






 本文介绍了如何使用C#的webBrowser控件进行网络编程,实现浏览网页、获取URL及下载网页中的图片功能。通过正则表达式解析HTML,获取图片src路径,并进行下载操作。内容包括界面设计、源代码实现、运行结果展示以及正则表达式基础知识。
本文介绍了如何使用C#的webBrowser控件进行网络编程,实现浏览网页、获取URL及下载网页中的图片功能。通过正则表达式解析HTML,获取图片src路径,并进行下载操作。内容包括界面设计、源代码实现、运行结果展示以及正则表达式基础知识。
该文章主要是通过C#网络编程的webBrowser获取网页中的url并简单的尝试瞎子啊网页中的图片,主要是为以后网络开发的基础学习.其中主要的通过应用程序结合网页知识、正则表达式实现浏览、获取url、下载图片三个功能.而且很清晰的解析了每一步都是以前一步为基础实现的.
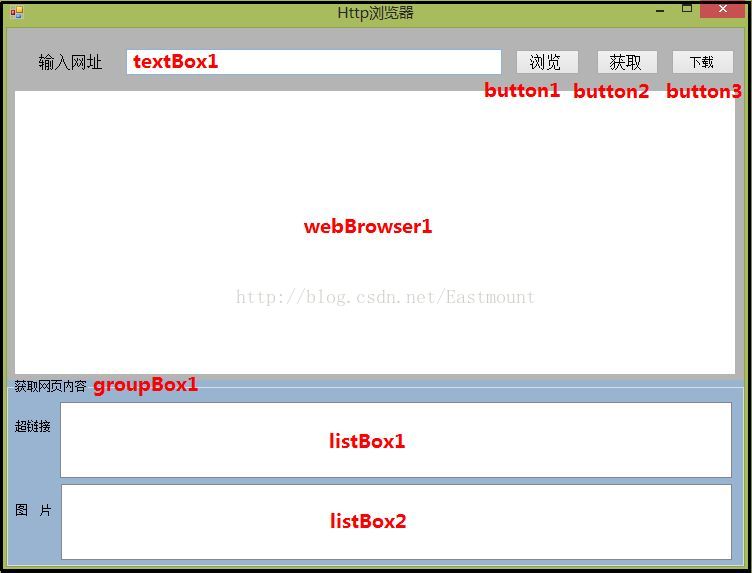
一.界面设计
界面设计如下图所示,添加控件如图,设置webBrowser1其Anchor属性为Top、Bottom、Left、Right,实现对话框缩放;设置groupBox1其Dock(定义要绑到容器控件的边框)为Buttom,实现当浏览器缩放时groupBox1始终在最下边;设置listBox其HorizontalScrollbar属性为True,显示水平滚动条.
二.源代码
1.命名空间
//新添加命名空间
using System.Net;
using System.IO;
using System.Text.RegularExpressions; //正则表达式
2.浏览
点击"浏览"按钮,生成button1_Click(object sender, EventArgs e)点击事件中添加如下代码,实现浏览网页:
private void button1_Click(object sender, EventArgs e)
{
webBrowser1.Navigate(textBox1.Text.Trim()); //显示网页
}调用webBrowser的Navigate方法将指定位置的文档加载到控件中,其中一种重载方法Navigate(urlString)将制定的统一资源定位符URL处的文档加载到WebBrowser控件中替换上一个文档.
3.获取
点击"获取"按钮,生成button2_Click(object sender, EventArgs e)点击事件中添加如下代码,通过获取"html.OuterHtml"当前网页的HTML内容,利用正则表达式获取网页中所有内容的URL超链接和图片的URL,并显示在listBox控件中.
//定义num记录listBox2中获取到的图片URL个数
public int num = 0;
//点击"获取"按钮
private void button2_Click(object sender, EventArgs e)
{
HtmlElement html = webBrowser1.Document.Body; //定义HTML元素
string str = html.OuterHtml; //获取当前元素的HTML代码
MatchCollection matches; //定义正则表达式匹配集合
//清空
listBox1.Items.Clear();
listBox2.Items.Clear();
//获取
try
{
//正则表达式获取<a href></a>内容url
matches = Regex.Match 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









