






题目:给定单向链表的头指针和一个结点指针,定义一个函数在O(1)时间删除该结点。链表结点与函数的定义如下:
typedef struct ListNode { int val; struct ListNode *p_next; }NODE, *PNODE;
void delete_node(PNODE *pListHead, PNODE pToDeleted);一般来说,我们拿到一个删除链表的某个结点的题目,最常规的解法无疑是从链表的头结点开始顺序遍历,依次查找要删除的结点,找到被删除结点的前一个结点后,就可以在链表中删除结点。就像下面这样:
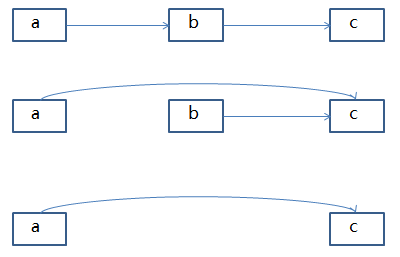
假设要删除的结点是b,那就先找到b的前一个结点a,然后使a的下一个结点变为c,最后释放b。当然如果整个链表中只有一个结点为b结点,那么b就是头结点了,算是一种特殊情况。
显而易见,因为这个算法需要遍历整个链表,所以它的时间复杂度是O(n)。并不是我们想要的结果。那就只好另辟蹊径了。
图示如下:
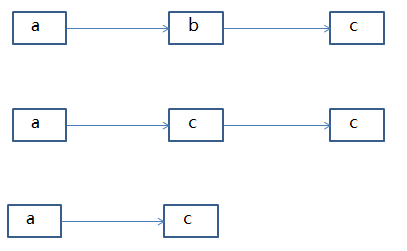
这种思路的做法是,因为我们要删的结点是b,而且已经给了指向b结点的指针,那么我们可以在O(1)时间内直接找到的结点就是它了。找到了b结点,那么b的下一个结点c肯定也找到了,我们用c的值覆盖掉b,然后在删掉最后的c结点。这样不也相当于删除了结点b吗?而且时间复杂度自然是O(1)了。
这个思路还有一个问题,就是如果要删除的结点是尾结点怎么办,那它就没有下一个结点了,这种情况下我们只好采用第一种思路了。
最后需要注意的是,如果链表中只有一个结点,而我们删除的就是头结点,那么在删除结点之后,还需要把头结点置为NULL。
下面就是这种思路的具体实现了:
再来分析一下这个思路的时间复杂度,对(n-1)个非尾结点而言,时间复杂度为O(1);而对于尾结点而言,由于仍然需要遍历查找,所以时间复杂度是O(n)。void delete_node(PNODE *pListHead, PNODE pToDeleted) { //假设前提:链表中存在pToDeleted这个结点 if ((NULL == pListHead) || (NULL == *pListHead) || (NULL == pToDeleted)) return; if ((*pListHead)->val == pToDeleted->val) //待删结点是头指针 { PNODE tmp = *pListHead; *pListHead = tmp->p_next; free(tmp); tmp = NULL; } else if (NULL != pToDeleted->p_next && (*pListHead)->val != pToDeleted->val) //待删结点不是尾指针也不是头指针 { PNODE next = pToDeleted->p_next; pToDeleted->val = next->val; pToDeleted->p_next = next->p_next; free(next); next = NULL; } else //是尾指针但不是头指针,需要遍历整个链表 { PNODE tmp = *pListHead; while (tmp->p_next->val != pToDeleted->val) { tmp = tmp->p_next; } free(pToDeleted); pToDeleted = NULL; tmp->p_next = NULL; } } void print(PNODE head) { while (NULL != head) { printf("%d ", head->val); head = head->p_next; } printf("\n"); } int main() { PNODE p1, p2, p3; PNODE head = NULL; p1 = (PNODE)malloc(sizeof(NODE)); p2 = (PNODE)malloc(sizeof(NODE)); p3 = (PNODE)malloc(sizeof(NODE)); p1->val = 1; p2->val = 2; p3->val = 3; p1->p_next = p2; p2->p_next = p3; p3->p_next = NULL; head = p1; print(head); delete_node(&head, p1); print(head); delete_node(&head, p3); print(head); delete_node(&head, p2); }所以总的平均时间复杂度是[(n - 1) * O(1) + 1 * O(n)] / n ,结果仍然是O(1)。
还要注意的是,上边我们写的代码并不是完整的代码。仔细想想,我们就可以发现,这个程序是建立在要删除的结点一定在链表上存在的基础上。但是要判断一个1结点是否在链表上,需要O(n)的时间复杂度。所以保证链表上存在要删除的结点这一责任就抛给了这个函数的调用者。这是不得已而为之。
O(1)时间删除链表结点
最新推荐文章于 2019-09-19 21:13:37 发布

















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











