






How to Better Utilize Code Graphs in Semantic Code Search? [ESEC/FSE 2022]
语义代码搜索极大地促进了软件的重用,使用户能够找到与用户指定的自然语言查询高度匹配的代码片段。由于代码图(如控制流图和程序依赖图)丰富的表达能力,两种主流的研究工作(即多模态模型和预训练模型)都试图将代码图纳入代码建模中。然而,它们仍然存在一些局限性:首先,在搜索效率方面仍有很大的改进空间。其次,他们没有充分考虑代码图的独特特性。
在本文中,我们提出了一个图-序列转换器,即G2SC。G2SC 通过将代码图转换成无损序列,利用序列特征学习解决小图学习问题,同时捕获代码图的边和节点属性信息。因此,可以大大提高代码搜索的效率。特别是G2SC 首先通过特定的图遍历策略将代码图转换为唯一的对应节点序列。然后,它通过用相应的语句替换每个节点来获得语句序列。一组精心设计的图遍历策略保证了过程是一对一的和可逆的。
G2SC 能够捕获丰富的语义关系(即控制流、数据流、节点/关系属性),并提供学习模型友好的数据转换。它可以灵活地与现有模型集成,以更好地利用代码图。作为一个概念验证应用,我们提出了两个G2SC支持的模型:GSMM(G2SC 支持的多模态模型)和GSCodeBERT(G2S支持的CodeBERT模型)。在两个真实大规模数据集上的大量实验结果表明,GSMM和GSCodeBERT可以在R@1上大大提高最先进模型MMAN和GraphCodeBERT的92%和22%,MRR分别提高63%和11.5%。
一句话:提出G2SC,将代码图可逆转换到无损序列,提高序列模型对代码结构语义的学习效果
导论
代码语义搜索使用户能够找到与用户指定的自然语言查询高度匹配的代码片段,对于软件开发人员服务于各种目的,特别是代码重用起着至关重要的作用。
最近的研究工作基于深度学习技术提出了各种多模态模型。由于在高维空间中进行语义表示学习,弥补了查询与源代码之间的词法鸿沟,从而提高了搜索效率。这些工作可分为两大类:1)带预训练的多模态模型,基于transformer架构设计,在多个预训练任务的指导下,学习多模态数据的通用表示,然后针对一组与代码相关的下游任务进行微调,如代码搜索、代码摘要等;2)没有预训练的多模态模型,以端到端的方式专门为代码搜索进行训练。为简单起见,本文将上述第一和第二主流工作中的模型分别称为预训练模型和多模态模型。CodeBERT[10]和DCS[13]分别是预训练模型和多模态模型的例子。
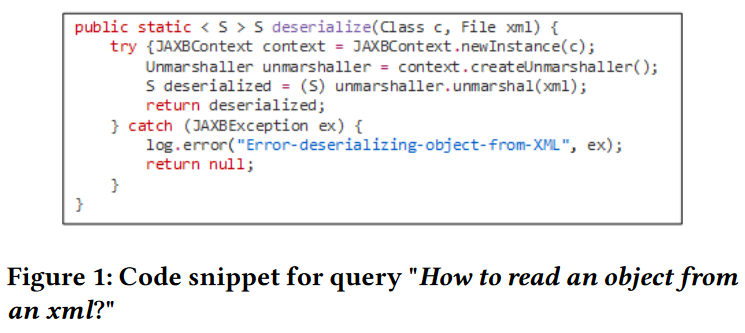
