






数据结构简答题题型

一.匹配字符串
1)计算串的next与nextval
计算next值方法
如表格类型
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| b | a | b | a | b |
| 0 | 1 |
方法1
求next值,常规方法1
利用串匹配常规法代即可
下标法类代
方法2:利用前缀匹配和后缀匹配相等值代
#(这里的前缀是不包括最后一个字符的子串,后缀是不包含第一个字符的子串)
如
第三位:字符串是"bab",前缀有b, ba;后缀有ab,b,前后缀相等的最长字符串为b,长度为1,所以第三位Next值为1
第四位:字符串"baba",前缀有b, ba, bab;后缀有aba, ba, a,前后缀相等的最长字符串为ba,长度为2,所以第三位Next值为2–>如果值只为一个,即值直接加1
如果最后得到的串大于等于2
就代相互取值加一的方法代
##例如得到ba,是把ba变成-1,b(前面加上-1,结尾那个去掉)。第二步:把-1,b的值全部加上1,得到0,b+1就是最终的值-->
即代出值为2
2)计算nextval值
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| 例子 | a | b | a | a | b | c | a | c |
| next | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
| nextval | 0 | 1 | 0 | 2 | 1 | 3 | 0 | 2 |
总结下规律:第一位的nextval值肯定为0,第二位,观察第一位,相同为0,不同为1。剩下的求nextval:
若当前值即例子中的值与当前next所对应的值不同,则直接为当前next值;若相同,则继续查找对应的next值,有不同的就把对应的next值给nextval(正如上面的第五位查找),否则为0。
如步骤分析
第一位-->直接赋值为0完事
第二位-->b与第一位的a不同-->直接为1
第三位-->next的值为1相同,继续查找,查找到同为a的情况,即发现第一位,next为0,不同-->即第三位的next值为0
代码原理
#include<bits/stdc++.h>
using namespace std;
#define maxn 255
typedef struct
{
char ch[maxn+1];
} SString;
void Init(SString &S)
{
char str[maxn];
cin>>str;
S.ch[0] = strlen(str);//用第一个位置,存数组的长度
for(int i=0;str[i];i++)
S.ch[i+1] = str[i];
}
void get_nextval(SString &S1,int nextval[])
{
int i=1,j=0;
