






keystone
#登录信息提交给Credentials之后,Credentials会生成一个临时令牌token,后面的操作校验token是否合法即可
#Project 将 资源(计算、存储和网络)进行分组和隔离,user需要使用哪个就挂载那个project,可以挂载多个
#User通过Endpoint终端点(也就是service的API,通常是一个url)访问service资源以及执行操作,每个service会暴露出自己的API供user使用
#service通过编辑policy.json文件,规定role控制访问,然后通过给user分配role,以达到不同的user分权限使用service
Glance
#Glance 1.根据虚拟机使用快照创建新的image 2.多方式存储image(实际由后台存储) 3.提供user获取image的数据及image本身的接口
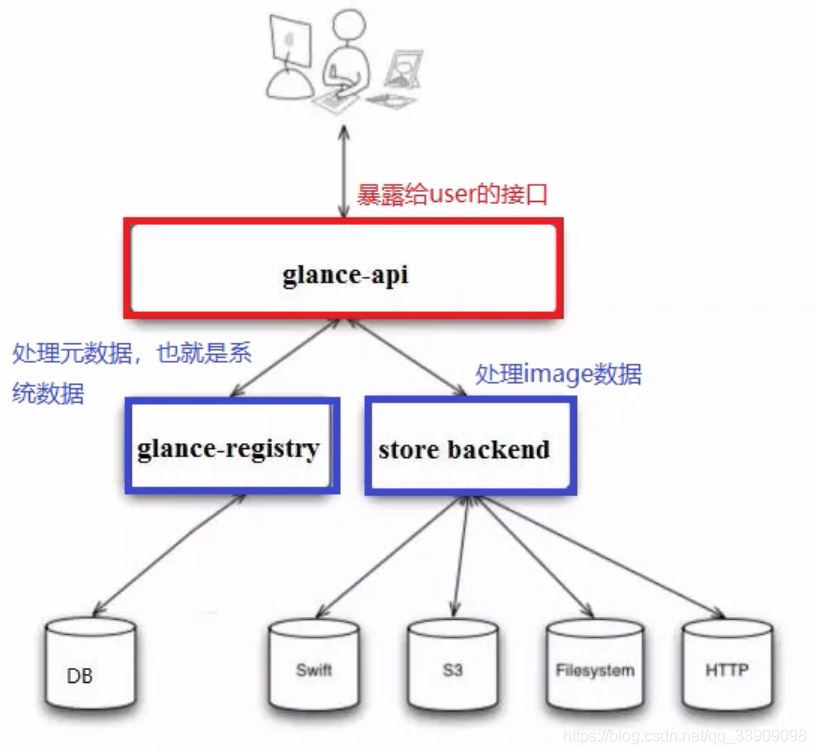
Nova
#Hypervisor泛指所有底层具体节点上的虚拟机管理程序,各家不一,KVM只是其中一种。nova是通过定制统一的接口做到支持多种Hypervisor的,不同的Hypervisor只要实现了这个接口就可以以driver的形式插入openstack进行使用
#控制节点同时也可以作为计算节点,因为都运行得有nova-compute,可以运行虚拟机
#nova的各模块工作机制(这张图是nova的灵魂之光,所有的nova操作都会有这几步)
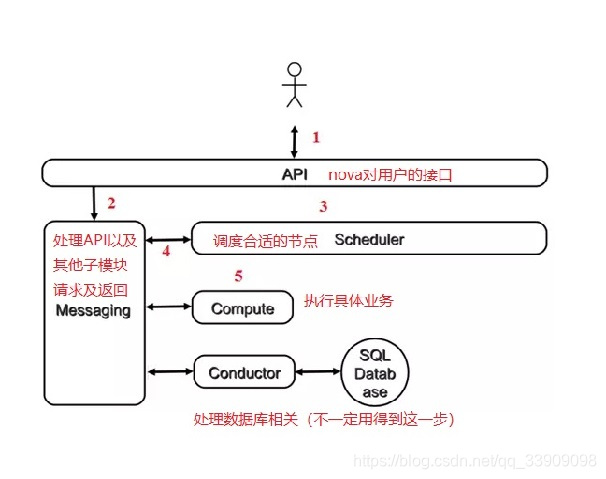
#nova-api是Nova对外的唯一接口,不管是其他组件还是用户或者其他任何需要使用Nova的东西,对Nova的所有请求统统发给nova-api处理,所以对于外部组件,Nova内部是黑盒,发生变化也不影响使用,高度解耦便于迁移和广泛适配这种模块化做法将Nova负责的任务单独切出去了,意味着可以同时创建多个Nova实例各跑各的