尽管这些模型更有能力捕获更多的语义,但它们仍然受制于使用代码的简单特性,而忽略了代码的结构信息。代码图(例如抽象语法树(AST)或控制流图(CFGs))已被证明可以有效捕获源代码丰富结构语义。最近的研究工作是利用这两个研究流中的代码图。例如,在多模态模型中,Wan等[45]通过在模型中集成CFGs提出了一种多模态注意力网络MMAN,采用图神经网络(GNNs)学习隐藏在代码图中的语义信息,然后使用注意力层融合非结构化和结构化特征。在预训练模型流中,GraphCodeBERT[16]引入了一个图引导的掩码注意力函数,以合并捕获数据流的代码结构。然而,通过对两种主要工作的深入研究,有以下两个发现激励了本文的工作。
(1) 两者在搜索效果上都还有很大的提升空间。例如,根据MMAN[45]和GraphCodeBERT[16]报告的原始结果,这两个模型在各自的任务中都达到了最先进的水平。但在MMR(Mean Reciprocal Rank)指标上,MMAN和GraphCodeBERT分别只能达到0.452和0.713。与DCS(0.377)和CodeBERT(0.693)相比,MRR分别仅提高0.075和0.02。
(2) 这两种方法都忽略了代码图信息多样且规模较小的独特特性所带来的潜在困难和挑战。图2(a)显示了图1中代码片段的程序依赖关系图(PDG)[11]。一个PDG包含两类结构信息,即控制依赖关系(控制流的虚线)和数据依赖关系(数据流的实线),以及两类属性信息,即节点属性(每个节点上的语句)和边属性(数据依赖边上的参数变量)。多模态模型MMAN和预训练模型GraphcodeBERT分别将捕获控制流或数据流的代码结构融入到其学习任务中。然而,单独的控制流或数据流只能捕获语句控制关系或变量关系,因此仍然可能丢失许多有价值的信息。更重要的是,代码图通常都很小。如图2(b)所示,从两个用于代码搜索的真实数据集(CodeSearchNet[22]和我们收集的数据集JAVA-2M)中提取的大多数代码图(CFGs和PDGs)只有2-5个节点,很少有超过20个节点的。多模态模型MMAN利用GNNs嵌入CFGs作为结构特征。然而,现有的研究[19]表明,GNNs通常在具有2000到20000个节点的大型图上取得更好的性能。
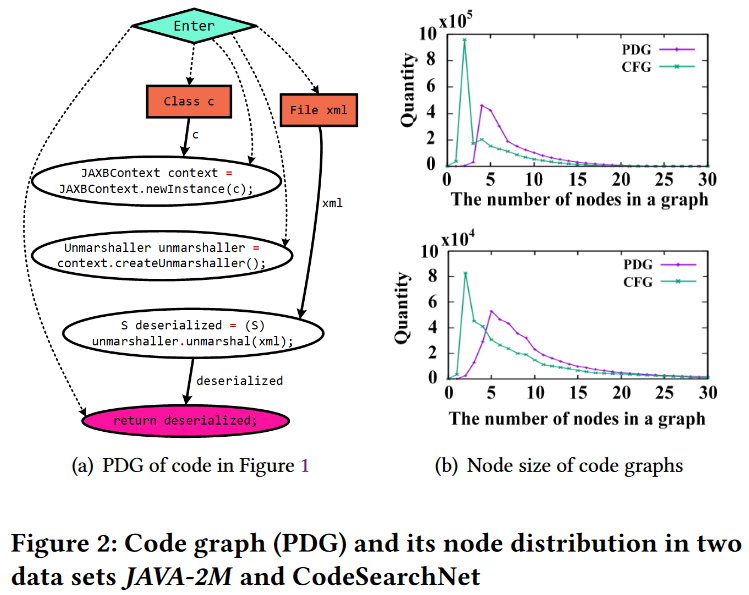
这两个发现激励我们,如果在语义学习模型中更充分地利用代码图的独特特征,代码搜索的有效性可以大大提高。本文提出一种图到序列转换器(Graph-to-Sequence Converter, G2SC)来解决该问题。G2SC通过将代码图转换为保留完整图结构信息的无损序列,能够通过序列特征学习解决使用GNN进行小图学习的问题,并同时捕获代码图的边和节点属性信息。具体来说,G2SC首先通过特定的图遍历策略将代码图转换为唯一对应的节点序列。
