







 本文通过对电商用户行为数据的分析,探讨了用户活跃周期、购买偏好、行为转化和用户价值(RFM模型)等方面,揭示了用户在周末活跃、晚上购买转化率高等特点。此外,发现用户从浏览到购买的转化率低,平台推送商品与用户需求匹配度不高,提出了优化搜索、推送策略和商品详情页的建议,以提高用户转化率和满意度。
本文通过对电商用户行为数据的分析,探讨了用户活跃周期、购买偏好、行为转化和用户价值(RFM模型)等方面,揭示了用户在周末活跃、晚上购买转化率高等特点。此外,发现用户从浏览到购买的转化率低,平台推送商品与用户需求匹配度不高,提出了优化搜索、推送策略和商品详情页的建议,以提高用户转化率和满意度。
阅读之前看这里👉:博主是正在学习数据分析的一员,博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。
博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。
数据分析之实战项目——电商用户行为分析
一、分析背景和目的
随着互联网和电商的发展,人们习惯于网上购物。在国内,电商平台深受欢迎,每年的双11,双12活动,大量的用户在淘宝平台浏览商品,或收藏或加入购物车或直接购买。通过对用户的行为分析,探索用户购买的规律,了解商品的受欢迎程度,结合店铺的营销策略,实现更加精细和精准的运营,让业务获得更好的增长。
本数据来源:阿里天池数据集
数据集介绍:
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包含点击、购买、加购、喜欢),每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。原数据集总共1亿以上数据集,数据量太大,本次分析导入约383万条数据,并在导入的过程中5个字段联合设置主键,导入过程中已经剔除了重复值。
- 用户ID:整数类型,序列化后的用户ID;
- 商品ID:整数类型,序列化后的商品ID;
- 商品类目ID:整数类型,序列化后的商品所属类目ID
- 行为类型:字符串,包括(“pv”:相当于点击,“buy”:商品购买,“cart”:将商品加入购物车,“fav”:收藏商品)
- 时间戳:行为发生的时间戳
工具:Mysql数据库,Navicat Premium 12,Excel
二、分析框架和思路
首先明确我们的分析的目的,是要对电商用户行为进行一个分析。那么应该主要从用户维度、产品维度、用户行为的维度,如下图所示:
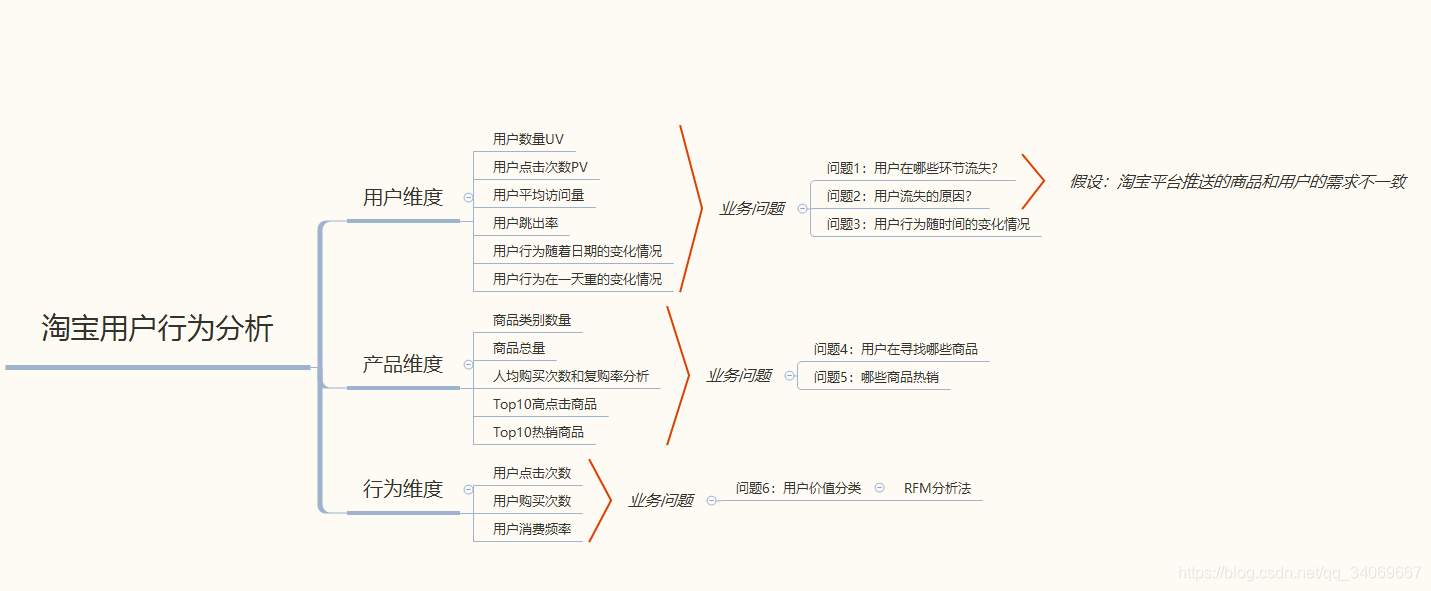
2.1 用户维度
在用户维度我们想要知道什么问题呢?了解用户购买的行为习惯。
需要哪些指标呢:
PV、UV、平均访问量、跳失率等指标,分析用户最活跃的日期及活跃时段
2.2 产品维度
从成交量、人均购买次数、复购率等指标,探索用户对商品的购买偏好,了解商品的销售规律
2.3用户行为维度
从收藏转化率、购物车转化率、成交转化率,对用户行为从浏览到购买进行漏斗分析
2.4用户价值维度(RFM)
参照RFM模型,对用户进行分类,找出有价值的用户
三、分析正文
分析步骤如下:
提出问题------理解数据------数据处理和清洗------构建模型------数据可视化
3.1 提出问题
- 用户最活跃的日期及时段
- 用户对商品有哪些购买偏好
- 用户行为间的转化情况
- 用户分类,哪些是有价值的用户
3.2 理解数据
