






0、前言
0.1 认识DataFrame
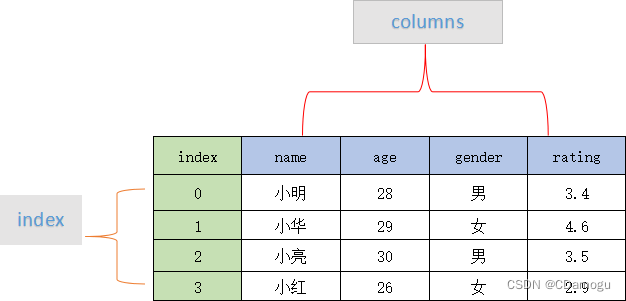
Pandas DataFrame入门教程(图解版)
Pandas 数据结构 - DataFrame
0.2 read_html
# 注意:返回的结果是DataFrame组成的list。
pandas.read_html(io, #指定识别的对象,可为网址、本地HTML、request得到的响应的文本内容
match='.+', #传入正则表达式,返回符合match的内容,可理解为内容的筛选
flavor=None, #可省,指定网页源代码的解析器,常用的lxml解析器(也是默认解析器)
header=None, #可省,指定一行或多行作为表格的列标签,默认None。若把多行作为列标签,则需要以列表形式给出,如:把0~2行作为行列标签,则列序号从第4行即序号3的行开始排列
index_col=None, #可省,指定表格中的任一列作为行标签,默认None
skiprows=None,
attrs=None,
parse_dates=False,
tupleize_cols=None,
thousands=', ',
encoding=None, #可省,指定解码的字符集,默认用网页源码指定的字符集(取值:utf-8,gbk )
decimal='.',
converters=None,
na_values=None,
keep_default_na=True,
displayed_only=True)
1、表格设计
'''
# 表格设计如下
ID Options Description Value
MTODORULE1 SWPERMIT Allow Software use True
MTODORULE2 NaN NaN NaN
MTODORULE3 NaN NaN NaN
'''
2、代码部分
import pandas as pd
url = 'https://docs.qq.com/doc/xxx' #填充为自己的网址
data = pd.read_html(url, header=0,encoding='utf-8')
data0 = pd.read_html(url, header=0,encoding='utf-8')[0]
print('-------------------------------------------------')
print(type(data))
print(data)
print('-------------------------------------------------')
print(type(data0))
print(data0)
print('-------------------------------------------------')
df = data[0]
print(type(df))
print(df)
print('-------------------------------------------------')
print(df['Value'])
print('-------------------------------------------------')
print(df.loc[0])
print('-------------------------------------------------')
print(df['Value'].loc[0])
print(df['ID'].loc[0])
print('-------------------------------------------------')
