






sed:擅长数据修改。
grep:擅长数据查找定位。
awk:擅长数据切片,数据格式化,功能最复杂。
参考书籍《Linux Shell核心编程指南》
sed简述
sed是贝尔实验室的Lee E.McMahon在1973年到1974年开发的流编辑器,sed是基于交互式行编辑器ed开发的软件。sed主要用于对文本进行处理和转换。
流编辑器:
流编辑器是一种用于处理文本或二进制数据流的编辑器。它们通常用于处理大型文件或多行文本,并提供了一种快速和高效
的方式来编辑这些数据流。以下是一些流编辑器的使用场景:
1. 大型文本文件:当处理大型文本文件时,流编辑器可以更快地打开和编辑这些文件。这是因为流编辑器不需要将整个文件
加载到内存中,而是可以逐行或逐段地读取和编辑文件。
2. 编程:流编辑器通常用于编程,因为它们可以更快地处理和编辑文本和二进制数据。例如,在编写程序时,流编辑器可以
用于读取和写入文件,以及处理输入和输出数据流。
3. 数据转换:流编辑器可以用于处理文本和二进制数据的转换。例如,在数据清洗和转换过程中,流编辑器可以用于将数据
从一种格式转换为另一种格式。
4. 系统管理:流编辑器也可以用于系统管理任务,例如备份和还原文件,或者在服务器上编辑日志文件。
总之,流编辑器是一种非常有用的工具,可以用于处理大量文本和二进制数据,以及进行数据转换和编程任务。
处理文本的简史:
在操作系统刚出现的时候,文本处理通常需要使用一些基础的命令行工具和编程语言来完成。以下是一些早期的文本处理方法:
1. 使用命令行工具:早期的操作系统通常提供了一些基础的命令行工具,例如grep、sed、awk等,可以用于搜索、替换和处理文本。
这些工具通常需要手动输入命令来完成文本操作,并且需要一些基本的命令行知识。
2. 使用编程语言:早期的操作系统也支持一些编程语言,例如C语言和汇编语言等,可以用于处理文本和二进制数据。这些编程语言
需要一些基础的编程知识,例如语法、变量和函数等。
3. 使用文本编辑器:早期的操作系统通常也提供了一些文本编辑器,例如vi、emacs等,可以用于编辑文本文件。这些文本编辑器通常
需要一些学习和熟练的操作,才能完成一些复杂的文本操作。
总之,在操作系统刚出现的时候,处理文本需要使用一些基础的工具和方法,并且需要一些基本的命令行知识和编程经验。随着操作系统
和编程语言的发展,文本处理变得更加方便和高效,并且可以通过编程来扩展其功能。
sed与ed的区别:
sed(Stream Editor)和ed(Editor)都是用于编辑文本文件的命令行工具,但它们有以下几个主要区别:
1. 工作方式:ed是一个全屏的文本编辑器,需要手动输入命令来编辑文件。sed则是一种基于行的文本编辑器,它
可以通过命令行输入来编辑文件。
2. 语法:ed使用一种类似于英语的语法来编辑文件,需要输入一些命令来完成编辑操作。sed使用一种简单的命令语
法,可以使用正则表达式来匹配和替换文本。
3. 功能:ed可以执行一些高级编辑操作,例如在文本中进行搜索和替换,插入和删除行,以及在文件中跳转等。
sed则更适合进行简单的文本编辑和转换操作。
4. 学习曲线:ed的语法相对较为复杂,需要花费一定的时间和精力来学习和掌握。sed则比较容易上使用,
因为它的语法比较简单,并且可以使用一些命令行选项来简化编辑操作。
总之,sed和ed都是非常强大的文本编辑器,它们都有自己的优点和适用场景。如果需要进行高级的文本编辑和转换操作,
可以选择ed;如果只需要进行简单的文本编辑和转换操作,可以选择sed。
sed数据处理基本流程
sed为行编辑器,在此基础之上,sed的处理流程:
1、sed会逐行扫描输入的数据,并将读取的数据内容复制到缓冲区(又称模式空间)。
2、拿模式空间中的数据与给定的条件进行匹配。
3、匹配成功,执行特定的sed指令。
4、匹配失败,跳过输入的数据行。
5、从输入的数据取下一行数据到模式空间,然后转到第2步继续,直到输入的数据处理
完毕。
注:默认情况下sed会把最终的数据结果通过标准输出显示在屏幕上。
stdout: 标准输出
stdin:标准输入
sed语法格式
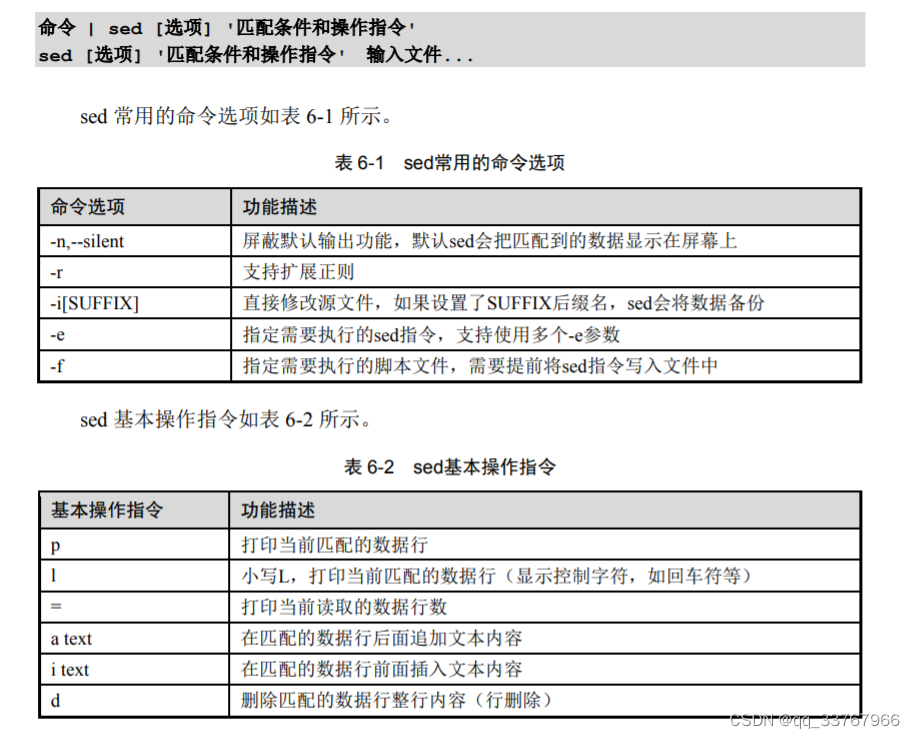
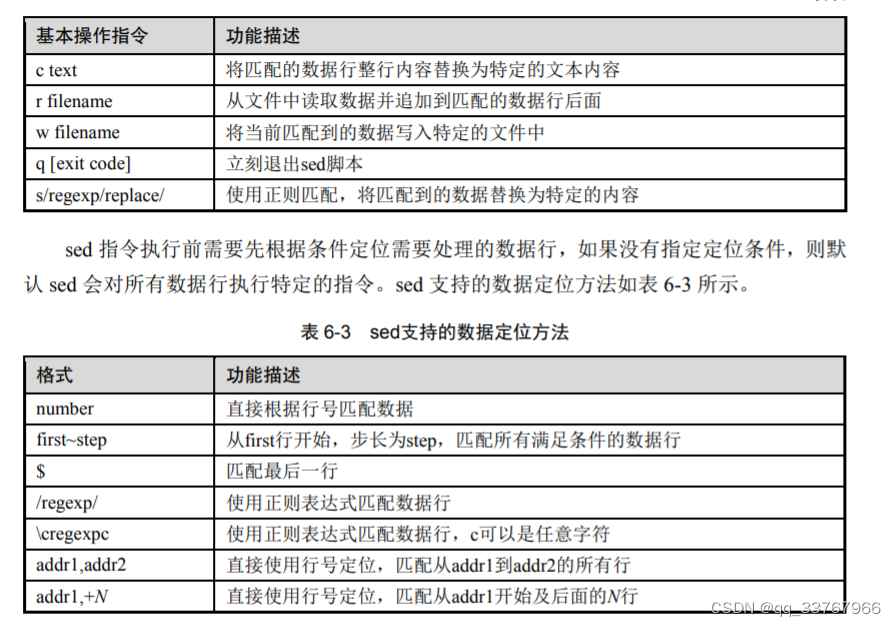
sed的主要功能:
sed主要用于对文本进行处理和替换。
文件内容新增、删除、替换、取出某个范围的内容。
1、替换文本
‘s/查找的文本/替换的文本/g’
逐行将“查找的文本”替换成“替换的文本”,其中查找的文件可以使用正则表达式。
以下是几个使用sed命令替换文本的例子:
- 将文件中所有的"old"替换为"new":
sed 's/old/new/g' file.txt
- 将文件中的所有空格替换为下划线:
sed 's/ /_/g' file.txt
- 将文件中的"hello"替换为"world",并将结果输出到新文件中:
sed 's/hello/world/g' file.txt > newfile.txt
- 正则表达式实现将所有的数字替换为-1 s/[[:digit:]]/-1/g
sed -r 's/\d\+/-1/g' nowcode.txt > nowcode_tmp.txt
- 替换文件指定字符
sed -i 's/<old_string>/<new_string>/g' <filename>
- 与find匹配使用
find . -type f -name "*.txt" -exec sed -i 's/old_string/new_string/g' {} +
这些例子只是sed命令的一小部分,sed还支持更多的文本处理操作和参数选项。需要注意的是,sed命令对文本进行修改时,会直接修改原文件,因此需要谨慎使用。如果需要将结果输出到新文件中,可以使用重定向符号">"。
2、删除文本
d:delete(删除),删除文本流中的特定行。
可以根据行号和模式匹配进行操作。
- 将文件中以"#"开头的行删除:
sed '/^#/d' file.txt
- 多行删除
sed 'N;/^#/d' file.txt
3、插入文本
-i[后缀],若没有后缀,则表示直接回写到原文件。
有后缀则会写到文件名+后缀的文件里边去。
i:insert(插入),会在指定行前增加一个新行
a:append(附加),会在指定行后增加一个新行
- 插入一行文本:
sed '1i\This is an inserted line' nowcoder.txt
- 增加一行文本
sed '1a\This is an appended line.' nowcoder.txt
4、执行脚本
sed -f <script name> <file name>
其中,<\script name>表示要执行的脚本名称,<file name>是
需要处理的输入文件的文件名。
也可以直接在命令行中执行一个简短的脚本,格式如下:
sed 'start.sh' input.txt
sed -f 'awkDemo.sh' nowcoder.txt
5、支持正则表达式
正则表达式识别的特殊字符包括: .*[]^${}+?|()
. 匹配除换行符之外的任意一个字符,只能匹配一个字符。