#采用消息队列Messaging中转请求和返回数据,是为了便于异步调用,比如业务逻辑是A服务发送请求给B处理,B返回结果给A,这期间A需要等待B完成,添加消息队列M中转以后,A发送请求给M即刻返回,M转发请求给B,A无需等待。B处理完成返回给M,由M转交给A。
#增加nova-conductor中间件代理,解耦计算节点与控制节点数据库之间的操作,避免在庞杂的计算节点上配置数据库连接更安全,同时因为nova-conductor是无状态服务(对单次请求的处理不依赖其他请求的数据或者结果),所以可以横向增加nova-conductor减轻数据库访问压力
nova子模块
nova-sheduler
#nova-sheduler的调度机制事实上就是多重筛选,最后选择剩余节点里权值最高的一个
筛选规则由scheduler_default_filters指定,选择筛选规则列表

OpenStack默认实现是根据计算节点空闲的内存量计算权重值,也就是说最后选择的节点是符合筛选规则里的空闲内存最高的节点
#nova-sheduler的调度机制依赖于各种筛选,需要根据指定的筛选规则,获得每个计算节点各式各样的信息。这些信息都是源于Hypervisor的支持,因为Hypervisor直接面向节点底层的虚拟管理程序,可以获得节点的资源使用情况,通过driver上报给nova-sheduler使用。
nova-conpute
#nova-conpute创建虚拟机流程

//从Glance下载的image是不变的,只作为back file用来创建虚拟机镜像,后期在虚拟机上安装配置的任何东西都只改变该虚拟机的镜像,所以从Glance下载的这个image是可以供该节点的其他虚拟机复用的
关于日志
