







深度学习笔记(一)神经网络的编程基础
根据吴恩达深度学习笔记5.7版本进行整理,把我觉得有用的给写下来,做到不水吧,写博客一来希望巩固知识,二来或许能帮到大家,三来是一种自律的过程。望他能见证我大二的暑假。
符号定义


第二周
2.1二分类问题(Binary Classification)
用一对(𝑥, 𝑦)来表示一个单独的样本,x表示输入,y表示输出,他只有0或1的值。
2.2 逻辑回归(Logistic Regression)
Hypothesis Function(假设函数)的介绍
sigmoid函数
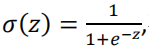
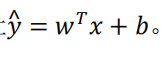
2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
为了训练逻辑回归模型的参数参数𝑤和参数𝑏我们,需要一个代价函数,通过训练代价函数来得到参数𝑤和参数𝑏。损失函数用来衡量预测输出值和实际值有多接近,就是如果𝑦等于 1,我们就尽可能让𝑦^ 变大,如果𝑦等于 0,我们就尽可能让 𝑦^变小。
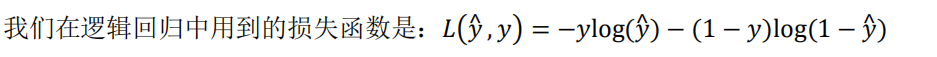
损失函数是对于单个训练样本中定义的,它衡量的是算法在单个训练样本中表现如何,为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,算法的代价函数是对𝑚个样本的损失函数求和然后除以𝑚:
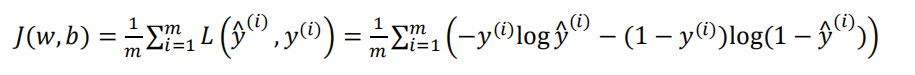
我们需要找到合适的𝑤和𝑏,来让代价函数 𝐽 的总代价降到最低。
2.4 梯度下降法(Gradient Descent)


2.9 逻辑回归中的梯度下降(Logistic Regression Gradient Descent)
前向传播:

反向传播:
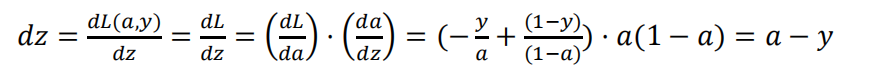
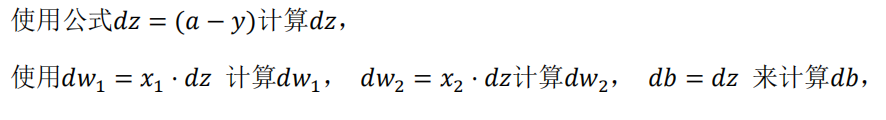
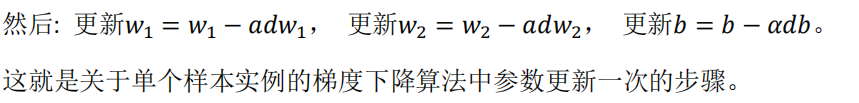
2.10 m 个样本的梯度下降(Gradient Descent on m Examples)
道带有求和的全局代价函数,实际上是 1 到𝑚项各个损失的平均。 所以它表
明全局代价函数对𝑤1的微分,对𝑤1的微分也同样是各项损失对𝑤1微分的平均。
代码流程(这个只是方便理解一下),只应用了一步梯度下降:
J=0;dw1=0;dw2=0;db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
若要多次梯度下降外面还需要一个for循环
2.14 向量化 logistic 回归的梯度输出(Vectorizing Logistic )
Regression’s Gradient)
去for循环的一种方法,减少时间复杂度。
图中仍然是一次梯度下降,多次梯度下降仍然需要加for循环。

2.15 Python 中的广播(Broadcasting in Python)
numpy 广播机制:如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为 1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为 1 的维度上进行。对于 Matlab/Octave 有类似功能的函数 bsxfun。
总结一下broadcastting:

返回目录
















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











