







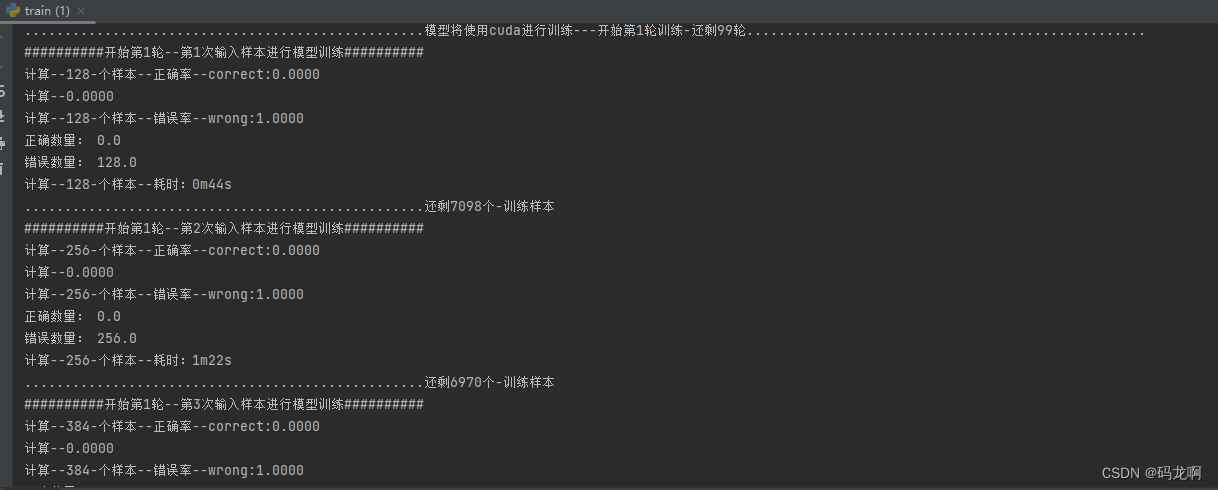
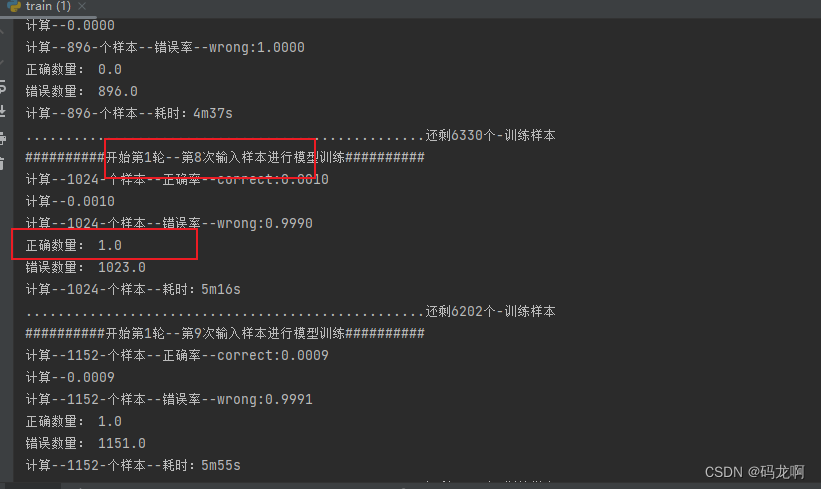
128batch 测试…第1轮第8次输入样本才学习到1个…样本用了1024个…
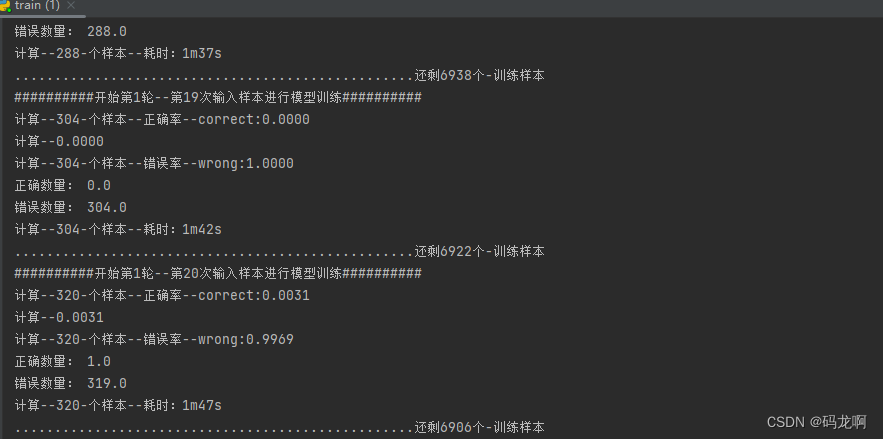
32batch 第1轮第20次输入样本就学习到1个…样本才用了320个…
OCR(Optical Character Recognition,光学字符识别)模型在批次(batch size)较小时可能会表现出更高的精度,这主要可以归结为以下几个原因:
1.探索数据空间的能力:
当批次较小时,模型在每次迭代中处理的数据量较少。这意味着模型在训练过程中能够更频繁地更新权重,从而有机会更细致地探索数据空间。这有助于模型找到更适合全局最优解的权重配置。
相比之下,较大的批次可能使模型在权重更新时“跳过”某些局部最优解,从而可能影响最终的精度。
泛化能力:
较小的批次通常意味着模型在训练过程中会接触到更多的数据组合。这有助于模型学习更加通用的特征,从而提高其在未见过的数据上的泛化能力。
较大的批次可能会使模型过度拟合训练数据,导致在测试集或实际应用中的性能下降。
2.计算资源的有效利用:
在GPU等计算资源有限的情况下,较小的批次可以更有效地利用这些资源。因为每个批次都需要一定的计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