#查看日志需要了解该操作的内部流程,比如Instace启动它的步骤,首先启动需要用户(可能是人可能是其他任何需要启动虚拟机的模块)发出请求给nova-api,第二步nova-api将请求转发给消息队列Messaging由Messaging转发给执行的计算节点,第三步收到请求的计算节点执行启动。
所以启动的日志生产位置前两步会在控制节点,最后一步会在计算节点,画个图方便看
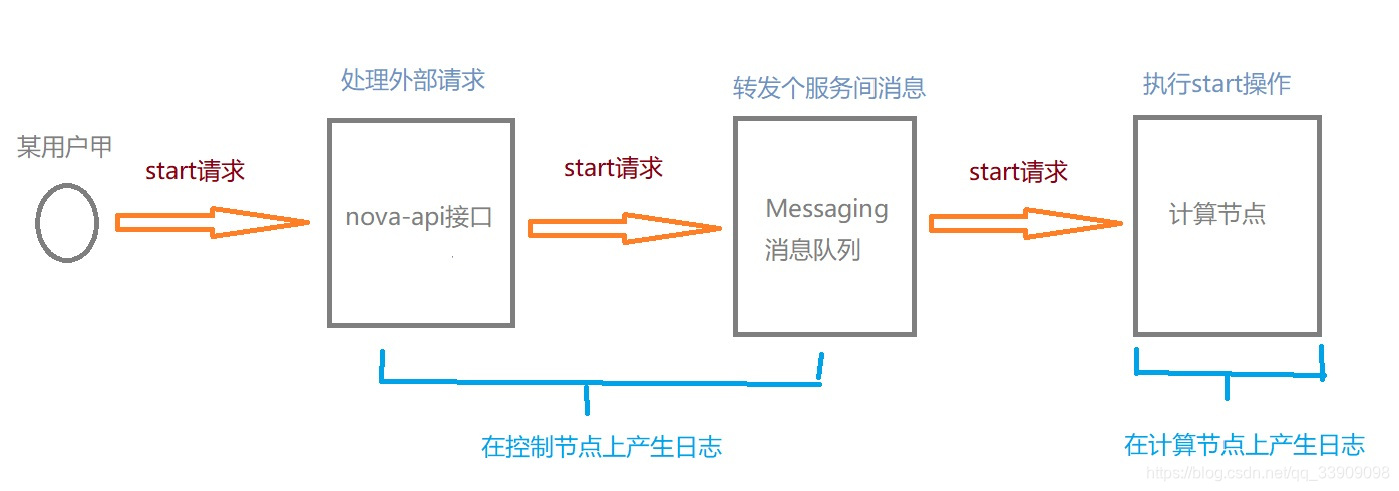
其他操作以此类推,分析该操作步骤流程,确定日志产出地点,然后较复杂的操作就拆分流程去找日志,比如删除虚拟机:
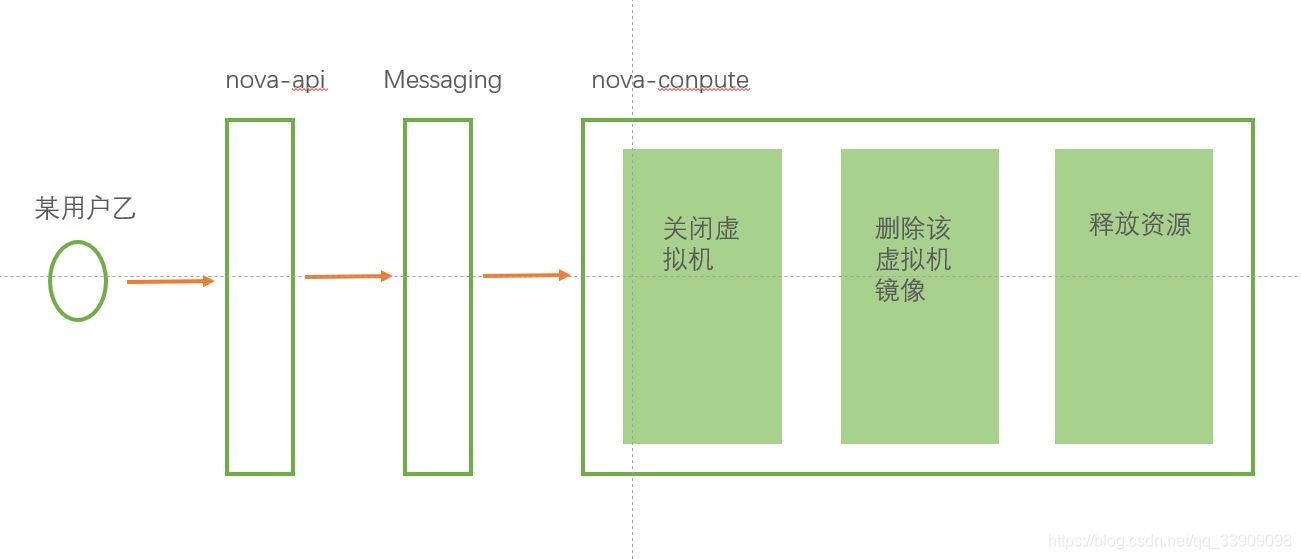
ps:因为基于nova的所有操作均有,用户请求--->nova-api ---->Messaging ------>nova-conpute这几步,后文画图一律省略这几步固定流程,只画nova-conpute内部执行原理
Lock
#对于涉及到改变虚拟机状态的操作,可以通过Lock锁机制进行限制(对admin用户等级高于锁不受限)
Rescue与Rebuild Instance与Unshelve
#Rescue操作实际上是,根据该计算节点通用的那个image新建一个虚拟机A,然后把出现问题的虚拟机B的根磁盘作为附加磁盘挂载到A上,这样虚拟机A就会重用虚拟机B的所有信息,相当于对虚拟机B抢救成功
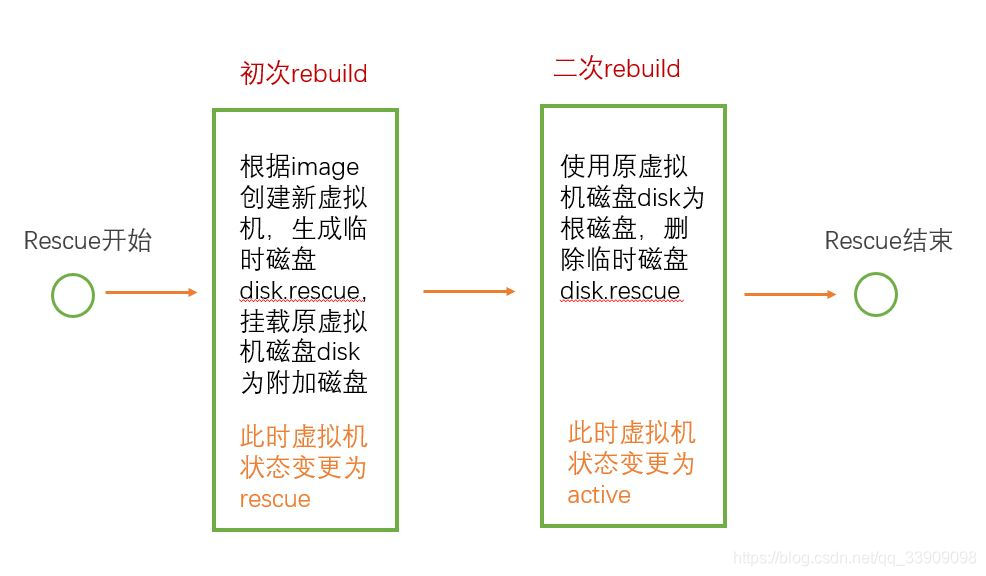
#Rebuild Instance通过snapshot快照快速恢复虚拟机,本质是新建虚拟机然后使用快照作为镜像。操作系统损坏得很严重,通过 Rescue 操作无法修复,就考虑Rebuild Instance通过备份恢复
在虚拟机配置完成时就应该备份快照,做出重大更改时也应该备份快照,所有的快照都存储在Glance上, rebuild instance从Glance上获取对应的版本,即可进行恢复