nextval[1] = 0;
while(i<S1.ch[0])
{
if(j==0||S1.ch[i]==S1.ch[j])
{
i++;
j++;
if(S1.ch[i]!=S1.ch[j])nextval[i] = j;
else
nextval[i] = nextval[j];
}
else
j = nextval[j];
}
for(int k=1; k<=S1.ch[0]; k++)
cout<<nextval[k]<<' ';
}
void get_next(SString &T,int next[])
{
int i=1,j=0;
next[1] =0;
while(i<T.ch[0])
{
if(j==0||(T.ch[i]==T.ch[j]))
{
++i;++j;
next[i]=j;
}
else
j = next[j];
}
for(int k=1;k<=T.ch[0];k++)
cout<<next[k]<<' ';
}
int main()
{
SString S1;
Init(S1);
int next[maxn];
///Get_next(S1,next);
get_next(S1,next);
cout<<endl;
get_nextval(S1,next);
}
3.)写出KMP算法匹配的全过程
如即匹配到不一样的,即把这个内容作为新的起点,然后在代排序即可

二.矩阵考法
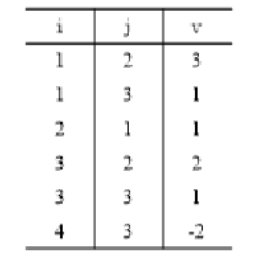
1.)稀疏矩阵与三元组表互换
即代有值的进行i,j,v关系代即可
现有一个稀疏矩阵,请给出它的三元组表。

三元组表即i代表行,j代表列,v代表的是值–>即利用行列对应的相互值代即可
代表即可
2.)图的邻接矩阵<–>有向表,邻接表,深搜广搜转换类
①直接给图进行代深搜和广搜
深度搜索–>利用邻接代+存储顺序代排序出
广度搜索–>利用按照层次遍历出–>思考下面的为何不可的原因
四种典型图排列方法
②给邻接矩阵代深搜和广搜
1.邻接矩阵转图
#有向图和娃娃向图判断方法
看行的度是否相同,同-->即无向
不同-->即有向
#最小生成树-->连通但不构成环
如

用prim算求最小生成树方法
克鲁斯卡尔算法
用邻接矩阵画图
第三步结果–>即代三个点连接的含义
即典型的代指点代即可(即左代右即可)
三.树和森林类
1.)知先序后序求二叉树
树的四种遍历
#j即三个遍历依次往右移动代即可
先序-->遍历顺序规则为【根左右】
中序遍历-->遍历顺序规则-->【左根右】
后序-->【左右根】
层次遍历-->【即按照层次代遍历即可】
如
已知二叉树的先序遍历序列为ABCDEFGH,中序遍历序列为CBEDFAGH,画出二叉树
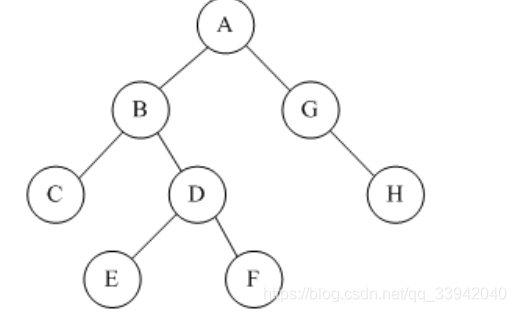
分析技巧–>利用分堆块进行代
即定根,分堆即可
后序直接按照上代即可
2)知序列顺序求森林