一组精心设计的图遍历策略可以保证整个过程是一对一且可逆的。G2SC支持捕获丰富的语义关系(即控制流、数据流、节点/关系属性),并提供学习模型友好的数据转换。此外,为了证明G2SC可以与多模态模型和预训练模型这两个研究流中的最新模型灵活集成,并大大提高其有效性,提出了两个启用G2SC的模型:GSMM (G2SC启用的MMAN模型)和GSCodeBERT (G2SC启用的CodeBERT模型)。具体而言,GSMM采用双向长短期记忆网络(BiLSTM[43])从G2SC转换后的序列中学习代码图的结构化特征,并在此基础上引入注意力层融合非结构化和结构化特征。GSCodeBERT将代码描述序列中的代码序列替换为 G2SC 转换后的序列,以进一步微调CodeBERT模型。我们工作的已经在Github上发布。
https://github.com/G2SMM/G2SC
contributions
(1) 本文提出一种图到序列转换器(Graph-to-Sequence converter, G2SC),将代码图转换为无损序列。通过G2SC,利用序列特征学习可以有效地学习代码图的结构信息。据我们所知,我们是第一个将这一想法引入语义代码搜索的人。
(2) 本文提出两个启用G2SC的语义代码搜索模型:启用G2SC的多模态模型(GSMM)和启用G2SC的CodeBERT (GSCodeBERT)。它们都展示了将G2SC集成到现有模型中的通用性和适用性,以提高利用代码图进行语义代码搜索的能力。
(3) 在各种真实数据集上进行了广泛的实验,以评估所提出的G2SC启用模型。实验结果表明,G2SC在两个数据流上都显著提高了现有模型的性能。例如,在MRR方面,GSMM将DCS和MMAN分别提升了100%和63%,而GSCodeBERT将CodeBERT和GraphCodeBERT分别提升了13%和11.5%。
方案
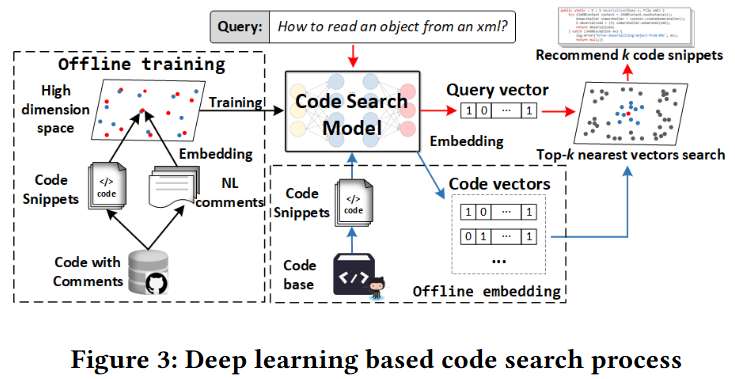
如图3所示,基于深度学习的语义代码搜索的整体过程包括离线训练、离线代码嵌入和在线代码搜索三个主要阶段。
代码图的独特特性给现有的语义代码搜索模型带来了巨大的挑战。为了提高它们的有效性,确保数据能够得到支持并很好地适应学习模型可能是一种很有前途的方法。不幸的是,现有的学习模型,甚至GNN,都不太适合学习代码图。
Converter
为了解决这个问题,我们提出了一个基于图-序列转换器(G2SC)的解决方案。图4给出了在代码搜索模型中使用G2SC的总体框架,它是整个代码搜索过程的核心。一旦训练了有效的代码搜索模型,我们只需要在图3的后两个阶段(即离线代码嵌入和在线代码搜索)中应用G2SC,就可以找到高度匹配用户指定的自然语言查询的代码片段。
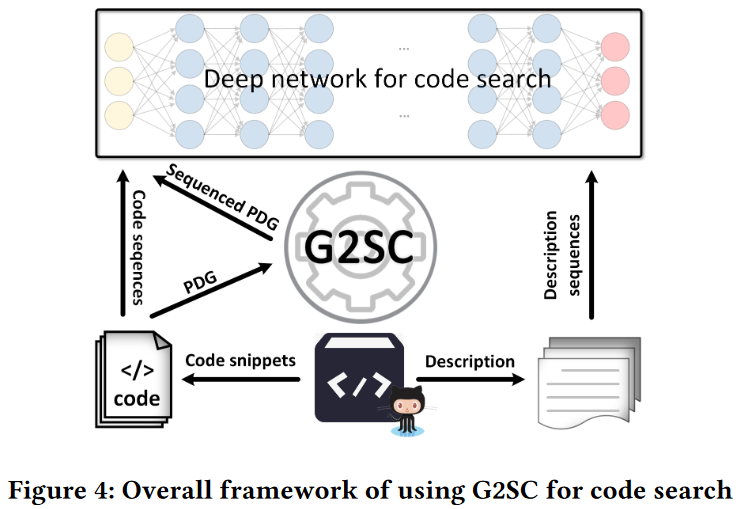
我们的解决方案包括两个主要组件:1) G2SC模块。它将代码图转换成一种模型友好的数据格式,代码序列可以无损地保留代码图的结构信息以及与边和节点相关的关键属性信息;2) G2SC-enabled模型。通过学习G2SC转换的序列和其他代码信息,如代码文本信息和自然语言描述,通过不同的精心设计的策略,我们可以开发各种支持G2SC的模型。
