







我们在学习一个新鲜事务之前, 最好是先搞清楚这个事务发展的来龙去脉。这样有助于增加对该事务的好感,进而有信心去探索它。
1. 内存管理演变过程
我们在学习linux 内存管理也是如此。今天我们就先八卦一下它的演变史。
我们先设想一下,让你发明一个计算机。我们的程序该如何才能跑起来呢。
什么是程序?
- 教条一点的说法就是: 程序是指一组指令的集合,用于指导计算机执行特定任务或解决特定问题
- 简单的说: 就是告诉cpu 第一步, 第二步 要去做什么。那是不是要去做A这个事情,可以拆分成很多步。 步骤的集合就是我们的程序A。 同理 程序B 、C、D。
刚开始条件有限, 我们可以把 程序A 、B、C、D 分别写在一个纸条上。 放在一个 纸篓里面(硬盘)。 当我们要运行 程序A , 时我们从纸篓中(磁盘)中找到对应的纸条。 将纸条的内容 读出来放置到 cpu 可以访问到的地方(内存)。 然后cpu 来一条条去执行 程序A 对应的步骤。
伴随着时代的变迁,科技的进步。已经不再使用 纸张来记录我们的程序了。 而是将我们 程序的二进制保存在我们的磁盘中。 cpu 执行时将磁盘中的二进制加载到我们的 内存中。
1.1 动态分区法
- 假设我们的物理内存只有 30MB
- 程序A 需要 6MB
- 程序B 需要 12MB
- 程序C 需要 10MB
- 程序D 需要 5MB
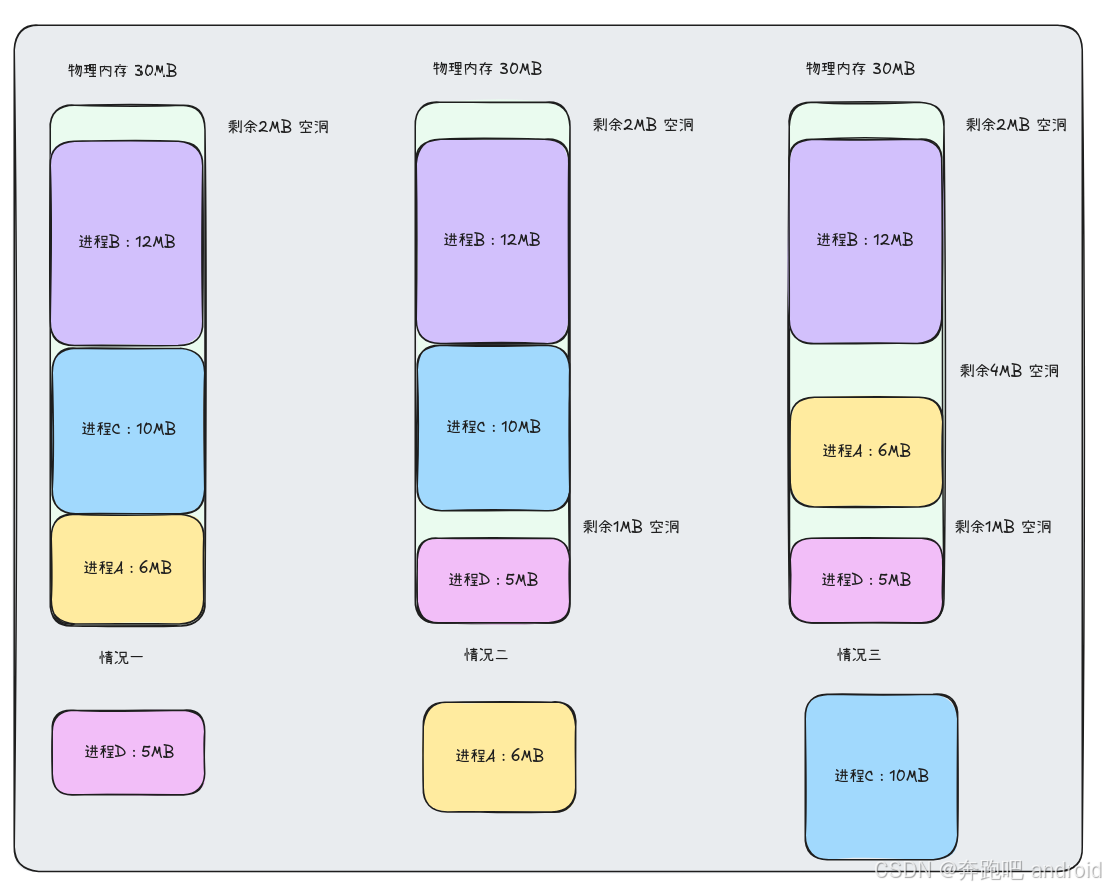
在计算机发展的早期, 进程是直接运行在物理内存中的
- 情况一:
- 进程A 进程C 进程B 同时运行。
- 如果此时我们要运行 进程 D, 需要 5MB大小的物理空间。那我们该如何处理? 此时物理内存还剩余 2MB 空间。不足以运行进程D。
- 情况二:
- 我们只好将进程A 6MB, 交换到 我们的磁盘中, 将我们的 进程D 加载进来。
- 此时 进程 D 和 进程 C 之间就出现了 1MB的空洞。
- 如果此时 我们又要 执行进程 A, 需要 6MB 物理空间。同时进程D 也需要执行。那该如何处理?
