






本文主要回顾MongoDB 3.2的选举机制和它们是如何工作的,以及在选举协议中有哪些出新和不同的地方。
MongoDB 3.2修订版提升了选举协议的稳定性!这是激动人心的时刻,更聪明更快的选举都汇聚在这个版本上!在这个最新版本中,你会发现复制(和选举协议)已经有了改进。下面是它的一些变化:
- 新增electionTimeoutMS;
- 现在WriteConcern意味着“j:true“;
- Old j:真正的意思只是主节点;
- New j:真正意味着所有涉及的节点都必须在ACK杂志;
- j:真正意味着你的杂志MS将排第三,每10毫秒(MMAP)同步发生或在默认情况下为33毫秒(WiredTiger);
- Optime在rs.status现在是一个对象,而不是一个时间戳;
当MongoDB从早期版升级时,你将需要启用选举协议。而新的replSets会在它在默认情况下启用。
选举协议:何为选举?
Mongo使用一致性协议。这意味着所有节点在处理时必须知道最新的情况:
- 硬件故障
- 网络拆分
- 时间移位
新的更新,允许更快选举采用electionid来防止独立投票轮之间的超时。这个保证了它没有双重投票,同时也减少了等待知道投票完成的时间。
它是如何做到的?
选举现在有“term”或“vote”标识符(ID)。Terms用于独立的投票轮。每个投票尝试增加ID,在同一项中ID增量防止了节点双投票,使它更容易为节点所知道,如果需要重新表决,在这之前它可能需要高达5分钟的时间。
超时协议有一些新的特征和行为:
- 现有的配置;
- 随机增加到每个节点;
- 在同一时间内,让所有节点有更少的超时机会。
Normal选举过程
下面我将介绍一套典型的复制操作。看起来像下面的配置:
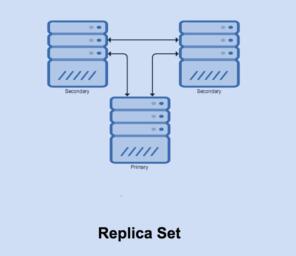
在这个拓扑结构中:
- 有三个成员;
- 它们都是彼此的心跳;
- 没有仲裁者,所以你能得到完整的高可用性(HA)。
下图提供了一个交互的更详细图片:
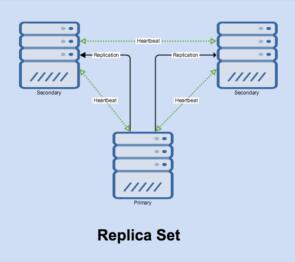
注意如何复制pulls从主到每个次级的主——二次要做所有的工作。所有的节点都共享一个心跳。
当主崩溃时,现在我们看看会发生什么。它只做了这个!
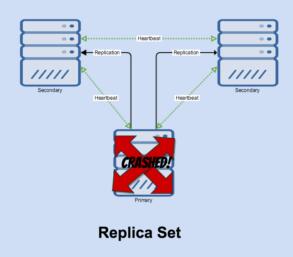
节点将仍然试着心跳去给它,直到在短时间内两个都失败。
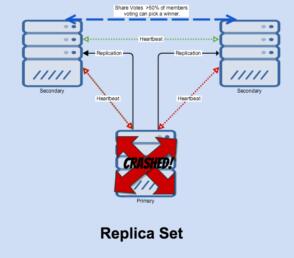
失败之后,会发生以下一些事情:
- Secondaries放弃心跳;
- 然后它们在oplog中互相投票选出谁是最新的;
- 如果有大于 50%的投票人数,他们会选择一个新的冠军。
选择了一个新的主,并且心跳系统会重新被清理。
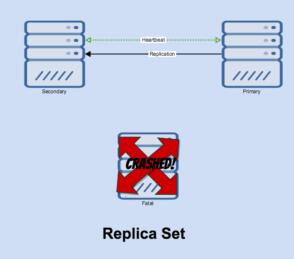
复制现在被重新启动。如果致命的节点重新上线,将被视为一次二次通过oplog的“捕获”。
Stepdown选举过程
Stepdown选举过程和上述是相同的,下面是它的注意事项:
- MUCH速度快得多,因为现在主“开始”一个选举;
- 减少旧主没有数据复制的机会;
- 在进行选举时,这会扼杀写操作;
- 选举过程不等待心跳超时。
一般来说,你应该尝试使用Stepdown选举过程。超时的崩溃和失败,一般不通用。















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