3、执行结果
-------------------------------------------------
<class 'list'>
[ ID Options Description Value
0 MTODORULE1 SWPERMIT Allow Software use True
1 MTODORULE2 NaN NaN NaN
2 MTODORULE3 NaN NaN NaN]
-------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
ID Options Description Value
0 MTODORULE1 SWPERMIT Allow Software use True
1 MTODORULE2 NaN NaN NaN
2 MTODORULE3 NaN NaN NaN
-------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
ID Options Description Value
0 MTODORULE1 SWPERMIT Allow Software use True
1 MTODORULE2 NaN NaN NaN
2 MTODORULE3 NaN NaN NaN
-------------------------------------------------
0 True
1 NaN
2 NaN
Name: Value, dtype: object
-------------------------------------------------
ID MTODORULE1
Options SWPERMIT
Description Allow Software use
Value True
Name: 0, dtype: object
-------------------------------------------------
True
MTODORULE1
-------------------------------------------------
4、结果分析
4.1 什么情况下返回值是List,什么时候是DataFrame
#返回值是List
data = pd.read_html(url, header=0,encoding='utf-8')
#返回值是DataFrame
data0 = pd.read_html(url, header=0,encoding='utf-8')[0]
4.2 如何把List转换为DataFrame
data = pd.read_html(url, header=0,encoding='utf-8')
df = data[0]
4.3 如何打印表格及如何保存到Excel表格
data = pd.read_html(url, header=0,encoding='utf-8')
df = data[0]
#打印
print(df)
#保存到excel
df.to_csv('savetoexcel.csv')
4.4 如何行索引
data = pd.read_html(url, header=0,encoding='utf-8')
df = data[0]
print(df.loc[0])
4.5 如何列索引
data = pd.read_html(url, header=0,encoding='utf-8')
df = data[0]
print(df['Value'])
4.6 如何行列索引
data = pd.read_html(url, header=0,encoding='utf-8')
