









目录
4 conntrack丢包:nf_conntrack: table full
摘要
一个数据包在网络中传输的过程中,是没法保证一定能被目的机接收到的。其中有各种各样的丢包原因,今天来学习一下数据包经过 linux 内核时常见的丢包场景。

1 收发包处理流程
有必要再回顾下 linux 内核的收发包处理流程,才能更好的认清楚数据包所经过的环节。
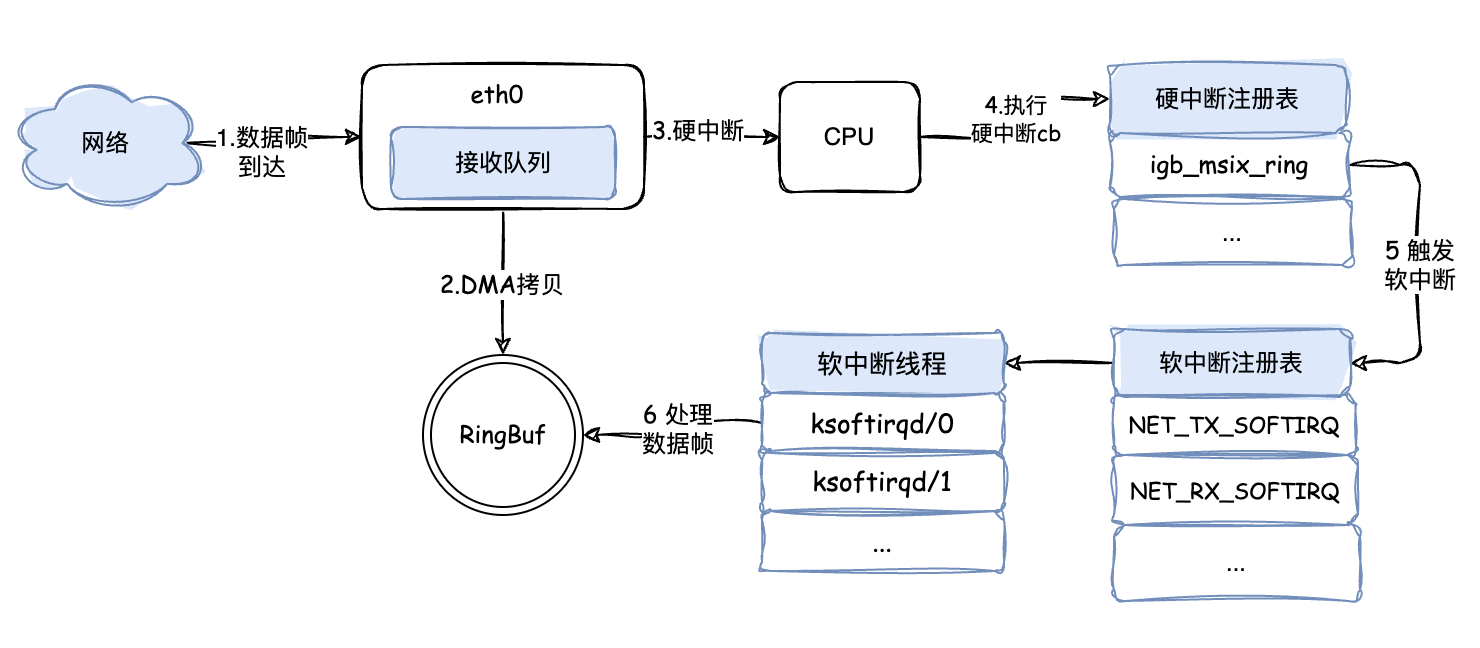
当网卡接收到报文时,将数据包 DMA 拷贝到 RingBuf 并触发一个硬中断。继而 cpu 开始执行对应的(硬)中断处理例程。在硬中断处理例程中,将数据包 list 放在了每 cpu 变量 poll_list 中,紧接着触发了一个收包软中断。对应 cpu 的软中断线程 ksoftirqd 处理网络包接收软中断( net_rx_action() ),将数据包从 RingBuf 中取出,协议栈层层处理,经网络层到传输层,数据包被放到 socket 的接收队列中。随后被应用层收取数据。

同样的,在发送数据时,skb 也是经过协议栈层层处理。在网络层对 skb 克隆,填充路由项,依次流经 netfilter 框架的 local_out 、post_routing 点。在邻居子系统填充了 mac 地址,在网络设备子系统中将 skb 放到了发送队列 RingBuf 中。在网卡发送完成后,又会通过硬中断触发软中断,在软中断处理函数中进行 RingBuf 的清理。
接下来进入丢包正题。
2 硬件网卡相关
2.1 ring buffer满
一般物理网卡丢包时,可以通过 ethtool -S 看到相应的统计信息:
[root@centos ~]# ethtool -s eht0
NIC statistics:
rx_packets: 123456
tx_packets: 789012
rx_bytes: 123456789
tx_bytes: 987654321
rx_errors: 0
tx_errors: 0
tx_dropped: 0
...