3)知电文编码,求哈夫曼树和WPL以及字符编码
参考教程
WPL:即最外围值乘以层次数即可
二叉树构建法:即代比较值,离散的方法代即可代出
例子
如
假设用于通讯的电文仅由8个字母A、B、C、D、E、F、G、H组成,字母在电文中出现的频率分别为:0.07,0.19,0.02,0.06,0.32,0.03,0.21,0.10。请为这8个字母设计哈夫曼编码。
#解法思路
即代编码数关系进行代数量值,然后代排序即可完成哈弗曼树构成
编码-->即利用层的状况代即可代出编码状况如
A-->之前是三个层,且都在左层,所以为0
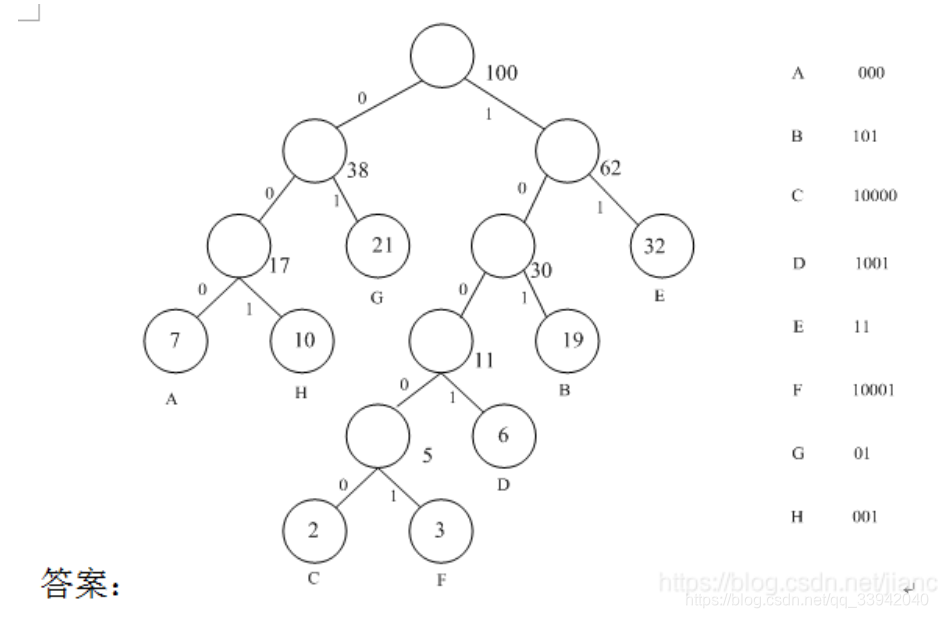
哈弗曼画法–>小在前,大在后。后加后排。
4.)图的拓扑排序
如题目

解法
#思路
BFS-->即按照表的相互关系推出即可
DFS
#①转边的关系
#②边出边减为零即压栈,然后在代出即可
四.知表或关键字画树或画散列表且求平均长度方法
1.)知表求平均查找长度类
①顺序查找法
②二分查找法
③二叉排序树
④散列表查找
①二分查找法
即一层的节点数层数相加除以总数类
②散列表查找法
如题
8、将关键字序列(7 , 8 , 30 , 11 , 18 , 9 , 14)散列存储到散列表中,散列表的存储空间是一个下标从0开始的一维数组,散列函数为H(key)=(key3)mod7 , 处理冲突采用线性探测再散列法,要求装载因子为0.7
(1)试画出所构造的散列表(4分)
(2)分别计算等概率情况下,查找成功和查找不成功的平均查找长度。
#总结①求散列表
#1.求装填因子
#2.装值,相同的移动到空值里面且进行填装(即处理异常-->线性探测法)
#②求成功的平均查找次数和不成功的平均查找次数方法
成功的算值的查找次数再除以关键字个数即可
不成功的算地址的平均查找次数,代除即可-->根据每个值距离后面为空的距离代算出
#注意二次探测方法类
2.)构造平衡二叉树
平衡二叉树的原理
#即四种类型代换即可
LL,RR,LR,RL
代换结构即可
代画出平衡二叉树方法
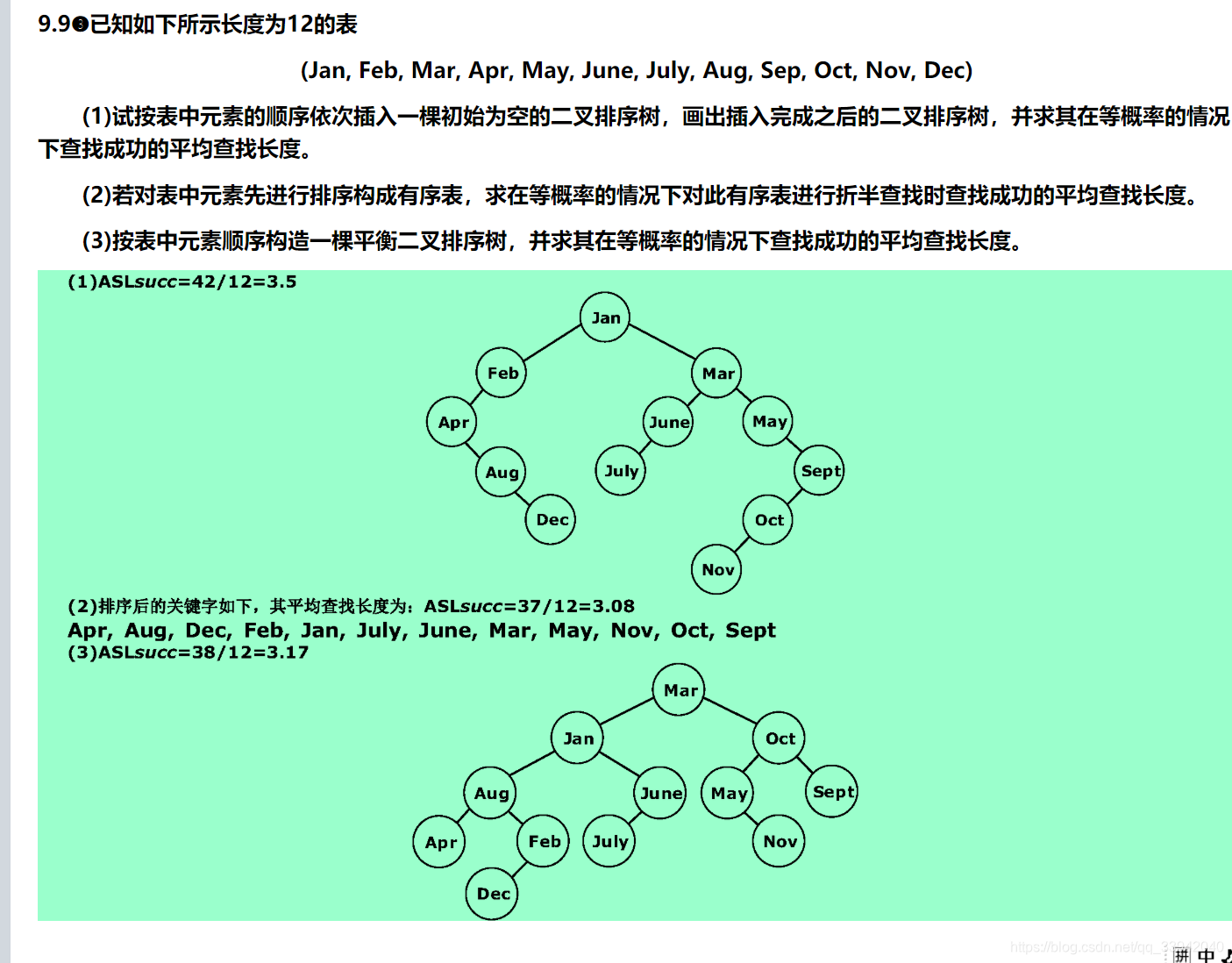
题集
严蔚敏数据结构习题
五,知数据序列排序
5种题型进行解
1.)希尔排序–>即对插入排序法改进代出的排序方法
#计算方法
#①计算步长h-->第一次arr.length/2,第二次上次的结果在除二,第三次依次往下带,直至为1
#②进行交换a[i-h]与a[h]的值
①右移代交互大的值,左移代交互小的值
②疯狂递归
如


即经过一次i,j交换后获得的值,即为一趟的结果
二.数据结构填空题题型
概念类
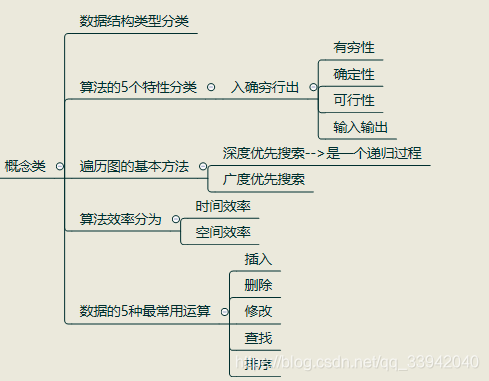
概念类
①数据结构类
1、简述下列术语:算法、数据结构、存储结构、数据类型、抽象数据类型(10分)
答:
算法: 是对特定问题求解步骤的一种描述,是指令的有限序列。
数据结构: 相互之间存在一定关系的数据元素之间的集合