它首先通过特定的图遍历将代码图转换为唯一的对应节点序列。然后,它通过用相应的语句替换每个节点来获得语句序列。一组精心设计的图遍历规则保证了过程是一对一的和可逆的。因此,图结构信息无损地保留在转换序列中。为了便于演示,我们将使用PDGs来解释G2SC。原因之一是PDG是一个比CFG等代码图更复杂的代码图,同时具有控制依赖和数据依赖[11]。另一个原因是,在我们提出的模型中,PDG被用作图特征。G2SC 可以很容易地扩展,以处理不同类型的代码图,如CFG等。

算法1提供了图到序列转换算法的细节。在第一步中,给定一个PDG,我们需要为我们想要生成的PDG序列识别序列入口节点。由于PDG只有一个根节点,因此可以直接选择一个PDG的根节点
v
0
v_0
v0作为整个PDG序列(算法1第1行)的入口
s
0
s_0
s0。
之后,从节点
s
0
s_0
s0开始,按照以下规则依次递归选择一条边进行扩展: 1) 在前向边(端点未遍历的边)之前选择回溯边(端点已遍历的边); 2) 当有多条回溯边或只有多条正向边时,可以在第一步之后选择控制依赖边或数据依赖边进行遍历。任何一个优先级都可以产生唯一的结果。在图到序列算法中,将控制依赖边设置为具有更高的优先级(算法1第4-8行); 3) 如果在第二步之后仍然无法确定边缘,选择端点优先级最高的边缘作为优先扩展的边缘。节点的优先级由代码片段中相应语句的顺序决定(算法1 Function Edge_Check); 4) 特别是,如果没有连接的边,则继续遍历返回到最近的祖先节点,该节点至少有一条边未被遍历(算法1第9-11行)。在遍历PDG的过程中,可以按照以下两个步骤来生成提出的PDG序列(算法1 Function Sequence_Expand): 1.如果遍历的边𝑒是控制依赖边,我们只将𝑒所指向的节点的属性添加到生成的PDG序列𝑆; 2.如果遍历的边𝑒是数据依赖边,则将𝑒的属性和𝑒所指向的节点的属性依次添加到𝑆。
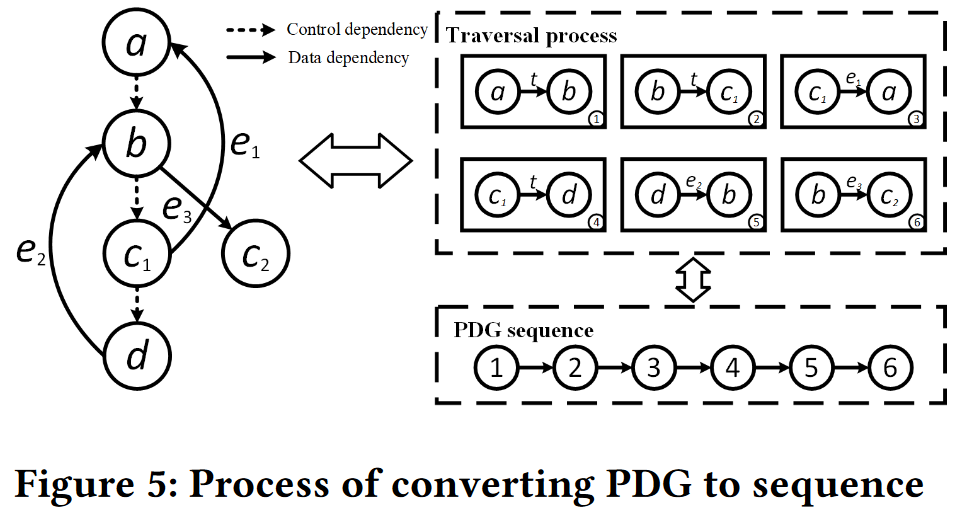
我们给出图5中的一个示例来说明如何将PDG转换为其唯一的相应序列。对于图5中的PDG,节点的顺序是它们在程序中执行的顺序,虚线表示控制依赖边,实线表示数据依赖边,其属性为
e
i
e_i
ei。简单来解释,a作为根节点首先执行序列化,此时a出去的边只有a→b,所以第一个序列化节点就是{a→b},接着执行序列化的是b节点,根据优先级是先遍历所有控制依赖边,所以得到{b→
c
1
c_1
c1},下面是
c
1
c_1
c1执行序列化,此时回边优先级最高,所以选择{
c
1
c_1
c1→a}。注意,到这一步应该是a继续执行序列化,但是a的出边已经遍历完,则根据算法选择最接近的父节点,即
c
1
c_1
c1继续执行序列化操作,下一步得到{
c
1
c_1