rx_no_buffer_count : 0 如果发现 rx_no_buffer_count 一直在增长,基本上是因为接收的 RingBuf 满导致的丢包。当然问题的核心原因还是接收流量太大& cpu 处理慢,导致数据包积压造成了丢包。具体的,可能有以下几种场景:
a 硬中断分发不均
通过 cat /proc/interrupts 来查看网卡的硬中断是否均衡,如果报文处理都集中在一个核上,那么很大可能会导致 cpu 处理不过来导致丢包。这种情况可以考虑关闭 irqbalance,使用 set_irq_affinity.sh 来进行手动绑核,使硬中断的分发更均匀。
[root@centos ~]# cat /proc/interrupts
CPU0 CPU1
...
27: 6547137 0 PCI-MSI-edge virtio0-input.0
28: 1 0 PCI-MSI-edge virtio0-output.0
29: 1 5938591 PCI-MSI-edge virtio0-input.1
30: 1 0 PCI-MSI-edge virtio0-output.1b 会话分发不均
有时候发现硬中断已经是均衡的了,但网络流量触发的中断量级更大,并且集中在某几个核上面,这也是可能导致丢包的原因之一。对于支持多接收队列的网卡,通过 RSS 功能,根据数据包的某些字段(如源ip、目的ip、源端口、目的端口)将数据包哈希到不同的接收队列中,进而分发给不同的 cpu 进行处理。
查看网卡是否支持多队列:
[root@centos ~]# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 2 # 支持2个组合队列:既可作接收也可作发送
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 2# 查看 udp 会话分发哈希关键字
[root@centos ~]# ethtool --show-ntuple eth0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA通过 ethtool --config-ntuple 可以修改分发使用的哈希关键字。
c rps
如果网卡不支持多队列,或者支持的多队列远远小于CPU核数(当然这两种情况都比较少见了)。linux内核提供了 rps 机制来进行软中断的负载均衡。比如可以通过 echo ff > /sys/class/net/eth0/queues/rx-0/rps_cpus 来指定某个接收队列负载均衡到哪几个核处理。当然由于通过软件进行模拟,相比硬中断均衡,性能会下降很多,一般没有特殊原因,不建议开启。
d 突发流量
如果是间接性的突发流量导致丢包,可以通过 ethtool -g 来查看当前的 RingBuf 配置,并通过ethtool -G 命令加大 RingBuf 的 size,减少突发流量导致的丢包。
[root@centos ~]# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 1024
RX Mini: 0
RX Jumbo: 0
TX: 1024
Current hardware settings:
RX: 1024
RX Mini: 0
RX Jumbo: 0
TX: 10242.2 利用 ntuple 保证关键业务
有些情况下,需要保证控制报文高优先级进行处理,默认情况下,网卡无差别对待所有报文,通过 rss 技术来选择队列,无法区分控制报文。可以开启网卡的 ntuple 功能来实现,比如将 tcp 端口号为 23 的报文,定向到 queue 9,与此同时其他报文仍使用 rss 技术,并且设置为使用 8 个队列:
[root@centos ~]# ethtool -K eth0 ntuple on
[root@centos ~]# ethtool -U eth0 flow-type tcp4 dst-port 23 action 9
[root@centos ~]# ethtool -X eth0 equal 8当对相应的业务进行绑核处理后,tcp 的 23 端口即可以跟其他业务不冲突,保证其高优先级进行处理。当然这个方案依赖于底层网卡的实现,并不是所有网卡都支持的。
3 arp丢包
3.1 neighbor table overflow
arp 比较常见的一个问题是 neighbor 表满了,内核会大量打印如下的消息:
[22181.923055] neighbour: arp_cache: neighbor table overflow!