存储结构: 数据的存储结构又称为物理结构,是数据及其逻辑结构在计算机中的表示。
数据类型: 一组值的集合以及定义与这个值集上的操作的总称。
抽象数据类型: 抽象数据类型(ADT)是一个数据结构以及定义在该结构上的一组操作的总称。
存储结构与逻辑结构分类
逻辑结构:集合结构,线性结构,树状结构,图或网状结构
存储结构:顺序存储结构与链式存储结构
②线性表的主要概念
一个或多个数据元素的有线序列
③栈队列的相关概念以及操作原则
队列
在一端进行插入操作,在另一端进行删除操作的线性表
栈
限定仅在一段进行插入和删除操作的线性表
④串的相关概念
0个或多个字符组成的有限序列,又名字符串
运算类
1.)非结构类运算(即非数据结构类运算)

题型①求程序段的时间复杂度
假设n为2的乘幂,并且 n > 2,试求下列算法的时间复杂度及变量 count 的值(以n的函数形式表示)并写出计算过程.
int Time(int n)
{int count = 0;int x = 2;
while(x < n/2)
{x *= 2;count ++;
}
return (count);
}
#计算结果即直接代出为-->O(logn)
5种类型的时间复杂度算法
题型②知二维数组下标与存储内容,求一个数组下标的地址是什么
如题
#已知二维数组A[m][n]采用行序为主方式存储,每个元素占k个存储单元,并且第一个元的存储地址是LOC(A[0][0]),则A[i][j]的地址是 Loc(A[0][0])+((i-0)*n+(j-0))*k
题型③二分法查找求查找需要多少次类
原理分析
如
有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,100},当二分查找值为82的结点时,经 4 次比较后查找成功
④分块查找
概念:1.二分法查找索引表,确定要找的记录在哪一块; 2.然后再在相应块用顺序查找找到目标记录。分块查找又称为索引顺序查找。(即两种查找叠合在一起的一种查找方式)
#求法
又称索引顺序查找,由分块有序(每一块中的关键字不一定有序,但是前一块中的最大关键字必须小于后一块中的最小关键字,即分块有序。)的索引表和线性表组成。例如把r【1....n】分为 b 块,则前 b-1 块节点数为 s = 【n/b】,最后一块允许小于或等于s。索引表是一个递增有序表。
平均查找长度分为两部分,索引表的查找+块内的查找。
如果以二分查找来确定块,则 ASL = log2(b+1)-1 + (s+1)/2。
如果以顺序查找来确定块,则 ASL = (b+1)/2 + (s+1)/2。
如果以哈希查找来确定块,则ASL=1 + (s+1)/2。
#典型例题
对于具有300个记录的文件,采用分块索引查找法查找,其中用二分查找法查找索引表,用顺序查找法查找块内元素,假定每块长度均为30个元素,则平均查找长度为 18.4
#在这里s-->每块的元素个数,b均等的几块.