c1→d},接着是d执行序列化操作,同理回边优先级最高,控制依赖边次之,数据依赖边最后,所以这一步是{d→b},最后对b执行序列化操作,只剩下数据依赖边
e
3
e_3
e3,所以得到{b→
c
2
c_2
c2}。
(根据算法,模拟一遍示例就明白了)
Data Pre-processing
预处理是基于大规模的训练语料库进行的。对于多模态模型,我们首先提取一组成对的代码片段及其相应的描述。对于描述部分,我们提取所有单词并通过JAVA单词拆分API对它们进行排序,以获得一个令牌序列。对于代码部分,我们采用相同的方法从代码片段中提取Body Token(函数体中的Token)和method name(函数名)。与DCS类似,我们将令牌视为源代码中的无序令牌。此外,我们通过提取工具TinyPDG从代码片段中提取PDGs。然后,使用第3节中提出的G2SC将所有PDG转换为PDG序列。对于预训练的模型,CodeBERT和GraphCodeBERT都在其下游任务中提供预处理源程序。因此,我们可以直接在我们的GSCodeBERT中使用它们。
G2SC Enabled Multi-modal Model
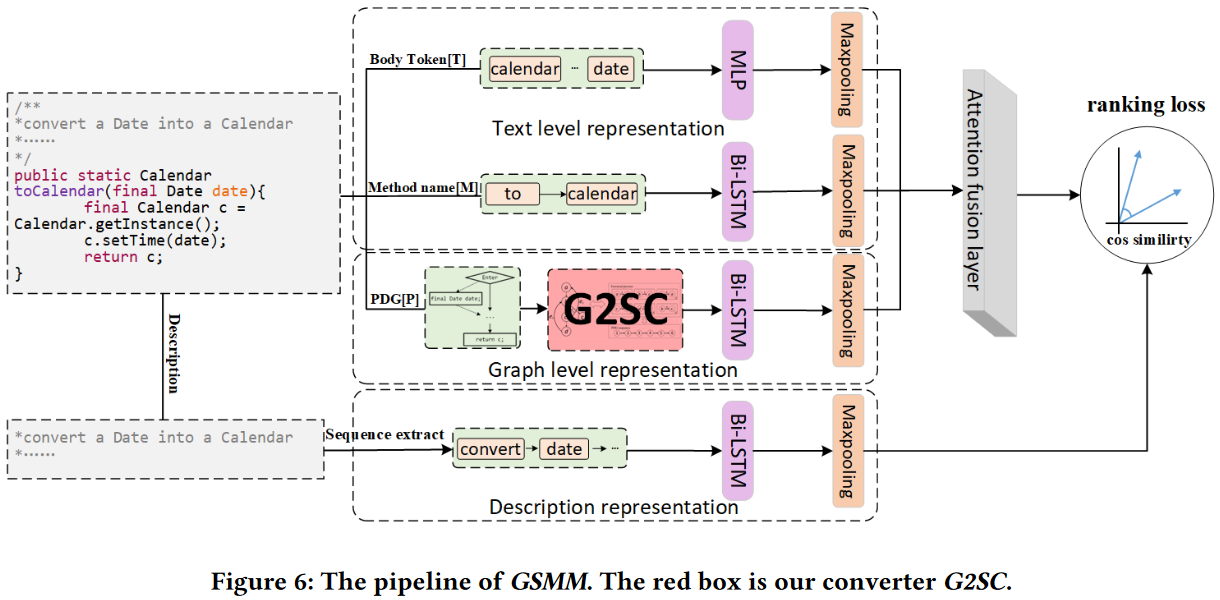
首先,提出支持G2SC的多模态模型GSMM。其中,GSMM利用MLP学习Body token, BiLSTM学习Method Name和PDG序列,并采用注意机制将三种代码特征结合起来。GSMM与其他多模态模型的主要区别在于GSMM使用G2SC转换的PDG序列进行代码图结构学习。
G2SC Enabled CodeBERT Model
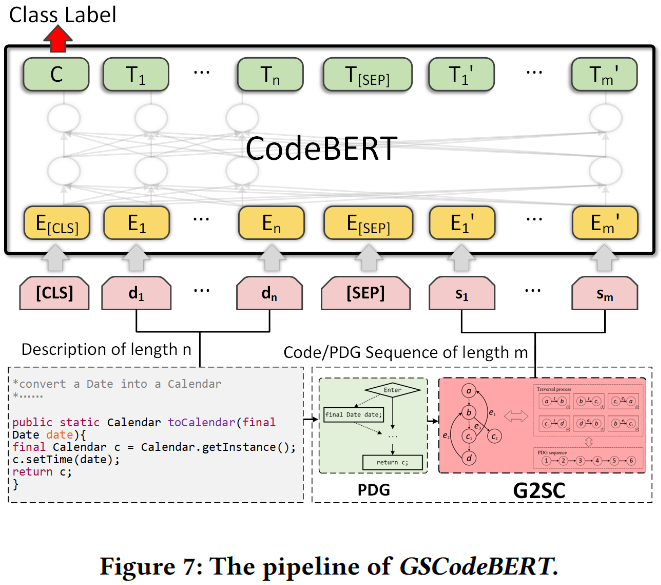
接下来,介绍支持G2SC的CodeBERT模型GSCodeBERT。与其他预训练模型一样,CodeBERT由两个阶段组成:预训练和微调。由于预训练CodeBERT的源代码没有发布,我们只在CodeBERT的下游任务中使用G2SC。
实验
Research Questions

对于RQ1,在比较多模态模型时,我们遵循DCS并使用人工判断。对于人工判断,我们使用DCS提供的50个Java问题。手工分析是由3名具有3-5年Java经验的研究生独立完成的,开发人员进行了公开讨论,以解决50个问题的冲突等级。为了检验统计显著性,我们还应用了Wilcoxon符号秩检验(𝑝 < 0.05)来比较所有查询的FRank值。对于未能在前10个返回结果中获得相关结果的查询,我们保守地将FRank视为11。比较的p值均小于0.05,说明GSMM较相关方法改进显著。
对于RQ2,请注意CodeBERT是在CodeSearchNet上预训练的,我们也使用CodeSearchNet来训练其他预训练的模型,以促进公平的比较。然后,我们使用与原始CodeBERT相同的自动评估方法。
