






requests-BeautifulSoup-re
**************************************************
**************************************************
-------------------选择器----------------------
<html>.css('a::attr(href)').extract()
<html>.css('a::attr(href)').extract()
print('a::href="http://blog.csdn.net/qq_33993724" ') #引号括起来
----
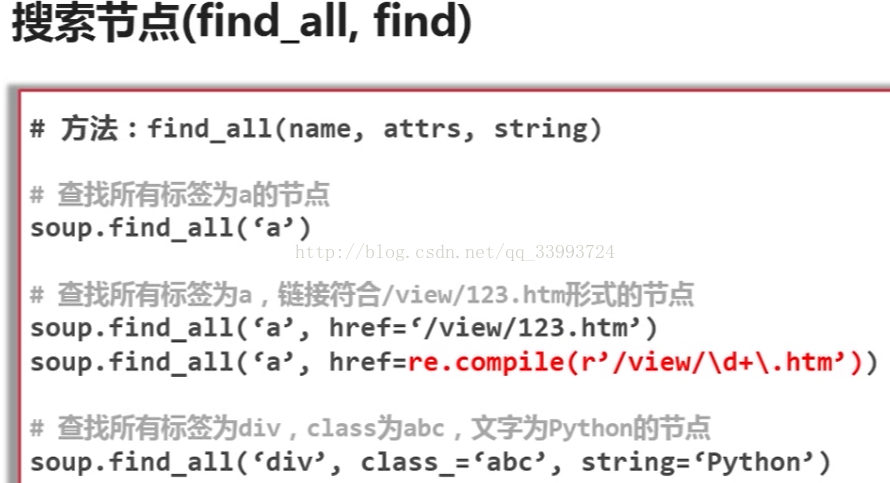
<tag>(..)等价于 <tag>.find_all(..)
----
<tag>(..)等价于 <tag>.find_all(..)
print('<a>(href="http://blog.csdn.net/qq_33993724")') #引号括起来
soup(..)等价于 soup.find_all(..)
print(soup("a")[:3])
soup.find_all(string = "basic ") #全文搜索 basic关键字
for tag in soup.find_all(True): #打印所以标签
print(tag.name)
----------------正则表达式----------------
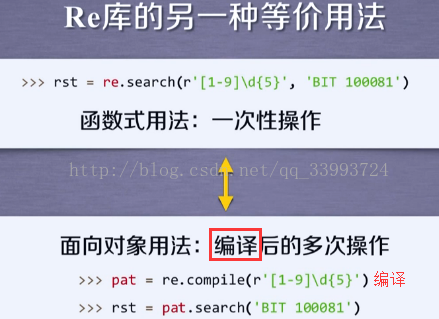
rst = re.search(r'[1-9]\d{5}','BIT 100081') #筛选邮编地址
等价于:
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
print(tag.name)
----------------正则表达式----------------
rst = re.search(r'[1-9]\d{5}','BIT 100081') #筛选邮编地址
等价于:
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
------
.group的编号:
编号为0的group,始终代表匹配的整个字符串;
你在正则表达式内所看到的,通过括号括起来的group,编号分别对应着1,2,3,…
编号为0的group,始终代表匹配的整个字符串;
你在正则表达式内所看到的,通过括号括起来的group,编号分别对应着1,2,3,…
-----------经典例子-------------
try:
kv = {"User-Agent":"Mozilla/5.0"} #指定headers
r = requests.get(url,timeout=30,headers=kv)
r.raise_for_status() #不是200,抛出异常
r.encoding = r.apparent_encoding #判断页面编码
except:
print("failed")
print(r.request.url)
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.headers)
print(r.text[:300]) #r.text字符串类型,字符串截取
try:
kv = {"User-Agent":"Mozilla/5.0"} #指定headers
r = requests.get(url,timeout=30,headers=kv)
r.raise_for_status() #不是200,抛出异常
r.encoding = r.apparent_encoding #判断页面编码
except:
print("failed")
print(r.request.url)
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.headers)
print(r.text[:300]) #r.text字符串类型,字符串截取
soup = BeautifulSoup(r.text,"html.parser")
print(soup) #soup类型:<class 'bs4.BeautifulSoup'>
print(soup.find("div"))
print(soup) #soup类型:<class 'bs4.BeautifulSoup'>
print(soup.find("div"))













----------------------------
Response对象的属性
r = requests.get(url)
r.headers
r.requests.url 请求的url,不是应当的url
r.text
r.content 二进制,用于图片,视频等
r.status_code
r.raise_for_status()
r = requests.get(url)
r.headers
r.requests.url 请求的url,不是应当的url
r.text
r.content 二进制,用于图片,视频等
r.status_code
r.raise_for_status()














 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