df = data[0]
print(df['Value'].loc[0])
5、pandas dataframe 方法示例
5.1 pandas dropna()移除空行、空列
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列how:默认为 ‘any’ 如果一行(列)里任何一个数据有出现 NA 就去掉整行,设置 how=‘all’ 一行(列)都是 NA 才去掉这整行thresh:设置需要多少非空值的数据才可以保留下来的subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据
import pandas as pd
df=pd.read_excel(r'C:\CDamoguExample.xlsx')
df=df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)# 删除全部为空的行(只要有空值就删除)
df=df.dropna(axis=0, how='all', thresh=None, subset=None, inplace=False)# 只有全部为空才回被删除
df=df.dropna(axis=0, how='all', thresh=5, subset=None, inplace=False)# 一行中必须有5个非空值才能保留.否则删除
df=df.dropna(axis=1, how='any', thresh=None, subset=None, inplace=False)# 删除全部为空的列(只要有空值就删除)
5.2 pandas drop() 删除列
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(36).reshape(6,6), columns=['A', 'B', 'C', 'D','E','F'])
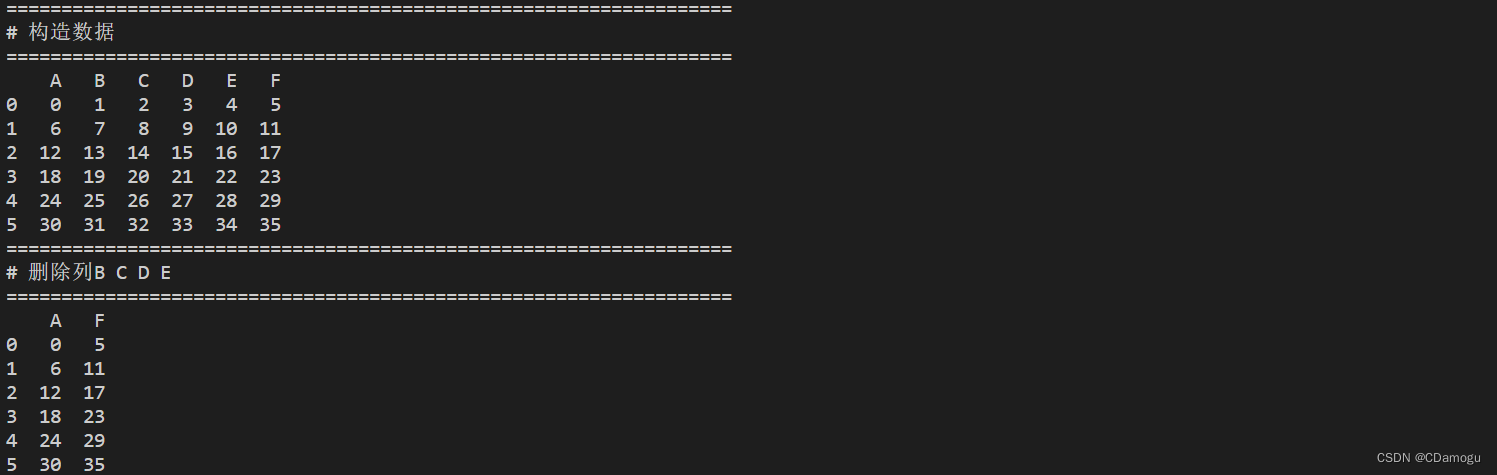
print("==================================================================")
print("# 构造数据")
print("==================================================================")
print(df)
print("==================================================================")
print("# 删除列B C D E")
print("==================================================================")
df = df.drop(['B', 'C'], axis=1)
df = df.drop(columns=['D', 'E'])
print(df)
df = df.drop(['B', 'C'], axis=1)
df = df.drop(columns=['D', 'E'])
5.3 pandas drop() 删除行
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(36).reshape(6,6), columns=['A', 'B', 'C', 'D','E','F'])
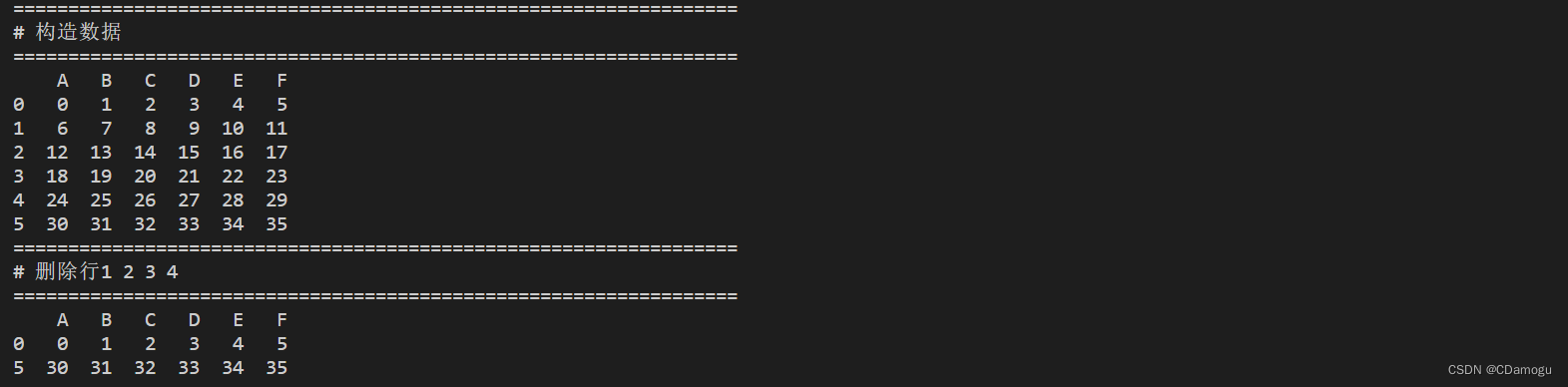