- 情况三:
- 我们可以把 C 10MB 先交换到 磁盘中。此时再将我们先前交换出去的进程A 6MB , 在加载到我们的物理内存中执行。
- 此时发现 我们存在如图所示的三个空洞。
- 进程D 和 进程A 之间有一个 1MB的空洞。
- 进程A 和 进程B 之间 有一个 4MB 的空洞
- 而物理内存最上面还有一个 2MB 的空洞。
- 上面这个过程就是 碎片产生的原因。
- 由于早期, 程序是直接运行在物理内存中的。 而且程序之间没有保护。 很容易篡改其他进程中的数据,导致出现异常。
- 并且 随着运行时间的变长。程序会不断的在内存和磁盘中交换。 而且每次交换后在内存中的地址并不是固定的。由于当前是通过物理地址访问的。这样会导致 程序地址需要重定位。增加了开发的难度。并且也很容易产生物理内存碎片化。 最终导致可以用的物理空间越来越小。
综合, 动态分区法存在的弊端是:
- 进程地址空间无保护: 程序之间可以随意破坏。
- 程序运行地址需要重定位: 增加开发难度。
- 内存利用率低:碎片化严重。
大佬们为了解决上述三个问题, 提出了 分段机制和分页机制。
1.2 分段机制
对于 第一和第二个问题 进程地址空间没有保护 和 程序地址需要重定位。 人们使用虚拟内存的方式来解决。
进程 A 和 进程 B, 使用各自的虚拟内存,彼此之间无感。如果其中一个进程访问了没有映射的虚拟地址空间,或者访问了不属于该进程自己的虚拟空间,cpu 会捕获这个越界访问,并拒绝该访问。
由于程序运行在各自的虚拟内存中, 并不需要关心物理地址。它运行时只关心虚拟地址。工程师们也不用像在 动态分区中那样就关心 每个进程的物理运行地址。这样就避免了 程序地址的重定位。
请看如下场景:
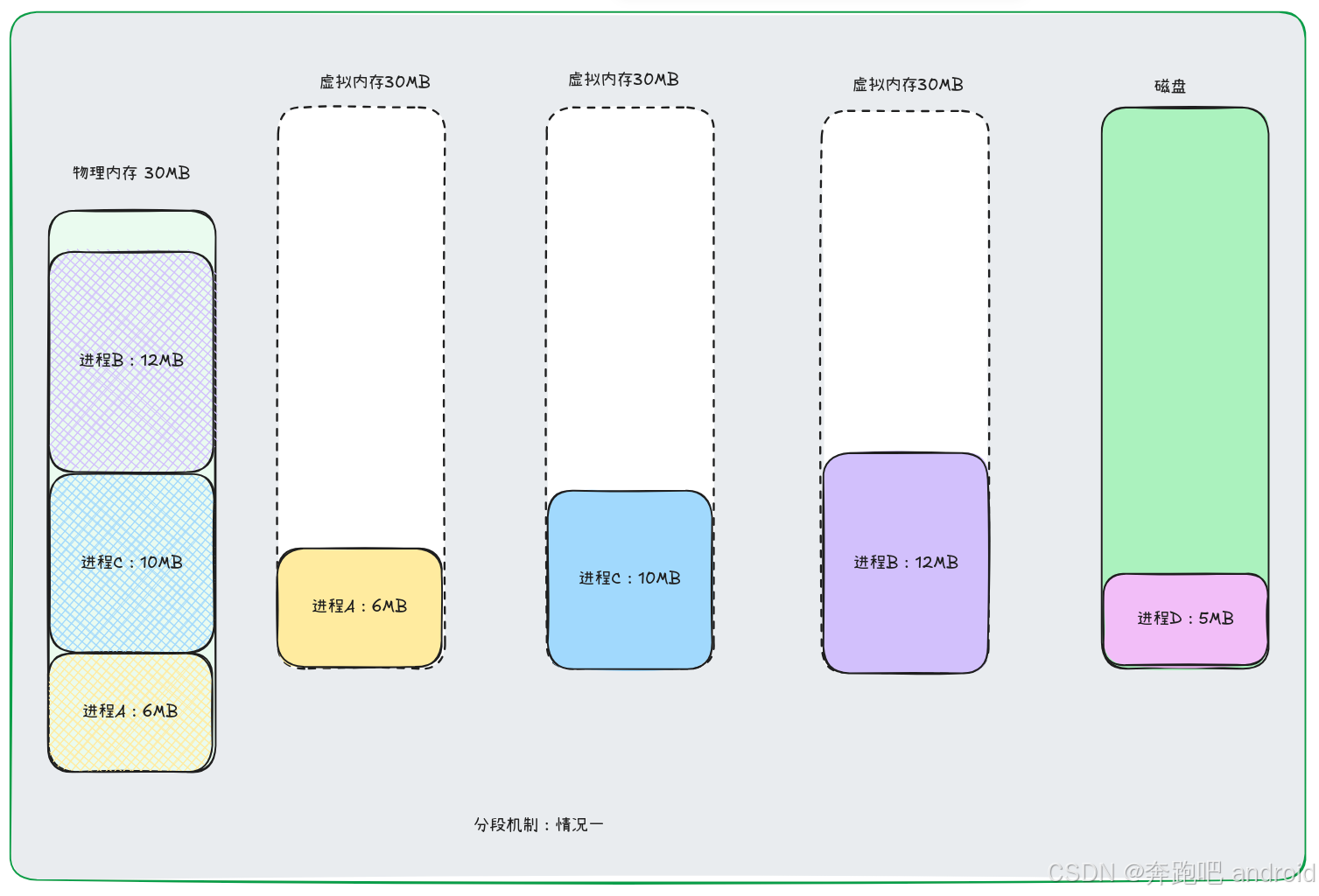
场景一:
- 进程 A B C 各自在自己的 虚拟地址中运行。 但是他们都被映射到不同的物理地址中。 如果此时要想运行 进程D, 由于物理地址没有 5MB 大小的空间。 此时就要 将进程 A 交换出去。 交换出去如下图。
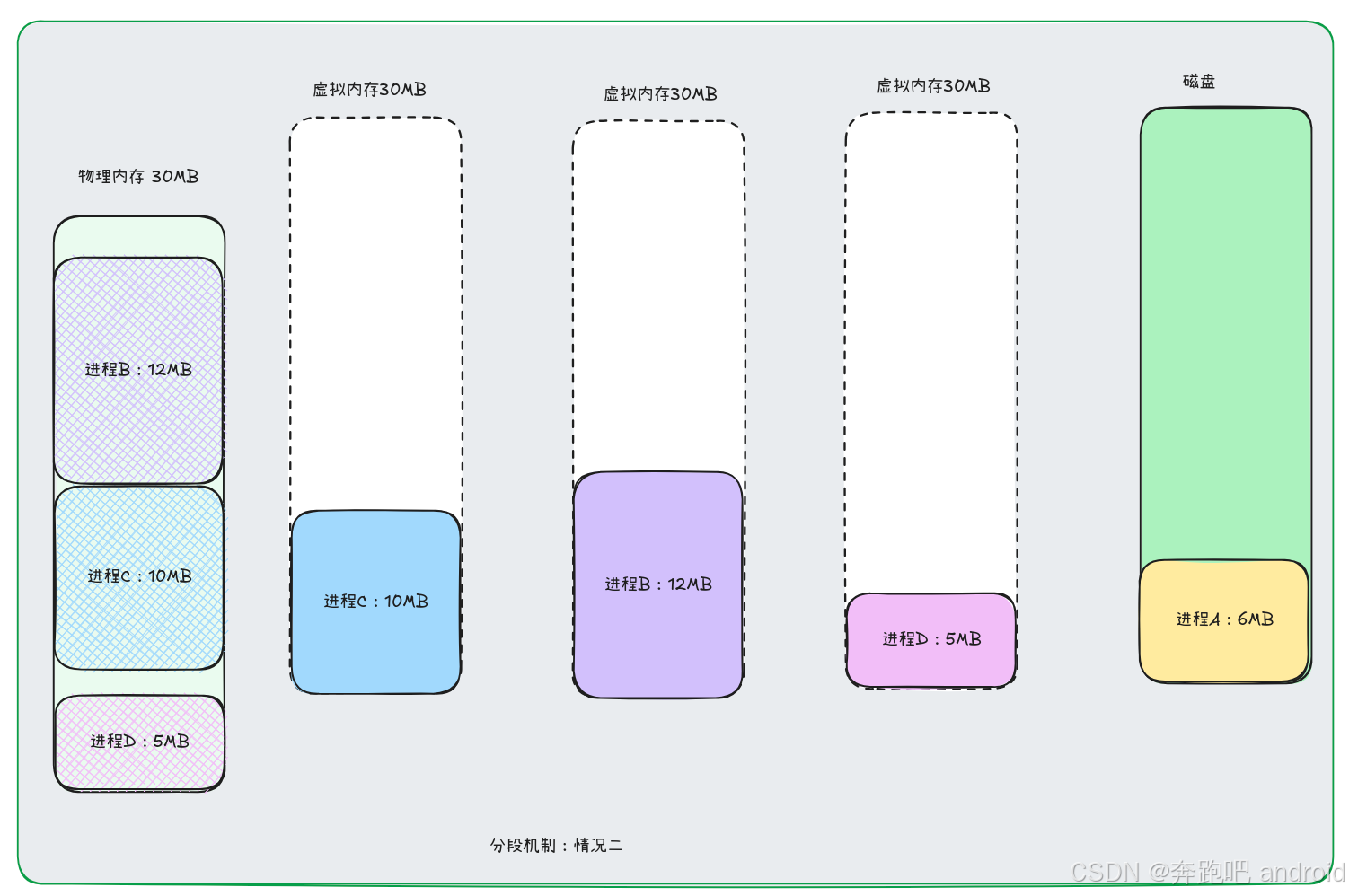
场景二:
- 此时 进程 C 和 进程 D 中间就有 1 MB的空洞。
虽然我们的程序可以分为 数据段、程序段、堆段、栈段。 但是在每次物理空间不够时, 依然 会以进程为单位将我们的进程给交换到磁盘中。
总结:
- 分段机制中引入了 虚拟地址空间的概念, 很好的解决了 地址空间无保护和 地址重定位问题。
- 但同时, 依然没有很好的解决 地址碎片问题, 而且按照程序为单位在内存和磁盘来交换,效率不高和资源浪费也同样是问题。
这种 按照进程为单位将整个进程资源交换到磁盘中的行为, 非常浪费系统资源。而且效率也不高。 并且每次进程在运行时,也并不需要 将整个程序加载到内存中。