







在 PyTorch 中,叶子张量(Leaf Tensor)和非叶子张量(Non-Leaf Tensor)是计算图中的两个重要概念:
叶子张量(Leaf Tensor)
叶子张量是计算图中的起始点,它们通常是用户直接创建的张量,并且没有其他张量作为它们的输入。换句话说,叶子张量是那些不需要通过任何计算就能获得的张量。在神经网络中,叶子张量通常对应于模型的输入数据和模型的参数(权重和偏置)。
特征包括:
- 是计算图的起点。
- 通常对应于模型的参数或外部输入数据。
- 可以设置
requires_grad=True来追踪梯度,以便在训练过程中更新这些参数。
非叶子张量(Non-Leaf Tensor)
非叶子张量是计算图中通过某些操作从其他张量派生出来的张量。它们是计算图的中间节点,其值依赖于一个或多个其他张量的值。当你对叶子张量或其他非叶子张量执行操作(如加法、乘法等)时,就会创建非叶子张量。
特征包括:
- 是通过计算图中的操作生成的。
- 依赖于其他张量的值。
- 默认情况下,它们的
.grad属性在反向传播时不会被填充,除非你显式调用retain_grad()方法。
示例
import torch
# 创建叶子张量 x,它是一个直接由用户创建的张量
x = torch.randn(2, 2, requires_grad=True)
# 创建非叶子张量 y,它是通过操作 x 得到的
y = x * 2
# 创建另一个非叶子张量 z,它是通过操作 y 得到的
z = y + 3
在这个示例中:
x是叶子张量,因为它是直接创建的,并且没有依赖于其他张量。y和z是非叶子张量,因为它们是通过操作x和y得到的。
梯度计算
在反向传播时,PyTorch 会自动计算叶子张量的梯度,并将这些梯度存储在叶子张量的 .grad 属性中。对于非叶子张量,你需要显式调用 retain_grad() 方法,才能在反向传播时计算和存储它们的梯度。
# 反向传播计算梯度
z.backward()
# 打印 x, y, z 的梯度
print("Gradient of x:", x.grad) # 可以访问,因为 x 是叶子张量
print("Gradient of y:", y.grad) # 会报警告,因为 y 是非叶子张量,且没有调用 retain_grad()
print("Gradient of z:", z.grad) # 会报警告,因为 z 是非叶子张量,且没有调用 retain_grad()
为了能够访问 y 和 z 的梯度,你需要在创建它们之后调用 retain_grad() 方法:
y.retain_grad()
z.retain_grad()
# 反向传播计算梯度
z.backward()
# 打印 x, y, z 的梯度
print("Gradient of x:", x.grad) # 可以访问
print("Gradient of y:", y.grad) # 现在可以访问
print("Gradient of z:", z.grad) # 现在可以访问
贴个网图,
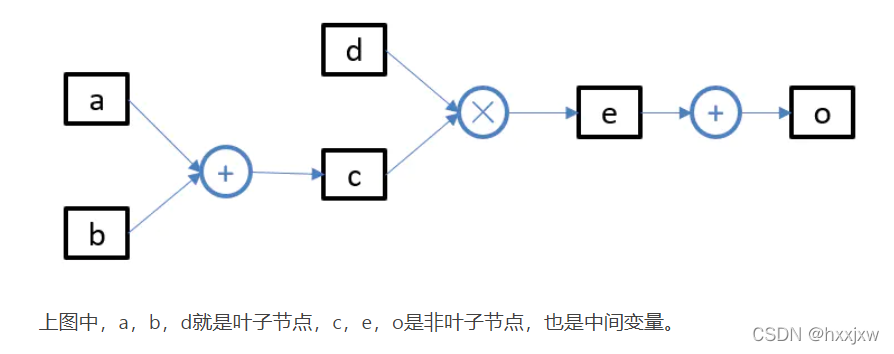


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