print("==================================================================")
print("# 构造数据")
print("==================================================================")
print(df)
print("==================================================================")
print("# 删除行1 2 3 4")
print("==================================================================")
df = df.drop([1,2])
df = df.drop(index=[3,4])
print(df)
df = df.drop([1,2])
df = df.drop(index=[3,4])
5.4 DataFrame数据格式化 (设置小数位数)
import pandas as pd
import numpy as np
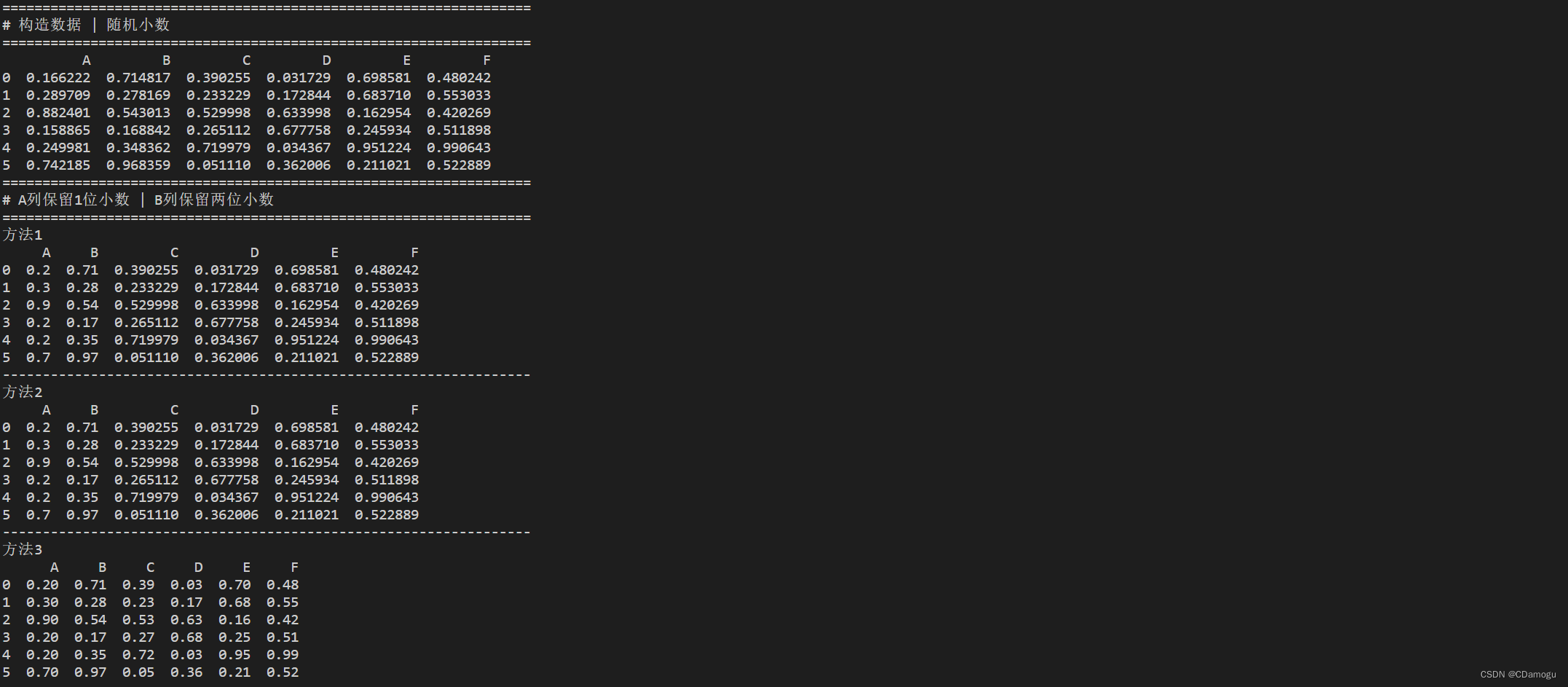
df = pd.DataFrame(np.random.random([6,6]),columns=['A', 'B', 'C', 'D','E','F'])
print("==================================================================")
print("# 构造数据 | 随机小数")
print("==================================================================")
print(df)
print("==================================================================")
print("# A列保留1位小数 | B列保留两位小数")
print("==================================================================")
df = df.round({'A': 1, 'B': 2})
print('方法1')
print(df)
print("------------------------------------------------------------------")
s1 = pd.Series([1,2], index=['A','B'])
df = df.round(s1)
print('方法2')
print(df)
print("------------------------------------------------------------------")
df = df.applymap(lambda x: '%.2f'%x)
print('方法3')
print(df)
三种方法
df = df.round({'A': 1, 'B': 2})s1 = pd.Series([1,2], index=['A','B'])df.round(s1)df = df.applymap(lambda x: '%.2f'%x)
5.5 DataFrame数据格式化 (设置百分比)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([6,6]),columns=['A', 'B', 'C', 'D','E','F'])