实际每次运行时只需要程序各自段中的一小部分。基于这种情况,人们就在思考, 能不能只将程序的一部分映射到物理内存中。 需要时在从磁盘中去加载对应的部分。 基于这种思路, 人们发明了 分页机制。
1.3 分页机制
由于在分段机制中, 地址映射的粒度比较大,以整个进程地址空间为单位来映射物理地址空间。 这样导致内存利用率不到。分页机制的出现很好的解决了这种问题。
分页机制中, 物理地址空间和虚拟地址空间都是按照页为单位来映射的。这样程序运行所需要的数据和代码还有堆栈都可以 按照页的大小来驻留到我们的内存中。而不常用的 内容也同样按照页的大小可以交换到磁盘中。从而节约了物理内存。
如图所示
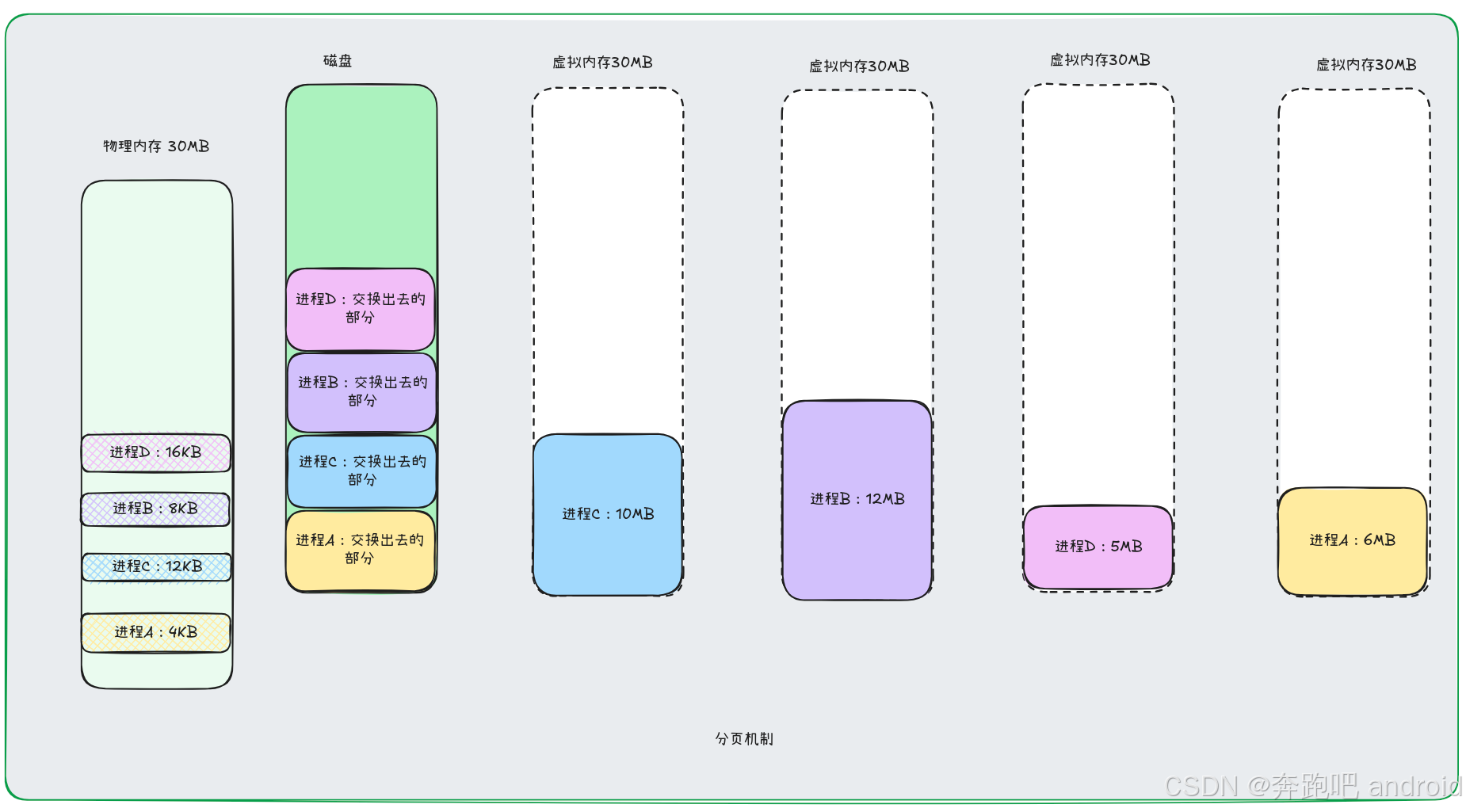
- 进程 A、B、C、D 各自运行在各自的虚拟内存空间中, 但是物理空间中只保留了 程序运行所需的物理页。其余都可以交换到物理磁盘中。这样很大的程度上提高内存的使用效率。
