







目录
Containerd介绍
Containerd和Docker的关系
在学习 Containerd 之前我们有必要对 Docker 的发展历史做一个简单的回顾。
从 Docker 1.11 版本开始,Docker 容器运行就不是简单通过 Docker Daemon 来启动了,而是通过集成 containerd、runc 等多个组件来完成的。虽然 Docker Daemon 守护进程模块在不停的重构,但是基本功能和定位没有太大的变化,一直都是 CS 架构,守护进程负责和 Docker Client 端交互,并管理 Docker 镜像和容器。现在的架构中组件 containerd 就会负责集群节点上容器的生命周期管理,并向上为 Docker Daemon 提供 gRPC 接口。
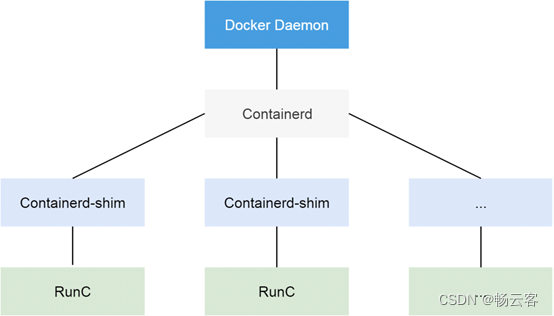
当我们要创建一个容器的时候,现在 Docker Daemon 并不能直接帮我们创建了,而是请求 containerd 来创建一个容器,containerd 收到请求后,也并不会直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让这个进程去操作容器,我们指定容器进程是需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的,假如这个父进程就是 containerd,那如果 containerd 挂掉的话,整个宿主机上所有的容器都得退出了,而引入 containerd-shim 这个垫片就可以来规避这个问题了。
然后创建容器需要做一些 namespaces 和 cgroups 的配置,以及挂载 root 文件系统等操作,这些操作其实已经有了标准的规范,那就是 OCI(开放容器标准),runc 就是它的一个参考实现(Docker 被逼无耐将 libcontainer 捐献出来改名为 runc 的),这个标准其实就是一个文档,主要规定了容器镜像的结构、以及容器需要接收哪些操作指令,比如 create、start、stop、delete 等这些命令。runc 就可以按照这个 OCI 文档来创建一个符合规范的容器,既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时都是符合 OCI 标准的。
所以真正启动容器是通过 containerd-shim 去调用 runc 来启动容器的,runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。
而 Docker 将容器操作都迁移到 containerd 中去是因为当前做 Swarm,想要进军 PaaS 市场,做了这个架构切分,让 Docker Daemon 专门去负责上层的封装编排,当然后面的结果我们知道 Swarm 在 Kubernetes 面前是惨败,然后 Docker 公司就把 containerd 项目捐献给了 CNCF 基金会,这个也是现在的 Docker 架构。
什么是CRI
我们知道 Kubernetes 提供了一个 CRI 的容器运行时接口,那么这个 CRI 到底是什么呢?这个其实也和 Docker 的发展密切相关的。
在 Kubernetes 早期的时候,当时 Docker 实在是太火了,Kubernetes 当然会先选择支持 Docker,而且是通过硬编码的方式直接调用 Docker API,后面随着 Docker 的不断发展以及 Google 的主导,出现了更多容器运行时,Kubernetes 为了支持更多更精简的容器运行时,Google 就和红帽主导推出了 CRI 标准,用于将 Kubernetes 平台和特定的容器运行时(当然主要是为了干掉 Docker)解耦。
CRI
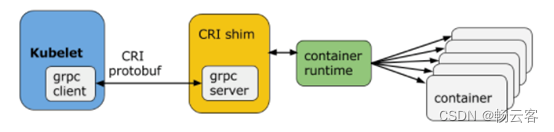
CRI(Container Runtime Interface 容器运行时接口)本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口,所以只要实现了这套接口的容器运行时都可以对接到 Kubernetes 平台上来。不过 Kubernetes 推出 CRI 这套标准的时候还没有现在的统治地位,所以有一些容器运行时可能不会自身就去实现 CRI 接口,于是就有了 shim(垫片), 一个 shim 的职责就是作为适配器将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上,其中 dockershim 就是 Kubernetes 对接 Docker 到 CRI 接口上的一个垫片实现。
CRI shim
Kubelet 通过 gRPC 框架与容器运行时或 shim 进行通信,其中 kubelet 作为客户端,CRI shim(也可能是容器运行时本身)作为服务器。
CRI定义的API 主要包括两个 gRPC 服务,ImageService 和 RuntimeService,ImageService 服务主要是拉取镜像、查看和删除镜像等操作,RuntimeService 则是用来管理 Pod 和容器的生命周期,以及与容器交互的调用(exec/attach/port-forward)等操作,可以通过 kubelet 中的标志 --container-runtime-endpoint 和 --image-service-endpoint 来配置这两个服务的套接字。
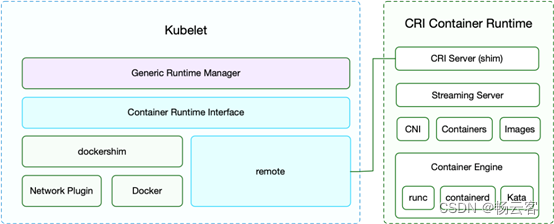
不过这里同样也有一个例外,那就是 Docker,由于 Docker 当时的江湖地位很高,Kubernetes 是直接内置了 dockershim 在 kubelet 中的,所以如果你使用的是 Docker 这种容器运行时的话是不需要单独去安装配置适配器之类的,当然这个举动似乎也麻痹了 Docker 公司。
切换到Containerd
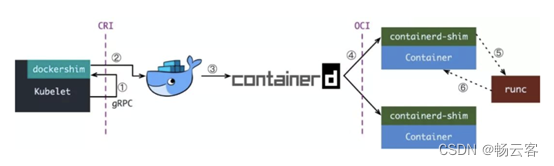
现在如果我们使用的是 Docker 的话,当我们在 Kubernetes 中创建一个 Pod 的时候,首先就是 kubelet 通过 CRI 接口调用 dockershim,请求创建一个容器,kubelet 可以视作一个简单的 CRI Client, 而 dockershim 就是接收请求的 Server,不过他们都是在 kubelet 内置的。