print("==================================================================")
print("# 构造数据 | 随机小数")
print("==================================================================")
print(df)
print("==================================================================")
print("# 设置百分比")
print("==================================================================")
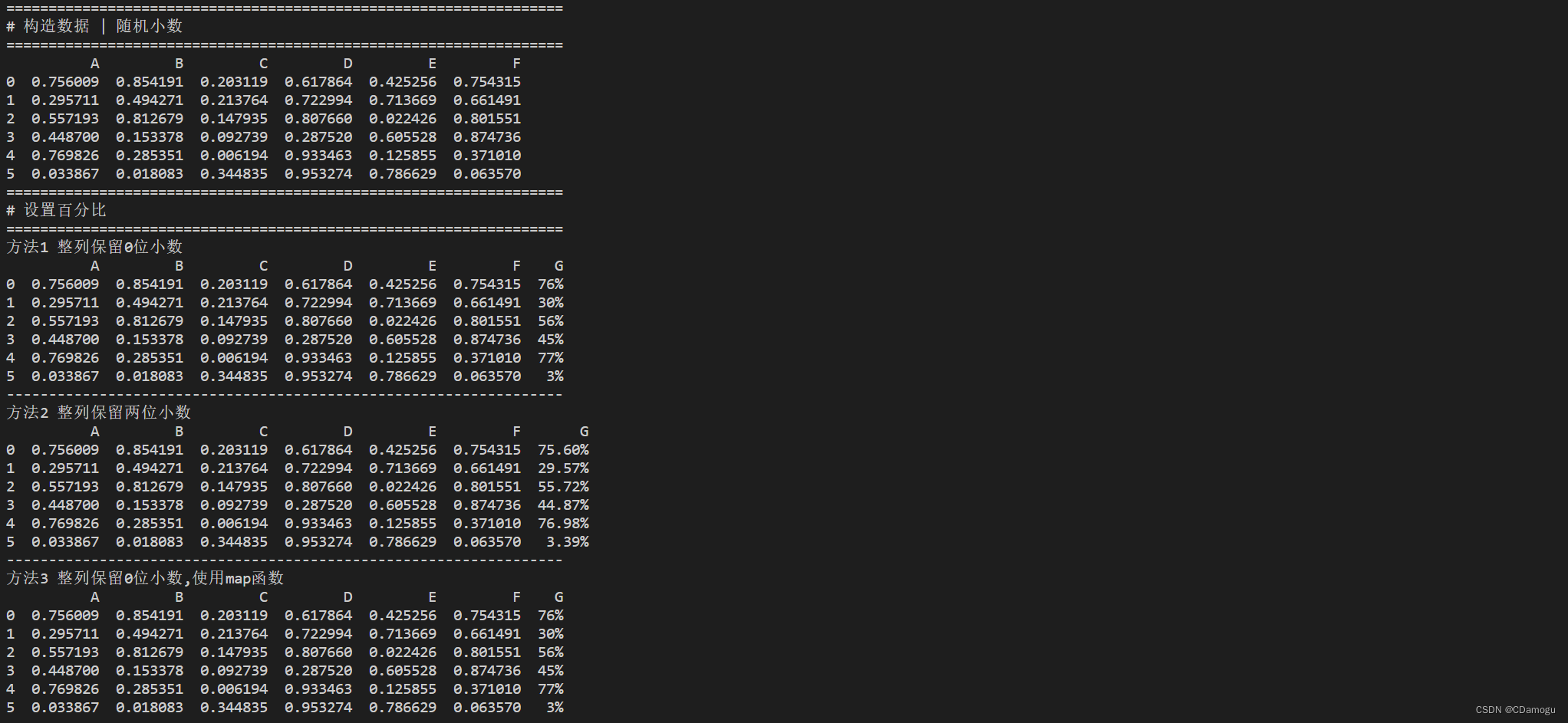
df['G'] = df['A'].apply(lambda x: format(x, '.0%'))
print('方法1 整列保留0位小数')
print(df)
print("------------------------------------------------------------------")
df['G'] = df['A'].apply(lambda x: format(x, '.2%'))
print('方法2 整列保留两位小数')
print(df)
print("------------------------------------------------------------------")
df['G'] = df['A'].map(lambda x: '{:.0%}'.format(x))
print('方法3 整列保留0位小数,使用map函数')
print(df)
希望大家多一点耐心把代码和下面的表现效果对应起来,来吸收理解
5.6 DataFrame数据格式化 (设置千分位分隔符)
import pandas as pd
l1 = list([1,2,3])
l2 = list([1,2,3])
l3 = list([123456789,123456789,123456789])
# 将3个1维List合成1个2维List
l4 = [list(t) for t in zip(l1,l2,l3)]
df = pd.DataFrame(data=l4,columns=['A', 'B', 'C'])
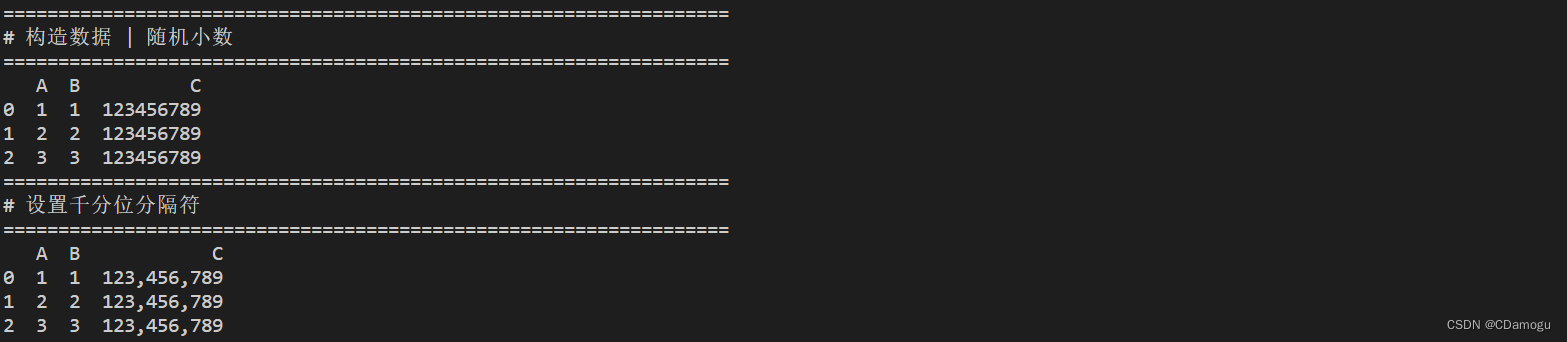
print("==================================================================")
print("# 构造数据 | 随机小数")
print("==================================================================")
print(df)
print("==================================================================")
print("# 设置千分位分隔符")
print("==================================================================")
df['C'] = df['C'].apply(lambda x: format(int(x), ','))
print(df)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