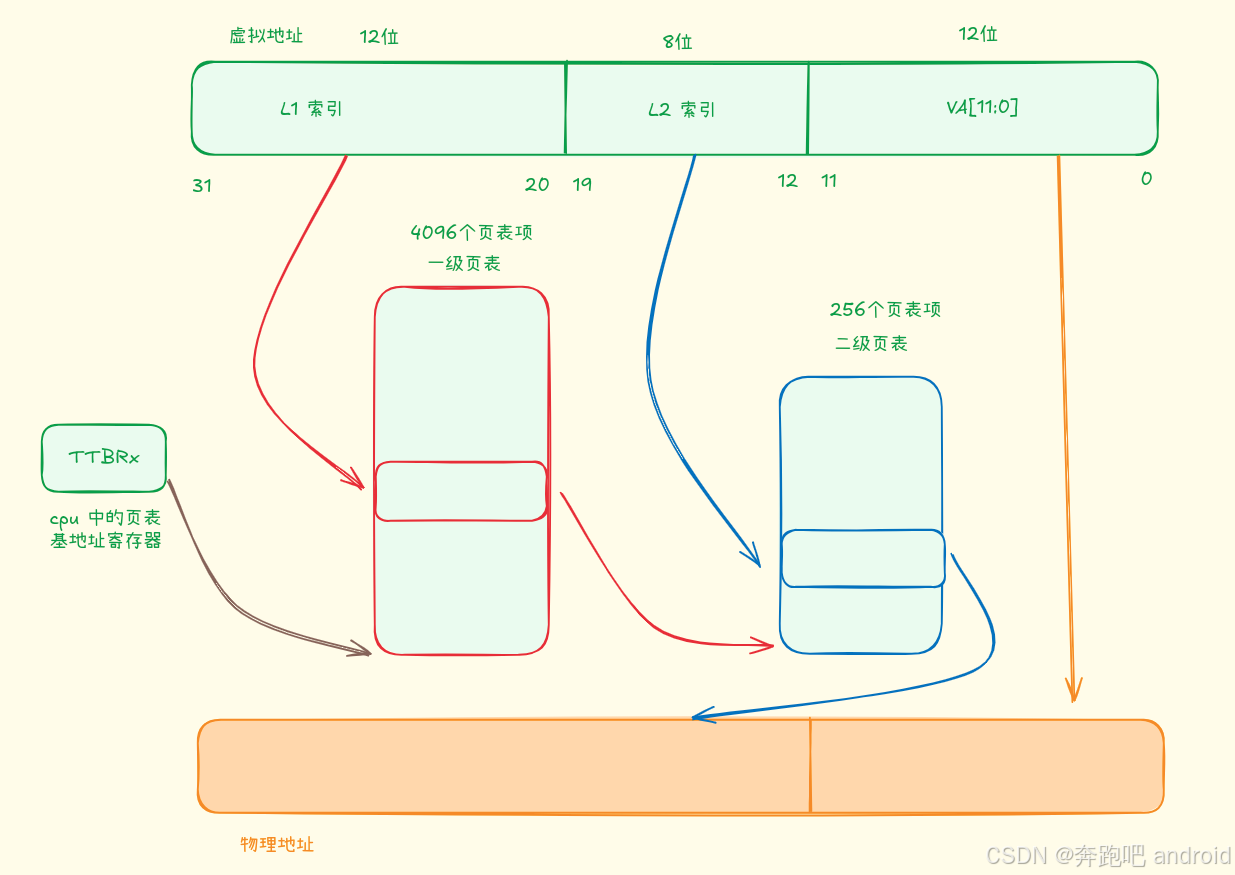
上面的图描述了 32 位虚拟地址 如何转化为 物理地址。
- cpu 中 TTBR 中保存该进程的 一级页表的物理地址。 我们拿到一个虚拟地址后,的[31:20] 描述了当前一级页表中页表项的偏移量。 通过它就可以从一级页表中找到对应的页表项。从而找到二级页表的起始物理地址。
- 虚拟地址的[19:12] 中代表了 二级页表中的偏移地址。 通过它, 结合上一步找到的二级页表的起始地址。就能找到 对应的二级页表项。在二级页表的页表项中保存了 [31:12] 物理地址。
- [31:12] 物理地址 + 虚拟地址的[11:0] 就是最终的物理地址。

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









