






人工智能在大数据的催化之下,应用愈加广泛,在各个场景中都能见到它的身影。新技术、高薪资吸引着一批又一批的开发者,但大多数人,却被它看起来似乎很“高大上”的学习门槛束缚住了手脚。
本场Chat主要讲解一个极简的案例,在数据分析任务中使用机器学习进行结果的预测。帮助大家快速理清工作流程,快速掌握入门知识。并减少环境搭建使用的时间,开箱即用,助力更高质量的学习。
开发语言使用Python3,数据处理使用Numpy、Pandas,机器学习使用Sklearn,可视化绘制使用Matplotlib。
而在本场Chat中,主要会讲解到以下内容:
- 快速启动机器学习环境
- 信用卡审批案例
- Numpy、Pandas数据处理
- 机器学习Sklearn
- Matplotlib可视化探索
适合人群:想快速入门机器学习,掌握基本工作流程的技术人员
前言
本教程内容,主要目的是帮助数据分析和机器学习的新手玩家快速了解开发流程,并运用于实战。
整体讲解数据分析的整体流程,并结合一个极简案例——信用卡审批,快速上手数据分析,使用机器学习算子,完成结果的预测。
开发语言使用Python3,数据处理使用Numpy、Pandas,机器学习使用Sklearn,可视化绘制使用Matplotlib。
环境准备
环境搭建对于初学者而言,花费时间较长,甚至可能是入门到劝退的节奏。所以最好减少环境上花费的时间,使用开箱即用的环境。这里机器学习的开发环境直接使用腾讯云的CloudStudio,或阿里云的天池实验室(但目前天池实验室应该不能用了,有限制)。
腾讯云CloudStudio:(https://cloud.tencent.com/product/cloudstudio)
阿里云天池实验室(https://tianchi.aliyun.com/notebook-ai)

数据分析流程

数据分析的流程,整体分为:分析目的、数据采集、数据预处理、数据分析、数据展现、数据报告,一共6部分内容。
分析目的
在开始一个项目之前,需要数据分析的最终目的,然后评估可行性。一般而言,只有数据量足够大的情况下,数据分析的结果才较为准确,当然尤其是机器学习,对数据量的要求更大。这也是为什么在大数据兴起后,机器学习才慢慢火了起来。
我们这次的学习目的是创建模型,完成信用卡的自动审批。虽然数据量不大,但因为毕竟是Demo,体会整体开发流程即可。
数据采集
确定项目后,需要从数据源将需要的数据,使用采集工具进行采集。一般数据都存储在数据仓库中,当然有时候为了分析的需要,也需要额外的数据支撑,如使用爬虫、采集日志数据、购买第三方数据。
此次需要的数据,已经上传到百度网盘中,直接提取即可。
链接:https://pan.baidu.com/s/1okfy302PIap6tRzGPy23wA
提取码:htnn
数据下载好后,上传到环境中,可以直接拖拽到目录中(CloudStudio也是一样)。

数据预处理
1.数据筛选
数据获取回来之后,汇总为一个大的数据集,这时就需要对数据进行分析、提取;这里已经属于特征工程的范畴了。
特征工程:顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。特征工程和数据转换其实是等价的。事实上,特征工程是一个迭代过程,我们需要不断的设计特征、选择特征、建立模型、评估模型,然后才能得到最终的模型。
在收集回来的全部数据中,选择可以使用到的特征(即在数据表中,选择合适的字段),并且根据需要计算生成其他的衍生列。
此项目中的数据,已经是完成筛选后的数据,不需要操作。
2.数据处理
在筛选后的数据中, 需要对数据进行探索,即使用可视化的图表,查看数据的分布情况。查看哪些数据分布不均匀,哪些数据需要干预处理。
首先,完成数据的可视化探索,对数据有个直观的印象。
1、导入必要的numpy、pandas数据处理包;sklearn机器学习包;matplotlib可视化绘制包;
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import numpy as np
from matplotlib import pyplot as plt