dockershim 收到请求后, 转化成 Docker Daemon 能识别的请求, 发到 Docker Daemon 上请求创建一个容器,请求到了 Docker Daemon 后续就是 Docker 创建容器的流程了,去调用 containerd,然后创建 containerd-shim 进程,通过该进程去调用 runc 去真正创建容器。
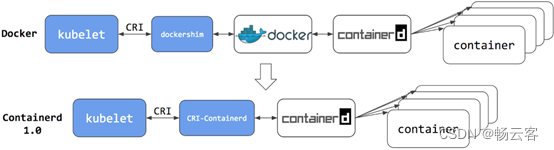
其实我们仔细观察也不难发现使用 Docker 的话其实是调用链比较长的,真正容器相关的操作其实 containerd 就完全足够了,Docker 太过于复杂笨重了,当然 Docker 深受欢迎的很大一个原因就是提供了很多对用户操作比较友好的功能,但是对于 Kubernetes 来说压根不需要这些功能,因为都是通过接口去操作容器的,所以自然也就可以将容器运行时切换到 containerd 来。
切换到 containerd 可以消除掉中间环节,操作体验也和以前一样,但是由于直接用容器运行时调度容器,所以它们对 Docker 来说是不可见的。因此,你以前用来检查这些容器的 Docker 工具就不能使用了。
你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。由于不能列出容器,因此也不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
与此同时 Kubernetes 社区也做了一个专门用于 Kubernetes 的 CRI 运行时 CRI-O,直接兼容 CRI 和 OCI 规范。

但是随着 CRI 方案的发展,以及其他容器运行时对 CRI 的支持越来越完善,Kubernetes 社区在2020年7月份就开始着手移除 dockershim 方案了:https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2221-remove-dockershim,现在的移除计划是在 1.20 版本中将 kubelet 中内置的 dockershim 代码分离,将内置的 dockershim 标记为维护模式,当然这个时候仍然还可以使用 dockershim,目标是在 1.23/1.24 版本发布没有 dockershim 的版本(代码还在,但是要默认支持开箱即用的 docker 需要自己构建 kubelet,会在某个宽限期过后从 kubelet 中删除内置的 dockershim 代码)。
那么这是否就意味着 Kubernetes 不再支持 Docker 了呢?当然不是的,这只是废弃了内置的 dockershim 功能而已,Docker 和其他容器运行时将一视同仁,不会单独对待内置支持,如果我们还想直接使用 Docker 这种容器运行时应该怎么办呢?可以将 dockershim 的功能单独提取出来独立维护一个 cri-dockerd 即可,就类似于 containerd 1.0 版本中提供的 CRI-Containerd,当然还有一种办法就是 Docker 官方社区将 CRI 接口内置到 Dockerd 中去实现。
但是我们也清楚 Dockerd 也是去直接调用的 Containerd,而 containerd 1.1 版本后就内置实现了 CRI,所以 Docker 也没必要再去单独实现 CRI 了,当 Kubernetes 不再内置支持开箱即用的 Docker 的以后,最好的方式当然也就是直接使用 Containerd 这种容器运行时,而且该容器运行时也已经经过了生产环境实践的。
Containerd主要任务
我们知道很早之前的 Docker Engine 中就有了 containerd,只不过现在是将 containerd 从 Docker Engine 里分离出来,作为一个独立的开源项目,目标是提供一个更加开放、稳定的容器运行基础设施。分离出来的 containerd 将具有更多的功能,涵盖整个容器运行时管理的所有需求,提供更强大的支持。
Containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,containerd 可以负责干下面这些事情:
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 runc 运行容器(与 runc 等容器运行时交互)
- 管理容器网络接口及网络
部署Kubernetes集群
资源列表
| 操作系统 | 主机名 | 配置 | IP |
| CentOS7.9.2009 | master | 2C4G | 192.168.207.131 |
| CentOS7.9.2009 | node1 | 2C4G | 192.168.207.165 |
| CentOS7.9.2009 | node2 | 2C4G | 192.168.207.166 |
基础环境
所有节点都要操作
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
关闭selinux
setenforce 0
sed -i "s/.*SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
关闭swap分区
swapoff -a # 临时关闭
sed -i 's/.*swap.*/#&/g' /etc/fstab
添加hosts解析
cat >> /etc/hosts << EOF
192.168.207.131 master
192.168.207.165 node1
192.168.207.166 node2
EOF
桥接的IPv4流量传递到iptables的链
modprobe overlay
modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
sysctl --system
准备Containerd
所有节点都要操作
安装Containerd
# 添加docker源,containerd也是在docker源内的
cat <<EOF | sudo tee /etc/yum.repos.d/docker-ce.repo
[docker]
name=docker-ce