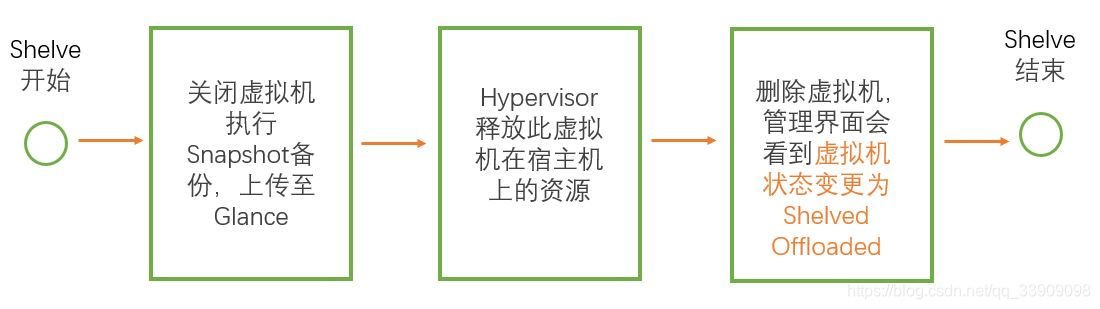
#Shelve的本质是将 instance 作为 image 保存到 Glance 中,然后在宿主机上删除该 instance释放资源,但是该虚拟机仍然可以通过Unshelve instance操作恢复,Unshelve instance的本质是创建新虚拟机通过Shelve时上传的image进行恢复(创建虚拟机以及如何通过image恢复参见上文nova-conpute创建虚拟机流程以及 rebuild instance恢复的镜像恢复部分)
故障恢复对比
#然后我们横向对比一下Rescue与Rebuild Instance与Unshelve三种故障恢复
Rescue通过磁盘引导恢复,不需要从Glance重新下载镜像,最简单。但是如果损坏比较严重可能无法恢复成功。
Rebuild Instance是通过远程获取此虚拟机之前上传到Glance的镜像进行恢复。
Unshelve与Rebuild Instance类似都是依赖快照镜像恢复,但是Unshelve是针对Shelve这种,宿主机已经把原虚拟机资源释放掉的情况,需要重新通过nova-sheduler调度节点,分配资源创建网络。Rescue和Rebuild Instance不需要
所以结论就是发生重大更改时一定要做快照,不然一旦出现严重故障就救不回来了(关于快照冗余问题,后面我再找找看大佬们是怎么办的)
pause与Suspend与Shelve
#pause和Suspend都是暂停,可以通过Resume恢复
但是Suspend 将 instance 的状态保存在磁盘,Pause 是保存在内存中
执行后pause虚拟机状态为paused,执行Suspend后虚拟机状态为Shut Down,所以唤醒时同样是执行Resume,对于paused状态的虚拟机相当于真正的Resume,对于与paused状态的虚拟机仅相当于unpause