#因为索引表采用二分法查找-->所以有log2(10+1)-1+(30+1)/2
#又因为块内查找为-->(b+1)/2=5.5
2.)结构类运算(即数据结构类运算)
①链表代算类
–>链表代删节点类
②队列类代运算
#已知循环队列的存储空间大小为20,且当前队列的头指针和尾指针的值分别为8和3,且该队列的当前的长度为16
#运算方法
20-8,3-0#因为数组的下标从0开始
代相加即可
③
若n为主串长,m为子串长,则串的古典(朴素)匹配算法最坏的情况下需要比较字符的总次数为()。
(n-m+1)*m
④已知子节点类求二叉树总的节点数方法
#如题目1-->若某二叉树有20个叶子结点,有30个结点仅有一个孩子,则该二叉树的总结点个数为69
#解-->利用公式总度和=节点个数-1
#分析过程
20个叶子节点即20个度为0的节点
30个只有一个孩子节点的节点即30个度为1的节点
本树属于二叉树,只存在度为0 1 2三种的节点
假设度为2的节点个数为x
公式总度和=节点个数-1
节点个数=50+x
总度和=30+2x
即 30+2x=50+x-1
解得:x=19
节点个数=50+19=69
题目2

解法
即利用性质即可
均有性质
no=n2+1
叶子节点=数/2
n2=叶子节点-1
偶数-->n1=1
奇数-->n1=0
⑤二叉树<–>森林<–>树
1.)树转换为二叉树
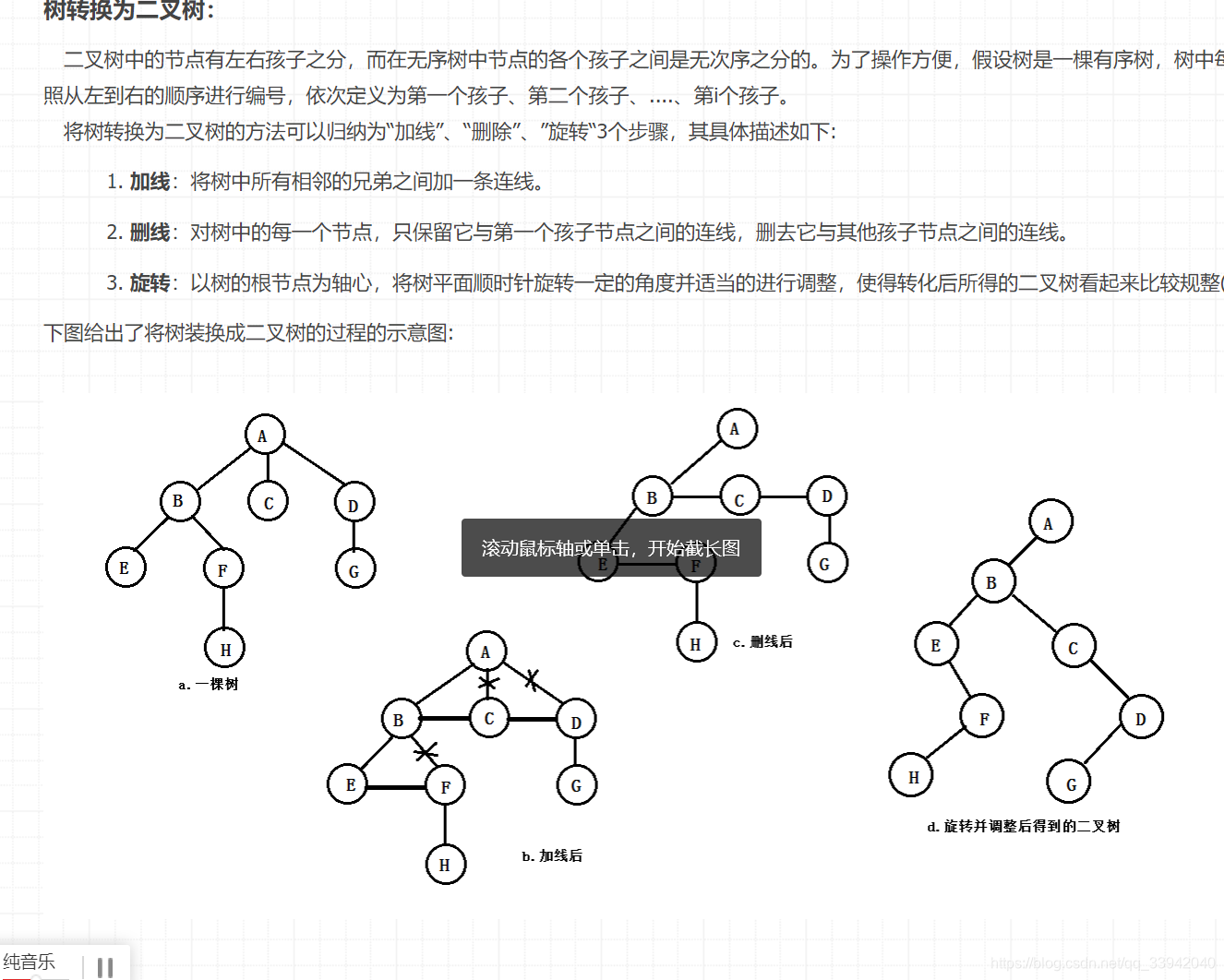
2.)二叉树转换为树
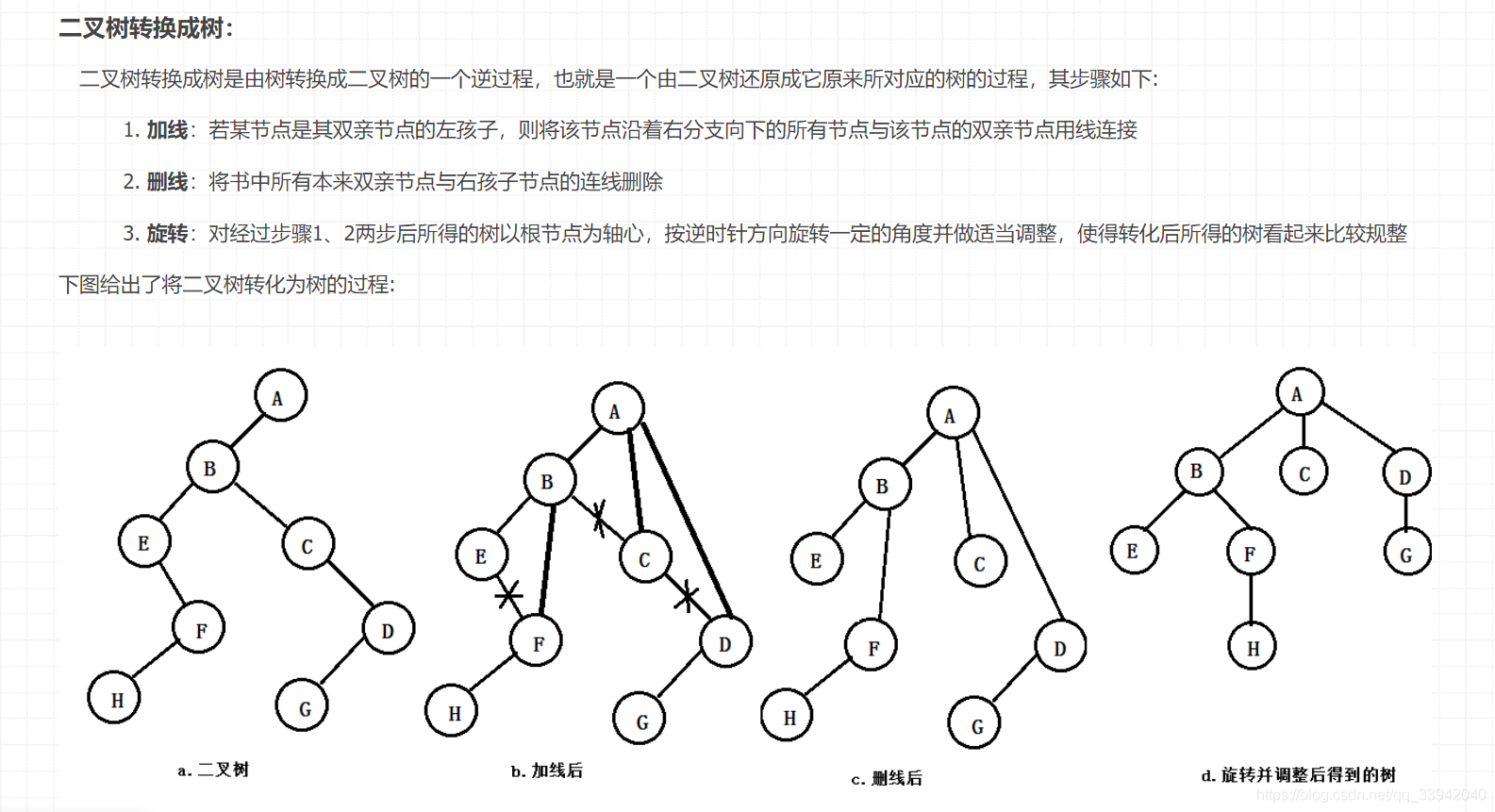
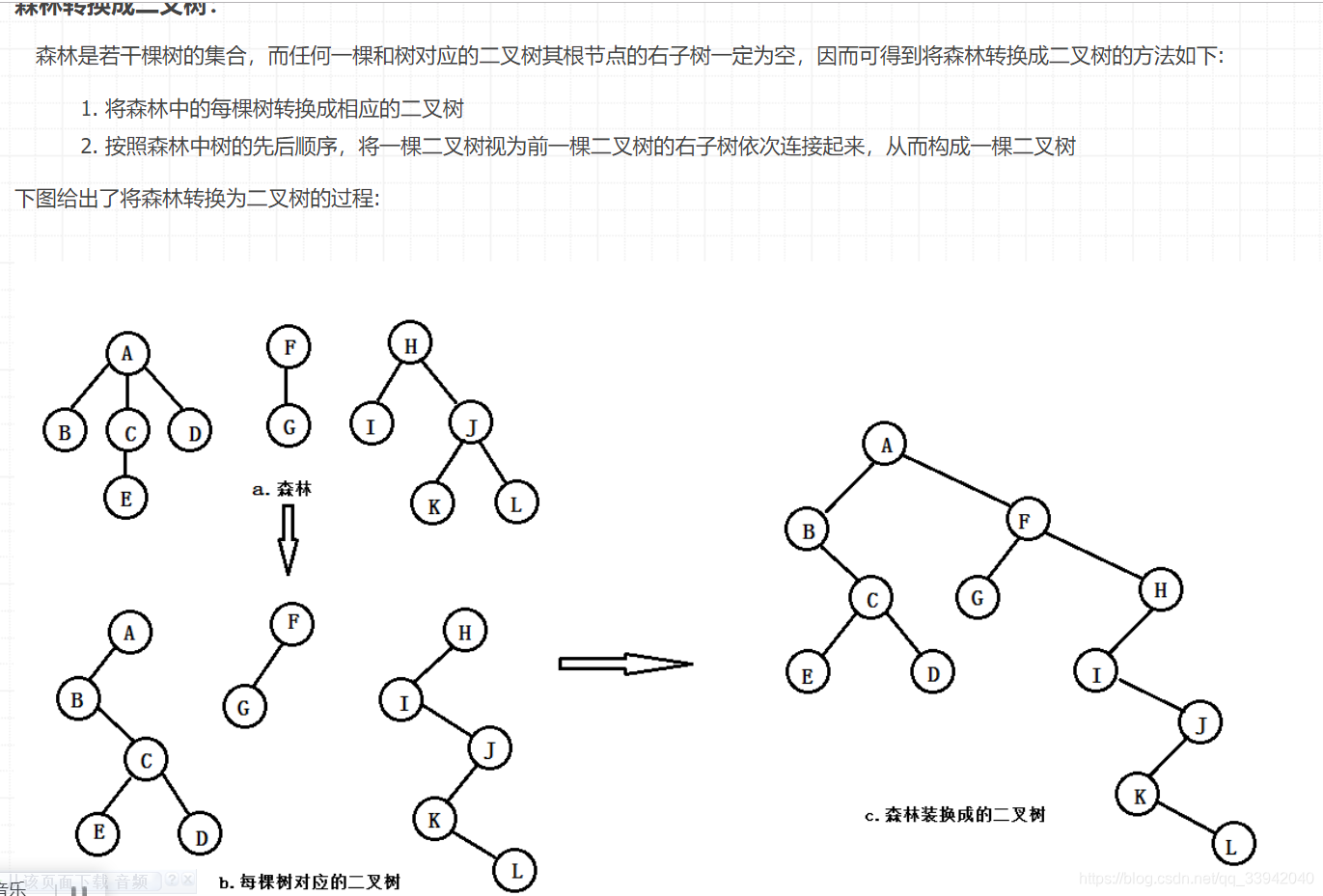
3.)森林转换为二叉树方法
