









乍一听,这个文件压缩的名字貌似是很高大上的,其实,在数据结构中学完Huffman树之后,就可以理解这个东西其实不是那么的高不可攀。
文件压缩
所谓文件压缩,其实就是将对应的字符编码转换为另一种占据字节数较少的编码来进行存储。
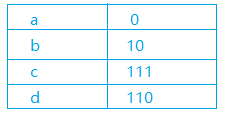
举个栗子:有一串文本:aaaabbbccd,其中单独将这串字符存放在文件中,它所占据的将会是至少10个字节(为什么说是至少,因为还有一些必要的文件信息要保存的说)。由此就有人尝试着要以重新编码,然后再存储的方式来节约我们宝贵的磁盘空间以及传输时间。还是这个字符串,其中a出现了4次,b出现3次,c出现2次,d只出现了一次。由此我们可以重新编码:
什么意思呢?我们按表这个来编码,a对应0,b对应10,依此类推,可以将原字符串转换为00001010 10111111 110,用二进制位来代替原有的字符,这样将出现次数较多的字符替换为较短的编码,便实现了对字符串的压缩。字符串中字符的出现次数可以遍历一遍统计出来,那么现在的问题就是如何得到这样的编码了!
Huffman树
Huffman的定义:假设给定一个有n个权值的集合{w1,w2,w3,…,wn},其中wi>0(1<=i<=n)。若T是一棵有n个 叶结点的二叉树,而且将权值w1,w2,w3…wn分别赋值给T的n个叶结点,则称T是权值为 w1,w2,w3…wn的扩充二叉树。带有权值的叶节点叫着扩充二叉树的外结点,其余不带权值 的分支结点叫做内结点。外结点的带权路径长度为T的根节点到该结点的路径长度与该结点上的权值的乘积。
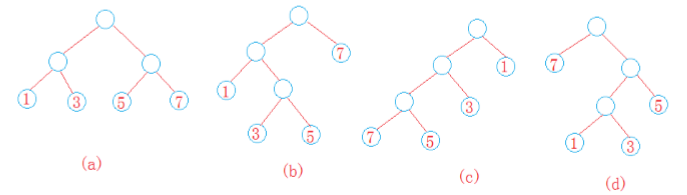
说的有些偏理论,看个图:
如上,所有的叶子节点处有所谓的权值,从根结点到某一叶子节点的分支个数为对应的路径长度,如(a)中的权重为1的结点,它的路径长度为2,路径和权值的乘积为2,这颗树的带权路径长度为 1*2 + 3*2 + 5*2 + 7*2 = 32;(b)(c)就不计算了,(d)为7*1 + 1*3 + 3*3 + 5*2 = 29.像(d)这样的带权路径长度最短的树就叫做Huffman树,也叫做最优二叉树。
Huffman树的创建
- 、由给定的n个权值{w1,w2,w3,…,wn}构造n棵只有根节点的扩充二叉树森林F= {T1,T2,T3,…,Tn},其中每棵扩充二叉树Ti只有一个带权值wi的根节点,左右孩子均为 空。
- 、重复以下步骤,直到F中只剩下一棵树为止:
a、在F中选取两棵根节点的权值最小的扩充二叉树,作为左右子树构造一棵新的二叉树。将新二叉树的根节点的权值为其左 右子树上根节点的权值之和。
b、在F中删除这两棵二叉树;
c、把新的二叉树加入到F中;
最后得到的就是Huffman树。
由于每次要从森林中选取权重最小的两棵树,当然用堆来实现会比较方便,我这里用的是标准模板库中的优先级队列实现的,底层也是堆。具体的代码太长,附上链接:Huffman.hpp:https://github.com/Fireplusplus/Data-Structure/blob/master/HuffmanTree.cpp
Huffman编码
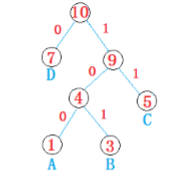
再创建好的Huffman树的分支上标记,左分支标记0,右分支标记1,这样,有根结点到某个叶子节点路径上的01序列即为要求得Huffman编码。如图:
7的编码为0, 1的编码为100,3的编码为101, 5的编码为11. (Huffman树不是唯一的,编码也不是唯一的)
由这种方法得到的编码是前缀编码:任何一个字符的编码不是另一个字符编码的前缀。 这样才能保证译码的唯一性。
理清了所有思路,实现起来就不难了!
实现
大概的说一下是怎么实现的:
压缩:
- 遍历一次文件,统计对应字符出现次数
- 创建Huffman树
- 得到Huffman编码
- 将解压缩必要信息保存到目标文件首部(我的实现:原文件扩展名,后续字符行数,字符与对应次数,数据部分)(以‘\n’分隔)
- 按编码将对应字符转换(位运算)
- 保存
解压:
- 取出文件头部信息
- 设置字符与对应出现次数
- 以同种算法创建Huffman树
- 解码(编码对应的原字符可由从根结点开始,0走左,1走右,直到遇到叶子节点,则为对应字符)
- 保存
效果
尝试着将其中的某个源文件进行压缩,原大小8字节,压缩后变为6字节,节省了2字节的存储空间。(ps:gl是我瞎编的扩展名)
具体能缩减多少空间就还要看具体字符出现的频率了。解压后所有字符均与原文件相同。当然也可以压图片:
压缩前(左)与压缩后(再解压后)(右)对比:

a: 看起来没什么不同嘛!=_=||
b: 没什么不同才叫解压哈! =_=||
遇到的问题
1.问题:个别字符处理解析错误。原因分析:GetLine函数没有考虑到‘\n’的特殊性,混淆可分隔用的‘\n’与行结束标志‘\n’。解决方法:重新考虑遇到‘\n’的特殊情况,修正GetLine函数。
2.问题:解压后文件不全,体现为无后半部分。原因分析:从文件中读取字符时,遇到了假的EOF标志(某字符为有意义的字符,却和EOF有着相同的位)。解决方法:文件操作时均采用二进制方式读写。
3.问题:解压后的文件每个1024个字符就出现乱码。原因分析:文件解压缩时每次读取1024个字节到ReadBuf里,然后对读进来的每个字节(放在char变量里)进行位操作,用pos标志来标记当前处理到的位,解码后的字符放在WriteBuf里。但是ReadBuf中一轮数据处理完成后读取后1024个字节,这时重新清零了pos标志,导致当前char变量中剩余的位没有处理。解决方法:将pos的位置移到读操作循环的外部。(ps:就这个小bug着实耗费了我很长时间=_=||)
其它的都是一些小问题,就不一一罗列了。
GitHub链接
最后,本着资源共享,共同学习的精神,放上项目的开源链接(源代码有详细注释):
https://github.com/Fireplusplus/Project/tree/master/FileCompress
用C++实现文件压缩

于 2016-08-15 00:28:43 首次发布

















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