[22181.923080] neighbour: arp_cache: neighbor table overflow!
[22181.923128] neighbour: arp_cache: neighbor table overflow!
cat /proc/net/stat/arp_cache 也能看到大量的 table_fulls 统计:
[root@centos ~]# cat /proc/net/stat/arp_cache
entries allocs destroys hash_grows lookups hits res_failed rcv_probes_mcast rcv_probes_ucast periodic_gc_runs forced_gc_runs unresolved_discards table_fulls
00000002 0000000d 0000000d 00000000 00000515 00000089 00000015 00000000 00000000 00000267 000003a1 00000023 0000039c
00000002 0000001c 0000001a 00000000 00001675 00000374 00000093 00000000 00000000 000003bf 00000252 00000046 00000240主要原因跟arp的参数如下几个参数相关,将其改大到合适的值即可解决该问题:
# 保存在于ARP高速缓存中的最少层数,如果少于这个数,垃圾收集器将不会运行
[root@centos ~]# echo 1024 > /proc/sys/net/ipv4/neigh/default/gc_thresh1
# 保存在 ARP 高速缓存中的最多的记录软限制。垃圾收集器在开始收集前,允许记录数超过这个数字 5 秒
[root@centos ~]# echo 2048 > /proc/sys/net/ipv4/neigh/default/gc_thresh2
# 保存在 ARP 高速缓存中的最多记录的硬限制,一旦高速缓存中的数目高于此,垃圾收集器将马上运行
[root@centos ~]# echo 4096 > /proc/sys/net/ipv4/neigh/default/gc_thresh33.2 unresolved drops
当发送报文时,如果还没解析到 arp,就会发送 arp 请求,并缓存相应的报文。当然这个缓存是有限制的,默认为 SK_WMEM_MAX(即与 net.core.wmem_default 相同)。当大量发送报文并且 arp 没解析到时,就可能超过 queue_len 导致丢包,cat /proc/net/stat/arp_cache 可以看到unresolved_discards 的统计:
[root@centos ~]# cat /proc/net/stat/arp_cache
entries allocs destroys hash_grows lookups hits res_failed rcv_probes_mcast rcv_probes_ucast periodic_gc_runs forced_gc_runs unresolved_discards table_fulls
00000004 00000006 00000003 00000000 0000008f 00000018 00000000 00000000 00000000 00000031 00000000 00000000 00000000
00000004 00000005 00000004 00000000 00000184 0000003b 00000000 00000000 00000000 00000053 00000000 00000005 00000000可以通过调整 /proc/sys/net/ipv4/neigh/eth0/unres_qlen_bytes 参数来缓解该问题。
4 conntrack丢包:nf_conntrack: table full
当连接数比较多的时候,可能遇到这个连接跟踪表满的错误。
[ 2306.529864] nf_conntrack: nf_conntrack: table full, dropping packet
[ 2370.529866] nf_conntrack: nf_conntrack: table full, dropping packet
[ 2383.059264] nf_conntrack: nf_conntrack: table full, dropping packet
conntrack 有个最大表项数(/proc/sys/net/netfilter/nf_conntrack_max)限制来控制。当 conntrack 数目达到 nf_conntrack_max 后,就会尝试将一些未 assured 状态的 conntrack 提前老化掉,尝试8次,未找到合适的可以提前老化的表项,就直接进行丢包处理。
出于性能的考虑,调大 nf_conntrack_max 的同时,一般也需要调整 nf_conntrack_buckets,建议 max/buckets 小于8 比较合适,这样即使被攻击了,也能快速的进行 early_drop。比如调整 max 到300万,buckets 最好也做相应的调整:
[root@centos ~]# echo 3000000 > /proc/sys/net/netfilter/nf_conntrack_max
[root@centos ~]# echo $((65536*)) > /proc/sys/net/netfilter/nf_conntrack_buckets5 udp接收buffer满
当一个快的 udp sender,会导致一个较慢的 udp receiver socket recv buffer 满,导致丢包。尤其是存在大量突发的报文时。通过 netstat 查看 receive buffer errors 的统计就可以获知是否存在这种情况:
[root@centos ~]# netstat -su
...