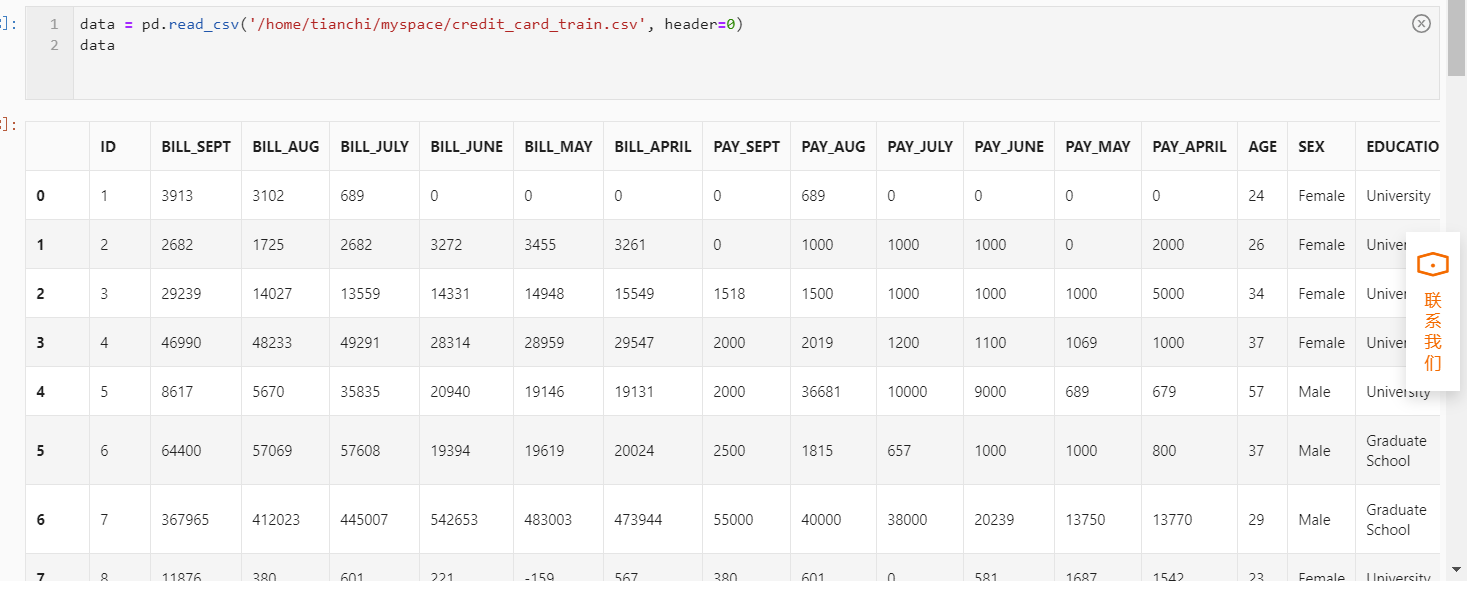
2、使用pandas加载credit_card_train.csv数据集。
data = pd.read_csv('credit_card_train.csv', header=0)
data
使用matplotlib对数据进行可视化探索,直观探求数据间的关系
# 定义画布的行数、列数
fig = plt.figure(figsize=(25, 15))
cols = 5
rows = np.ceil(float(data.shape[1]) / cols)
# 对数据集中的每一列的数值绘制直方图
for i, column in enumerate(data.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if data.dtypes[column] == np.object:
data[column].value_counts().plot(kind="bar", axes=ax)
else:
data[column].hist(axes=ax)
plt.xticks(rotation="vertical")
plt.subplots_adjust(hspace=0.7, wspace=0.2)

