







其他链接:
java mybatis分批次批量插入
https://blog.csdn.net/qq_33745371/article/details/106840104
mybatis进行百万批量插入(我行),mysql进行百万批量插入(我不行)
https://blog.csdn.net/qq_33745371/article/details/106630478
mysql新建数据库字符集和排序规则
https://blog.csdn.net/qq_33745371/article/details/106459524
文章目录
背景介绍
数据库有50万条数据,1.有索引的短字段,2.无索引的短字段,3.有索引的长字段,4.无索引的长字段
------------------2020/8/19--------------------
后续我又新增了1500万数据进行了测试,对文章进行了更改
先上结论
少量数据(50万),无脑选like,不要选locate
大量数据(1500万)分结论:基本可以无脑选like
除了这种情况!1结论(唯一败北),查出245140条相关数据,like耗时71秒,locate耗时58秒。
1结论:字段有索引,且字段短时,like < locate(唯一败北)
2结论:.字段无索引,且字段短时,like ≈ locate
3结论:字段有索引,且字段长时,like >> locate(like完胜)
4结论:字段无索引,且字段长时,like >> locate(like完胜)
网盘链接
百度网盘链接
提取码:q1bh
网盘有生成50万数据的java代码,和仅有表结构无数据的sql文件(person.sql),也有直接带50万数据的sql文件(batchdemo.sql)。

表字段:
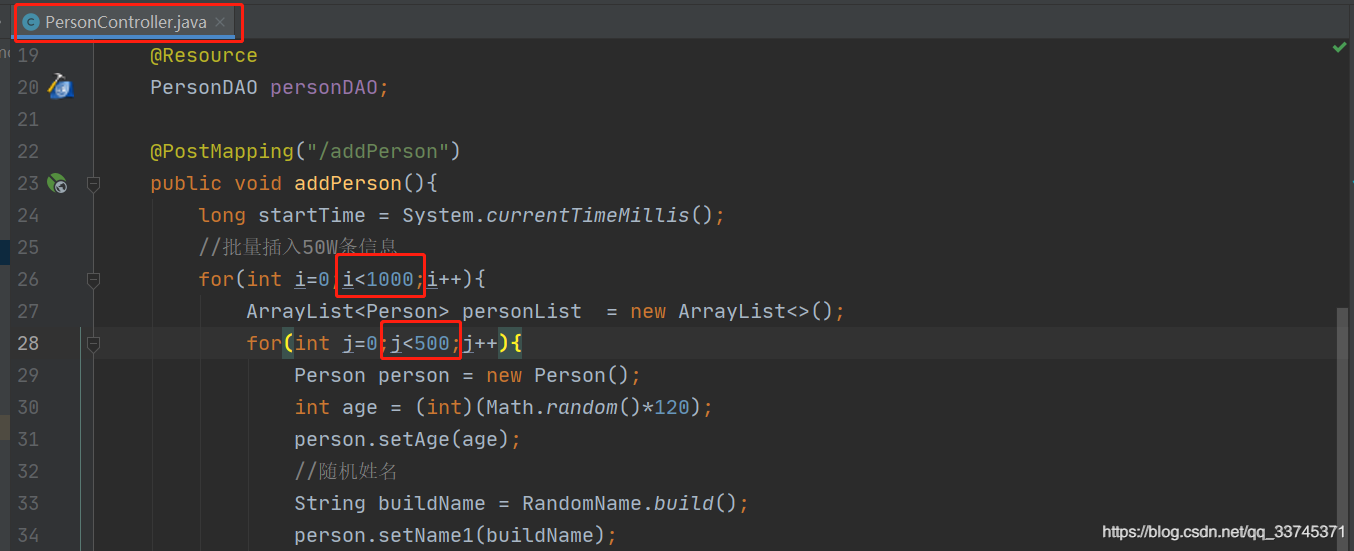
修改代码,提升数据库数据数量
如果觉得50万数据少,想自己测试的可以去网盘下载我的,改一个数值进行更大量的测试。
在PersonController类修改,1000表示循环插入1000次,500表示一条sql有500个value。
相乘就是插入的总条数50万。你可以把1000改成一万,这样就会生成500万条数据。
50万条数据大概花了我7分钟,别着急。
sql语句,查询时间,及分析比较
-- 第1组对照(字段值短且有索引)
-- like查询带索引的姓名1(不走索引)
-- 50万所需要的时间均值:3秒 数据条数:8159
-- 1500万所需要的时间均值:58秒 数据条数:245140
select * from person where name1 like CONCAT("%","齐","%")
-- like查询带索引的姓名1(走索引)
-- 50万所需要的时间均值:1.5秒 数据条数:8159
-- 1500万所需要的时间均值:71秒 数据条数:245140
select * from person where name1 like CONCAT("齐","%")
-- locate查询带索引的姓名1
-- 50万所需要的时间均值:3 数据条数:8159
-- 1500万所需要的时间均值:58秒 数据条数:245140
select * from person where LOCATE("齐",name1)
-- 第2组对照(字段值短,无索引)
-- like查询姓名2
-- 50万所需要的时间均值:7秒 数据条数:8159
-- 1500万所需要的时间均值:58秒 数据条数:245140
select * from person where name2 like CONCAT("%","齐","%")
-- 50万所需要的时间均值:7秒 数据条数:8159
-- 1500万所需要的时间均值:58秒 数据条数:245140
select * from person where name2 like CONCAT("齐","%")
-- locate查询姓名2
-- 50万所需要的时间均值:7秒 数据条数:8159
-- 1500万所需要的时间均值:58秒 数据条数:245140
select * from person where LOCATE("齐",name2)
-- 第3组对照(字段值长且有索引)
-- like查询带索引的文章1(不走索引)
-- 50万所需要的时间均值:8秒 数据条数:6261
-- 1500万所需要的时间均值:91秒 数据条数:181873
select * from person where article1 like CONCAT("%","齐","%")
-- like查询带索引的文章1(走索引)
-- 50万所需要的时间均值:0.004秒 数据条数:24
-- 1500万所需要的时间均值:0.25秒 数据条数:708
select * from person where article1 like CONCAT("齐","%")
-- locate查询带索引的文章1
-- 50万所需要的时间均值:10秒 数据条数:6261
-- 1500万所需要的时间均值:122秒 数据条数:181873
select * from person where LOCATE("齐",article1)
-- 第4组对照(字段值长无索引)
-- like查询带索引的文章2
-- 50万所需要的时间均值:8秒 数据条数:6261
-- 1500万所需要的时间均值:78秒 数据条数:181873
select * from person where article2 like CONCAT("%","齐","%")
-- like查询带索引的文章2
-- 50万所需要的时间均值:7秒 数据条数:24
-- 1500万所需要的时间均值:57秒 数据条数:708
select * from person where article2 like CONCAT("齐","%")
-- locate查询带索引的文章2
-- 50万所需要的时间均值:10秒 数据条数:6261
-- 1500万所需要的时间均值:128秒 数据条数:181873
select * from person where LOCATE("齐",article2)

















 1676
1676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