对于RQ3,由于同时考虑了多模态模型和预训练模型,我们同时使用了人工判断和自动评估。
Evaluation Metric

RQ1
表1显示了GSMM、DCS和MMAN在CodeSearchNet上的性能。结果表明,GSMM在所有评估指标上始终优于MMAN和DCS。例如,GSMM的MRR分别比MMAN高62%,55%,45%和24%,分别为R@1, R@5和R@10。在MRR、R@1、R@5和R@10方面,GSMM分别比DCS高出81%、70%、61%和29%。
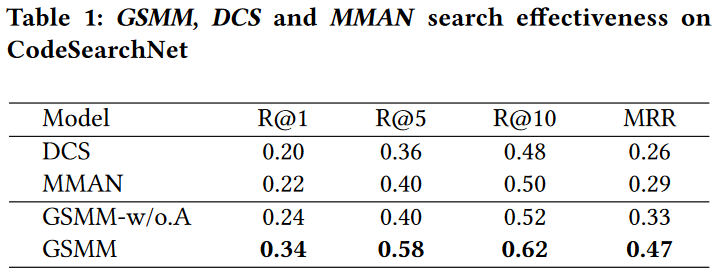
我们按照相同的设置在JAVA-2M上进行实验。如表2所示,与DCS和MMAN相比,GSMM在所有指标上都有显著改善。例如,GSMM在R@1、R@5、R@10和MRR上分别提高了MMAN 92%、43%、16%和63%,而在R@1、R@5、R@10和MRR上分别比DCS高出150%、90%、30%和100%。
此外,表3中的FRank统计数据显示,GSMM的NF(未发现)少于两个基线。这意味着GSMM可以回答更多的问题,并且GSMM推荐的正确代码片段在推荐列表中的排名更高。

RQ2
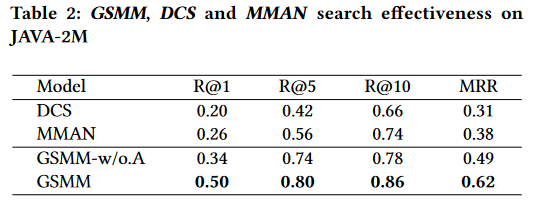
表4展示了CodeBERT、GraphCodeBERT和我们的方法GSCodeBERT的性能。结果表明,GSCodeBERT的性能明显优于CodeBERT, MRR和R@1分别提高了13%和25.7%。潜在的原因可能是CodeBERT可以在G2SC的支持下进一步利用代码片段中的结构信息来学习代码片段和自然语言之间更好的映射。与GraphCodeBERT相比,GSCodeBERT在所有指标上一致地实现了更好的性能,例如,MRR为11.5%,R@1为22%。原因可能是GraphCodeBERT使用了一个自创建的变量图,它只包含变量之间的结构信息。不同的是,我们的PDG序列携带了更丰富的信息,比如代码片段的控件依赖关系和数据依赖关系。
RQ3
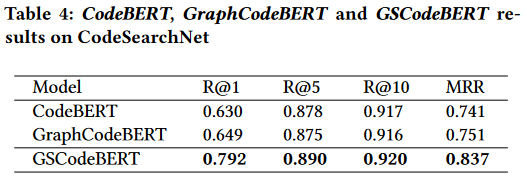
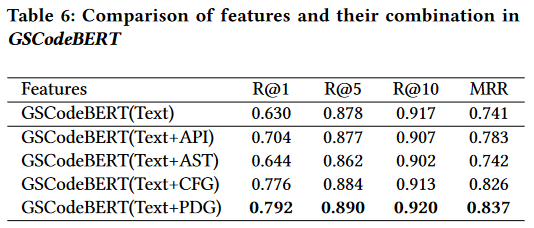
表5给出了GSMM中五个特征和四种组合的比较。结果表明,GSMM在PDG下的性能最好。此外,我们发现CFG和PDG都比代码文本信息表现得更好。这意味着图包含更丰富的语义信息。然而,我们仍然可以观察到文本对性能的贡献。特别是,“Text+PDG”组合在所有考虑的组合中表现最好。
总结
References
[10] Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages (Findings of ACL, Vol. EMNLP 2020). Association for Computational Linguistics, 1536–1547.
[11] Jeanne Ferrante, Karl J Ottenstein, and Joe D Warren. 1987. The program dependence graph and its use in optimization. ACM Transactions on Programming Languages and Systems (TOPLAS) 9, 3 (1987), 319–349.
[13] Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. In 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE). IEEE, 933–944.
[16] Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin B. Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021.
[19] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. arXiv preprint arXiv:2005.00687 (2020).
[22] Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv preprint arXiv:1909.09436 (2019).
[43] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. arXiv preprint arXiv:1409.3215 (2014).
[45] Yao Wan, Jingdong Shu, Yulei Sui, Guandong Xu, Zhou Zhao, Jian Wu, and Philip Yu. 2019. Multi-modal attention network learning for semantic source code retrieval. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 13–25.
Insights
(1) 将源代码上的工作迁移到二进制层面,将图和序列的可逆转换用来提高模型效果。同理,其他的源代码工作均可以考虑迁移到二进制上;
(2) 将二进制提升到PDG程序依赖图,获得最完整的结构信息;
(3) GNN网络在图节点较多时效果更好,至少在2000节点以上。















 7915
7915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