可视化探索后,发现一些问题:机器学习的模型训练,只能使用数字类型,而数据中出现了非数字类型。

所以,首先对非数字类型进行转换,转换方法有One-Hot与序号编码。
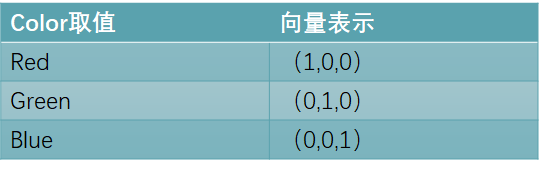
One-hot(也叫One-of-k)的方法把每个无序特征转化为一个数值向量。比如一个无序特征color有三种取值:red,green,blue,之间并无大小顺序关系。那么可以用一个长度为3的向量来表示它,向量中的各个值分别对应于red,green,blue。
序号编码的方法可以将有序特征转化为可比较(包含大小关系)的数值。比如研究学历和信贷额度之间的关系时,惯用做法是将不同学历的人编成相应的序数编码。

而项目案例中的’SEX’、‘EDUCATION’、 'MARRIAGE’这三列数据,并没有有序的特征,不包含大小关系。所以可以直接使用One-Hot编码进行转换。
data = pd.get_dummies(data, columns=['SEX', 'EDUCATION', 'MARRIAGE'])
data
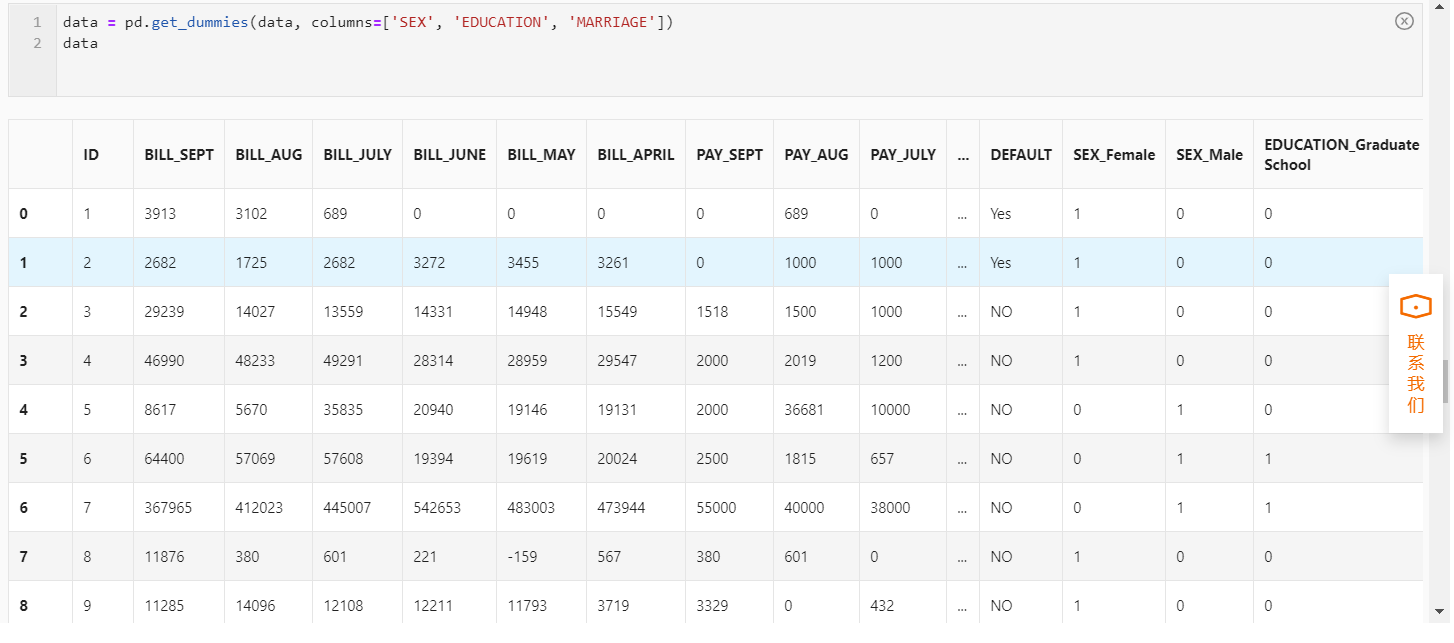
剩下的DEFAULT列比较特殊,是用于标记结果的,称为目标值,除此之外的其它列数据是特征值。DEFAULT部分的Yes表示信用卡审批通过,No表示未通过。
在大部分机器学习模型中,目标值和特征值缺一不可,用来训练模型。训练原理是,通过数学方法,发现特征值与目标值之间的关系,最终计算出它们的数学表达式。假设要探究气温(x1)、当前时间(x2)、地理位置(x3)与天气状况(y)的关系,通过大量的计算,可以得出一个最优的近似关系y=a(x1)+b(x2)+c(x3)。那这个关系式就是模型。之后有新的数据进入,只需要带入式子中,就能得到结果,从而完成预测。
机器学习模型的训练,需要将特征值和目标值拆分出来。一般习惯将结果列放置在数据集最后,便于拆分特征值和目标值。所以接下来先处理位置关系,然后再将结果列的字符串使用sklearn内置方法转换为数值类型0、1。
# 将结果列DEFAULT移动到最后
columns = list(data.columns)
columns.remove('DEFAULT')
columns.append('DEFAULT')
data = data.reindex(columns=columns)
# 定义特征和目标值
feature = data.iloc[:, 1:23].values
target = data['DEFAULT'].values
# 将目标值YES、NO转换为数字0、1
from sklearn.preprocessing import LabelEncoder
target = LabelEncoder().fit_transform(target)
target