即先将所有森林的树转为二叉树,在将树连接形成二叉树
4.)二叉树转森林(同理,先删线,然后在将二叉树全转为树)
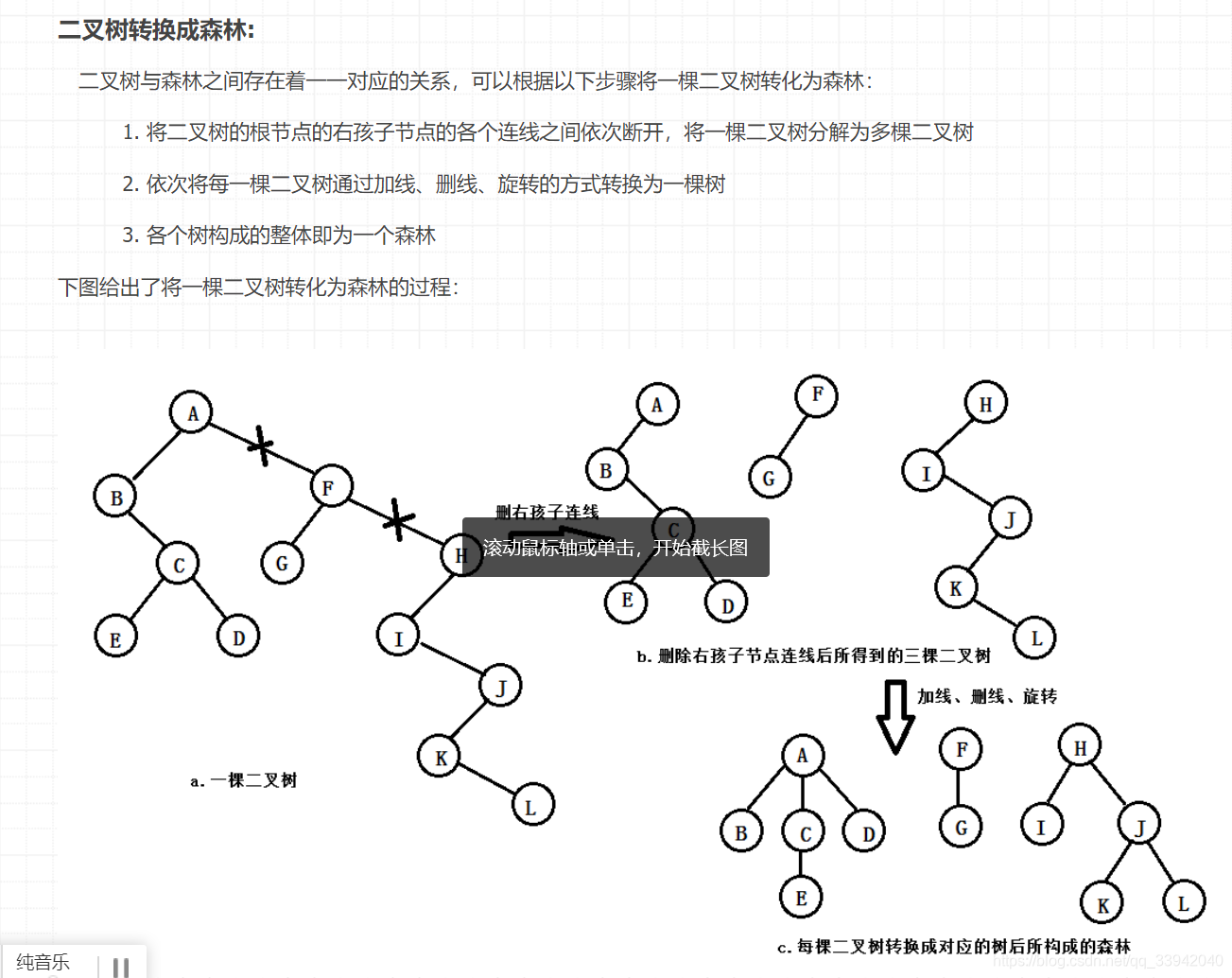
#即砍右节点,向上移一步
5.)矩阵的压缩存储
三种矩阵压缩存储
矩阵类型判定方法
①计算对称矩阵的压缩存储
上三角与下三角的判定方法-->看在主对角线的下面还是上面即可
然后按照公式进行计算即可
程序填空题

1.)补充链表算法题目
第二个在加一句Q=P->next
即核心
2.)

3.二叉树三种算法
//二叉树三种遍历的递归算法
//先序遍历
void PreOrderTraverse(BiTree bt){
if(bt){
printf("%3c",data);
PreOrderTraverse(bt->lchild);
PreOrderTraverse(bt->rchild);
}
}
//中序遍历
void InOrderTraverse(BiTree bt){
if(bt){
InOrderTraverse(bt->lchild);
printf("%3c",data);
InOrderTraverse(bt->rchild);
}
}
//后序遍历
void PostOrderTraverse(BiTree bt){
if(bt){
PostOrderTraverse(bt->lchild);
PostOrderTraverse(bt->rchild);
printf("%3c",data);
}
}















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











