







import cn.hutool.http.HttpUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class testDemo {
public static void main(String[] args) {
//能直接爬取的网址页面
String html = HttpUtil.get("http://www.nmc.cn/publish/swdz/zxhlhsqxyj.html");
Document parse = Jsoup.parse(html);
//select的值可以通过F12,选中你要爬的数据,然后右击,复制-复制selector
Elements target = parse.select("#text > div.writing");
//如果需要,一层层拆开获取
Elements srcData = parse.select("#text > div.writing > div > img");
String src1 = srcData.get(0).select("img").attr("src");
//标签不重复的话,直接定位获取
//String src2 = target.select("img").attr("src");
System.out.println(target);
System.out.println(src1 );
}
}
需要爬取的页面
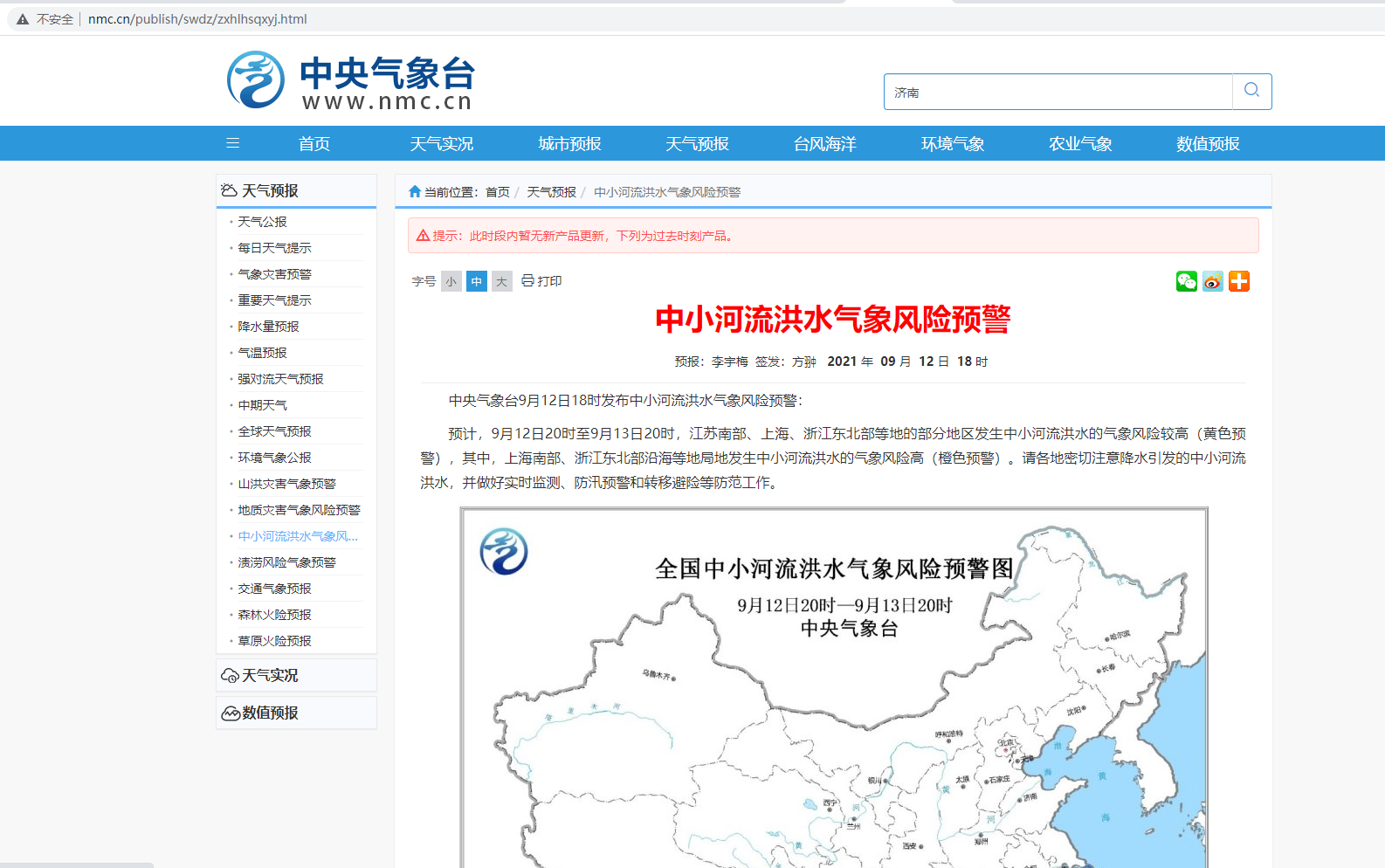
F12获取位置

执行结果
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