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/x86_64/stable/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
# 安装containerd
yum list containerd.io --showduplicates
yum -y install containerd.io-1.6.6-3.1.el7.x86_64
配置Containerd
# 生成配置文件
mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
# 修改/etc/containerd/config.toml文件中sandbox_image的值
[root@master ~]# grep 'sandbox_image' /etc/containerd/config.toml
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
启动Containerd
systemctl enable containerd
systemctl start containerd
部署Kubernetes集群
安装kubeadm工具
# 所有节点都要操作
cat << EOF >> /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.27.0 kubeadm-1.27.0 kubectl-1.27.0
systemctl enable --now kubelet
配置crictl工具
crictl 是 CRI 兼容的容器运行时命令行接口。 你可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序。 crictl 和它的源代码在 cri-tools 代码库。
更换 Containerd 后,以往我们常用的 docker 命令也不再使用,取而代之的分别是 crictl 和 ctr 两个命令客户端。
crictl 是遵循 CRI 接口规范的一个命令行工具,通常用它来检查和管理kubelet节点上的容器运行时和镜像。
ctr 是 containerd 的一个客户端工具。
# 所有节点都要操作
cat << EOF >> /etc/crictl.yaml
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 测试crictl工具能否使用
crictl pull nginx:latest
ctr -v 输出的是 containerd 的版本,crictl -v 输出的是当前 k8s 的版本,从结果显而易见你可以认为 crictl 是用于 k8s 的。
[root@master ~]# ctr -v
ctr containerd.io 1.6.6
[root@master ~]# crictl -v
crictl version v1.26.0
初始化Master
# master节点操作
# 生成配置文件
kubeadm config print init-defaults > kubeadm-init.yaml
# 修改kubeadm-init.yaml文件的advertiseAddress,imageRepository,kubernetesVersion,添加podSubnet
[root@master ~]# cat kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.207.131
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: node
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.27.0
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
# 初始化集群
kubeadm init --config=kubeadm-init.yaml
# 初始化成功以后要根据提示执行以下3条命令,才可以操作集群
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
Node节点加入集群
所有Node节点执行
# 在master节点初始化的时候返回信息中最后的命令就是node节点加入集群的命令,将该命令复制到node节点执行即可
[root@node1 ~]# kubeadm join 192.168.207.131:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:7c0d3e0022922a39a94c8acb1db8cb6d3540c5c04ccb3a0a7b362628f0066b81
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
如果加入集群的命令找不到了可以在master节点生成一个
[root@master ~]# kubeadm token create --print-join-command
kubeadm join 192.168.207.131:6443 --token wf2wz6.9f55svearl4em1lp --discovery-token-ca-cert-hash sha256:1f8552dcd75ab054866a82b9218b9b20952758da76c28c00eba6c2811ed19074
部署网络插件(CNI)
Master节点操作
[root@master ~]# kubectl apply -f kube-flannel.yaml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
验证
查看节点状态
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 14m v1.27.0
node1 Ready <none> 4m50s v1.27.0
node2 Ready <none> 4m41s v1.27.0
查看集群组件状态
[root@master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