Shelve则是删除,上传完备份快照之后,直接释放该虚拟机在宿主机上的所有资源,非常狠不可唤醒,只能通过Unshelve恢复
Migrate
#如果计算节点出现故障,针对虚拟机的恢复方式将不能起效。于是就需要采用Migrate将虚拟机从当前的故障计算节点迁移到其他节点上。
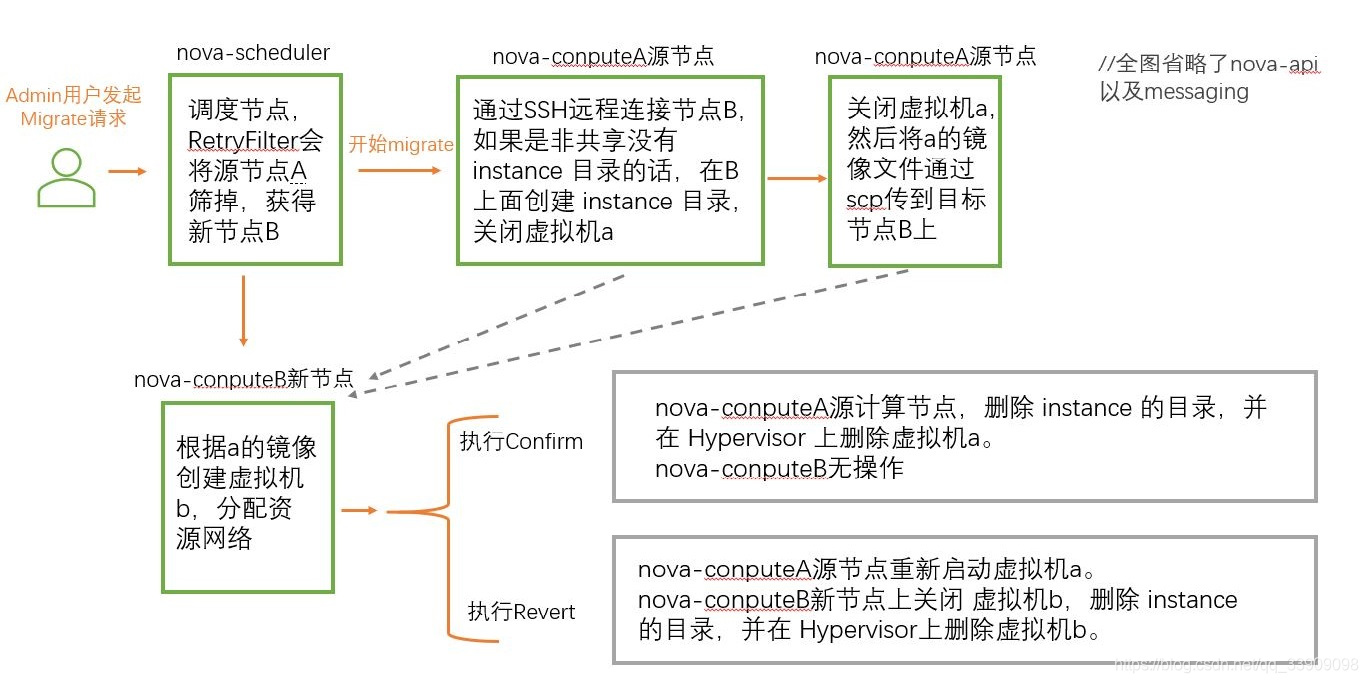
Migrate 使用有个必要条件:计算节点间需要配置 nova 用户无密码访问(不然后台服务会等待密码确认操作合法,但是由于是由nova-conputeA源节点调动的SSH连接和SCP传输,nova-conputeA自然是不能像人一样给输入密码的)
Resize
Resize的本质是重新根据新flavor分配资源的Migrate。也就是说Migrate在nova-scheduler筛选合适的新节点B时,是根据源节点A去选择新节点B的资源规格,而Resize则是在Migrate的基础上选节点的时候按照新flavor去选的,和源节点A的资源配置(计算,内存和存储容量)不一样。
Live Migrate
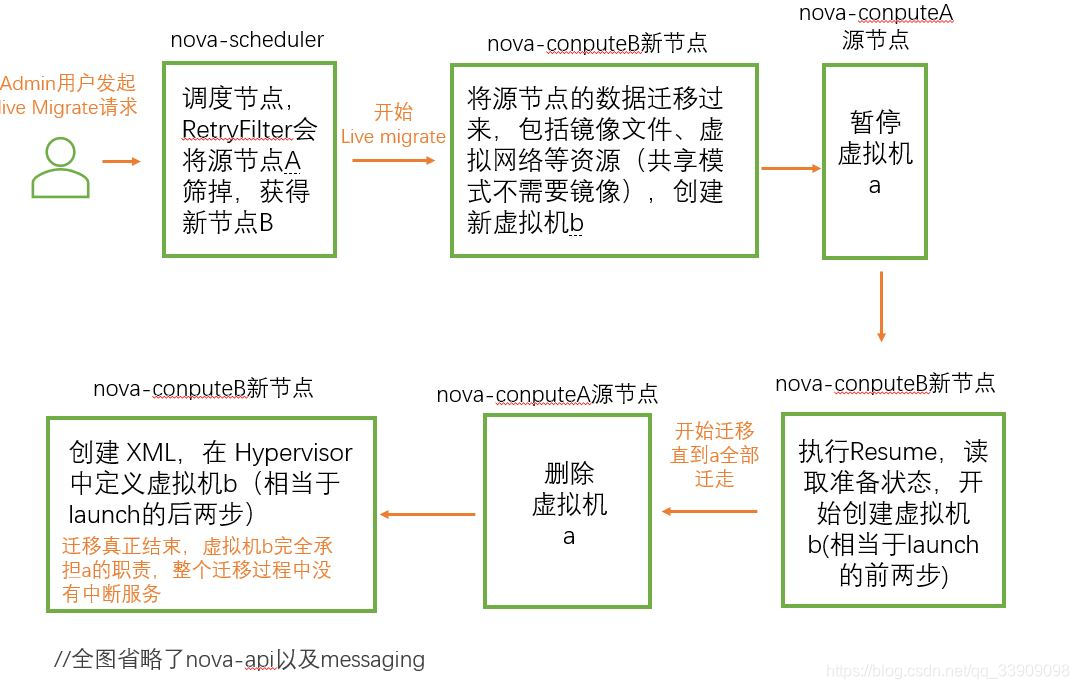
Live Migrate热迁移比起Migrate冷迁移的好处是不用关闭迁移的虚拟机,但这需要一些条件:
源节点和新节点要求:CPU 类型一致,Libvirt 版本一致,能相互识别对方的主机名称,都在各自配置文件 /etc/nova/nova.conf 中指明在线迁移时使用 TCP 协议, 打开Libvirt TCP 远程监听服务,
除此之外新节点创建虚机的时候还需要创建 vfat 类型的 config driver(因为目前 libvirt 只支持迁移 vfat 类型的 config driver,热迁移的时候是连 config driver一起迁移的)