数据分析
数据处理好之后,可以使用传统数据挖掘、机器学习等方法进行分析。
这里使用机器学习的方法进行,为了测试模型的性能,将数据集整体拆分为训练集、测试集,分别进行模型训练和测试。
在Sklearn中,机器学习算子被封装为类,直接使用其实例化对象即可。然后调用fit方法,对训练数据进行拟合,以便获得针对当前数据集的模型。
模型训练结束后,调用score方法,使用测试数据集来判断模型的准确率。
# 切分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(feature, target, test_size=0.2)
# 训练随机森林分类器
model = RandomForestClassifier()
model.fit(X_train, Y_train)
# 对模型的准确率进行测试
score = model.score(X_test, Y_test)
score

可以看到模型的准确率为0.765,对于小批量数据来说,还算不错。
如果在大规模数据训练的情况下,模型的准确率并不高,那就需要考虑更换其它机器学习算子,或者为当前机器学习的算子调整参数。所以有时候也戏称人工智能工程师为调参工程师。
数据展现&数据报告
机器学习主要进行预测,然后将预测结果返回到业务系统,辅助业务系统完成某一功能。例如本案例,结果将返回给业务系统,辅助信用卡自动审批。这也可以算作数据展现的一种方式,而传统意义上的数据分析,更多的是以图表的形式进行展示。对于领导决策层而言,分析结果形成数据报告,是辅助决策的一种手段。
总结
本次分享,主要以最小案例进行讲解,演示在数据分析工作中,使用机器学习算子进行预测的基本流程。
也告诉大家,其实机器学习并没有那么难以上手,掌握了大体流程之后,只需要熟悉更多机器学习算子的用法和使用场景,应付日常的工作基本上没有问题。但要想成为一个专业的人工智能工程师,个中艰辛,还需要自行学习,慢慢体会。
一起动手,一起进步,Come On!
两杯咖啡的价格,加入数舟星球,获取30+大数据技术专栏,涵盖Hadoop、Spark、Hive、Flink、HBase、Kafka等入门到实战。
在星球内的同学,会为大家分享一些数据分析的案例代码和学习资料,祝大家学习愉快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











