎片复制集成员,更新后的配置文件将包含如下内容:
net:
bindIp: localhost,<hostname(s)|ip address(es)>
port: 27218
# port: 27018
#replication:
# replSetName: shardA
#sharding:
# clusterRole: shardsvr
setParameter:
skipShardingConfigurationChecks: true
disableLogicalSessionCacheRefresh: true并重新启动:
mongod --config <path/To/ConfigFile>(1,2)通过在不同的端口上运行mongod,可以确保在构建索引时,复制集的其他成员和所有客户端不会与该成员联系。
(2) 通过命令行的形式修改配置:
如果使用命令行选项,进行以下配置更新:
- 修改--端口到另一个端口。[2]
- 删除,复制集。
- 删除--shardsvr(如果是shard成员),删除——configsvr(如果是config server成员)。
- 在setParameter选项中将参数skipshardingconfigurationcheck(也适用于MongoDB 3.6.3+、3.4.11+、3.2.19+)设置为true。
- 在--setParameter选项中,将参数disableLogicalSessionCacheRefresh设置为true。
例如,在不使用——replSet和——shardsvr选项的情况下重启碎片复制集成员。指定一个新的端口号,并将skipshardingconfigurationcheck和disableLogicalSessionCacheRefresh参数设置为true:
mongod --port 27218 --setParameter skipShardingConfigurationChecks=true --setParameter disableLogicalSessionCacheRefresh=true(1,2)通过在不同的端口上运行mongod,可以确保在构建索引时,复制集的其他成员和所有客户端不会与该成员联系。
C2. 建立索引
直接连接到在新端口上作为独立运行的mongod实例,并为该实例创建新索引。
例如,将一个mongo shell连接到实例,并使用db.collection.createIndex()方法在记录集合的username字段上创建一个升序索引:
db.records.createIndex( { username: 1 } )C3. 以复制集成员的身份重新启动mongod程序
当索引构建完成时,关闭mongod实例。撤消在作为独立程序启动时所做的配置更改,以返回到其原始配置并重新启动。
重要的:
请务必删除skipShardingConfigurationChecks参数和disableLogicalSessionCacheRefresh参数。
例如,重新启动你的复制集碎片成员:
(1)如果你正在使用一个配置文件:
- 恢复到原来的端口号。
- 取消replication.replSetName。
- 取消sharding.clusterRole。
- 在setParameter部分中删除参数skipshardingconfigurationchecking。
- 在setParameter部分中删除参数disableLogicalSessionCacheRefresh。
net:
bindIp: localhost,<hostname(s)|ip address(es)>
port: 27018
replication:
replSetName: shardA
sharding:
clusterRole: shardsvr其他设置(如储存)。dbPath等)保持不变。
并重新启动:
mongod --config <path/To/ConfigFile>允许复制赶上此成员。
(2)如果你使用命令行选项:
- 恢复到原来的端口号。
- 包括复制集。
- 如果是分片成员,则包含——shardsvr;如果是配置服务器成员,则包含——configsvr。
- 删除参数skipShardingConfigurationChecks。
- 删除参数disableLogicalSessionCacheRefresh。
例如:
mongod --port 27018 --replSet shardA --shardsvr其他设置(例如——dbpath等)保持不变。
允许复制赶上此成员。
C4.对碎片的其余附属服务器重复此过程
一旦成员赶上了集合中的其他成员,对碎片的其余次要成员一次重复一个成员的过程:
- C1.停止一个备用服务器并作为独立服务器重新启动
- C2.建立索引
- C3.以复制集成员的身份重新启动mongod程序
C5.在主服务器上构建索引
当shard的所有二级拥有新索引时,为shard下拉主索引,使用上面描述的过程作为一个独立的程序重新启动它,并在以前的主索引上构建索引:
- 使用mongo shell中的rs.stepDown()方法来逐步退出主进程。成功下步后,当前主服务器将成为一个辅助服务器,而复制集成员将选择一个新的主服务器。
- C1.停止一个备用服务器并作为独立服务器重新启动
- C2.建立索引
- C3.以复制集成员的身份重新启动mongod程序
D.重复其他受影响的碎片
为切分构建完索引之后,重复C.在包含其他受影响切分的收集块的切分上构建索引。
E.重新启动平衡器
完成受影响碎片的滚动索引构建之后,重新启动平衡器。
将一个mongo shell连接到切分集群中的mongos实例,并运行sh.startBalancer(): [3]
sh.startBalancer()从MongoDB 4.2开始,sh.startBalancer()也支持分片集群的自动分割。















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