条件齐备,接下来是Live Migrate的迁移内部流程,Live Migrate分为两种类型:
1.源和目标节点没有共享存储,迁移时需将源节点镜像文件传到新节点,称为 Block Migration(块迁移)
2.源和新节点共享存储,不用传镜像文件(因为存储共享源节点的镜像新节点也可以直接拿到)
Evacuate
#当计算节点的故障已经连源节点nova-compute都无法工作的情况,即使Migrate也无法恢复,就只能靠Evacuate了, Evacuate的本质是通过共享存储上源节点的镜像将虚拟机迁移到其他计算节点上
所以首先,源节点必须得在共享存储上有镜像才行!没有就算了,故障到这种程度并且还没有镜像,没救了(手动狗头,也许还有但是反正我不知道了)
迁移恢复机制类同于Rebuild Instance通过镜像恢复。只是迁移之前需要通过nova-scheduler选节点,重建一个虚拟机。
小节一下
#总的来说,nova负责维护和管理云环境的计算资源管理虚拟机生命周期。
管虚拟机从生到死,以及什么时候生什么时候死,生的时候有多少资源可以用,以及生病了出现故障该怎么抢救。还有抢救的5种方案。是时候放出大佬这张经典的图了
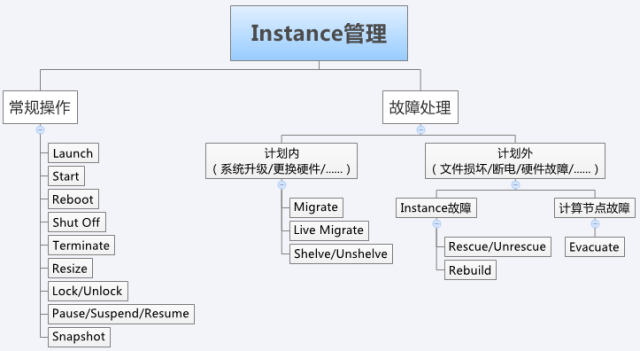
选节点分资源用nova-scheduler,创建用Launch,节点上虚拟机故障上Rescue与Rebuild Instance与Unshelve,节点故障上Migrate,节点故障到都跑不起来上Evacuate。最后,一定要记得备份镜像,不然容易抢救失败挂掉。

















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