* 匹配它之前一个字符或者一个正则表达式0至若干次。
^ 匹配一行的开始。
sed -r 拓展
+ 匹配它前边字符一次或多次
#!/bin/bash
baseHome=/home/lch/learn/shell/practice
cd $baseHome || exit
# 所有数据行显示一次
#sed -n 'p' nowcoder.txt
# 显示最后一行
#sed -n '$p' nowcoder.txt
# 正则匹配显示行 [[:digit:]]
sed -n '/main*/p' nowcoder.txt
# \(..\) 用于匹配子串 对于匹配到的第一个子串就标记为 \1,依此类推匹配到的第二个结果就是 \2
sed -n '/\([0-9]\+\)/p' nowcoder.txt
# 匹配字母s开头包含任意3个字符且以:x结尾的数据行
#sed -n '/s...:x/p' nowcoder.txt
# 匹配以ftp开头的
#sed -n '/^http/p' nowcoder.txt
# 从管道读取数据并写入文件
if [ -f "$baseHome/process.txt" ]; then
rm $baseHome/process.txt
fi
ps -ef | sed -n 'p' > $baseHome/process.txt
# 正则表达式实现将所有的数字替换为原有数字后边跟两个字符(-1)
# \(..\) 用于匹配子串 对于匹配到的第一个子串就标记为 \1,依此类推匹配到的第二个结果就是 \2
sed 's/\([0-9]\+\)/\1-1/g' nowcoder.txt > nowcoder_tmp.txt
正则?
在正则表达式中,`pattern`是用来匹配文本中的模式的。它可以是一个字符、一个字符集、一个重复结构、
一个限定符等等,用于描述要匹配的模式的规则。
例如,正则表达式`\d+`可以匹配一个或多个数字,`[a-zA-Z]+`可以匹配一个或多个字母,`\w+`可以匹配
一个或多个字母、数字或下划线,`(pattern1)|(pattern2)`可以匹配`pattern1`或`pattern2`中的任何一个。
在使用正则表达式时,我们需要根据具体的需求来编写合适的模式,以便能够准确地匹配到所需的文本。
正则表达式引擎的底层实现通常是通过使用有限状态自动机(Finite State Automata,FSA)或非确定性有限状态
自动机(Non-Deterministic Finite State Automata,NFA)来实现的。
FSA是一种能够接受有限个输入符号并从这些符号的有限个组合中转移的自动机。在正则表达式引擎中,FSA通常被用来
匹配正则表达式中的模式。
NFA是一种能够接受无限个输入符号并从这些符号的无限个组合中转移的自动机。在正则表达式引擎中,NFA通常被用来
匹配一些复杂的正则表达式模式,如重复结构和可选项等。
在实现正则表达式引擎时,通常会将正则表达式转换为FSA或NFA的形式,然后使用这些自动机来匹配输入文本。具体的
实现方式可能会有所不同,但通常都会涉及到状态转换、输入符号的处理、状态转移等基本的概念和算法。
除了FSA和NFA,还有一些其他的算法和数据结构可以用来实现正则表达式引擎,如回溯算法、堆栈、Trie树等。不同的
实现方式可能会有不同的性能和适用场景,需要根据具体的需求来选择合适的实现方式。














 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