Udp:
690124 packets received
3919 packets to unknown port received.
0 packet receive errors
694556 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
IpExt:
InNoRoutes: 2
InMcastPkts: 37301
InOctets: 2711899731
OutOctets: 2207144577
InMcastOctets: 1342836
InNoECTPkts: 14891803
InECT1Pkts: 2339
一般通过修改 /proc/sys/net/core/rmem_max,并且设置 SO_RCVBUF 选项来增加 socket buffer 可以缓解该问题。
6 丢包定位
6.1 dropwatch 查看丢包
除了 tcpdump 抓包进行分析外,dropwatch 也是网络协议栈丢包检查利器。实现原理也比较清晰,在 net/core/drop_monitor.c 文件中,当 kfree_skb 被调用时,内核就会记录下来,并通过 netlink 来通知用户态的 dropwatch 来记录。使用起来也非常简单,可以看到所有调用 kfree_skb() 的地方都会被输出:
[root@centos ~]# dropwatch -l kas
Initalizing kallsyms db
dropwatch> start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
1 drops at skb_queue_purge+18 (0xffffffffb4467eb8)
1 drops at icmp_rcv+125 (0xffffffffb4505a35)
1 drops at icmp_rcv+125 (0xffffffffb4505a35)
1 drops at icmp_rcv+125 (0xffffffffb4505a35)
^CGot a stop message
dropwatch> exit
Shutting down ...
6.2 利用 iptables LOG 跟踪报文流程
有时候,可能会有多个路由出口,为了知道特定的报文是如何路由出去的,可以借助 iptables LOG 来进行跟踪(需要结合limit模块来做限速,避免输出过多)。如下可以看到 ping 包是通过eth0 接口出去的:
[root@centos ~]# iptables -I OUTPUT -m limit --limit 1/s -p icmp -j LOG
[root@centos ~]# ping www.baidu.com
PING www.a.shifen.com (183.2.172.185) 56(84) bytes of data.
64 bytes from 183.2.172.185 (183.2.172.185): icmp_seq=1 ttl=52 time=5.87 ms
64 bytes from 183.2.172.185 (183.2.172.185): icmp_seq=2 ttl=52 time=5.03 ms
64 bytes from 183.2.172.185 (183.2.172.185): icmp_seq=3 ttl=52 time=5.17 ms
^C
--- www.a.shifen.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 5.039/5.362/5.875/0.371 ms
[root@centos ~]#
[root@centos ~]# dmesg
...
[2648940.712804] IN= OUT=eth0 SRC=10.0.24.9 DST=169.254.128.3 LEN=28 TOS=0x00 PREC=0x00 TTL=64 ID=23349 PROTO=ICMP TYPE=0 CODE=0 ID=50280 SEQ=34390
[2648943.189182] IN= OUT=eth0 SRC=10.0.24.9 DST=169.254.128.15 LEN=28 TOS=0x00 PREC=0x00 TTL=64 ID=62301 PROTO=ICMP TYPE=0 CODE=0 ID=36154 SEQ=45797
[2648943.730672] IN= OUT=eth0 SRC=10.0.24.9 DST=169.254.128.3 LEN=28 TOS=0x00 PREC=0x00 TTL=64 ID=23451 PROTO=ICMP TYPE=0 CODE=0 ID=50284 SEQ=34394
6.3 利用 iptables 规则跟踪丢包
还记得 netfilter 框架的的 5 个hook点吗?

从图中可以看到,接收到报文,路由前,路由后,发送报文,都可以在配置 iptables 规则来进行跟踪。先梳理清楚数据包经过的 hook 点,接着配置 iptables 规则,使得协议命中但不会产生具体的动作,比如对于 ipsec 协议,通过以下两条规则统计的报文数观察在 OUTPUT 之后到 POSTROUTING 之间的丢包个数:
[root@centos ~]# iptables -t mangle -I OUTPUT -p esp
[root@centos ~]# iptables -t mangle -I POSTROUTING -p esp7 总结
除了上面介绍的一些场景外,还有很多其他的场景,比如 ip 层分片重组导致的丢包、tc配置的丢包等等,这里不再一一举例来说明了。总的来说,多总结,多思考,善于使用 linux 内核提供给我们的工具,才能更好的排查问题。
















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