- 用户ID:整数类型,序列化后的用户ID;
- 商品ID:整数类型,序列化后的商品ID;
- 商品类目ID:整数类型,序列化后的商品所属类目ID
- 行为类型:字符串,包括(“pv”:相当于点击,“buy”:商品购买,“cart”:将商品加入购物车,“fav”:收藏商品)
- 时间戳:行为发生的时间戳
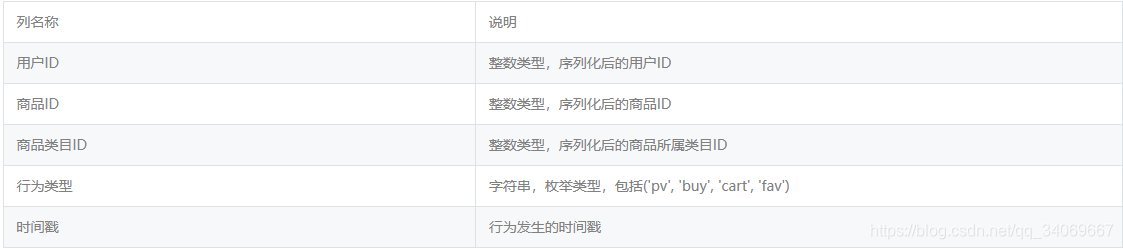
3.3数据处理和数据清洗
3.3.1 列名重命名
导入至Navicat的过程中将字段名更改为英文,方便编写SQL语言
| 字段 | 字段(中文名) |
|---|---|
| UserID | 用户ID |
| ItemID | 商品ID |
| Category | 商品类目ID |
| Behavior | 行为类型(pv,buy,cart,fav) |
| time | 时间戳 |
导入数据类型如下:
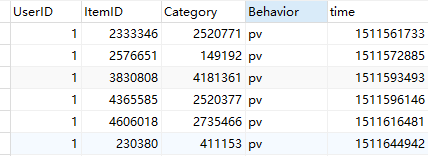
我们看到time的格式并不是标准的时间格式,所以需要对其进行处理。
3.3.2 时间格式的处理
- 原数据时间戳time字段部分使用的是整数型,需要转换为日期时间形式。添加字段datetime(日期时间)、time_date(日期)、time_hour(时间):
alter table userbehavior add datetime datetime;
alter table userbehavior add time_date varchar(255);
alter table userbehavior add time_hour varchar(255);
- 给添加的字段更新数据
update userbehavior set datetime=from_unixtime(time);
update userbehavior set time_date=mid(datetime,1,10);
update userbehavior set time_hour=right(datetime,8);
时间格式处理结果如下:

3.3.3 选择所需数据集
- 选取时间为2017年11月25日至2017年12月3日的数据集
delete from userbehavior where time_date < '2017-11-25' or time_date >'2017-12-03';
- 对处理完的数据进行检验
select max(time_date),min(time_date) from userbehavior;

我们可以看到数据范围正确
- 检查是否有缺失值
select count(UserID),count(ItemID),count(Category),count(Behavior),
count(datetime),count(time),count(time_date),count(time_hour)
from userbehavior;

可以看到一共有3833385条数据,并且无缺失字段和缺失值。
3.4 构建模型
3.4.1用户购物情况整体分析
- UV、PV和平均访问量
select count(distinct UserID) "访客数",
(select count(*) from userbehavior where Behavior = "pv") "点击数",
ROUND((select count(*) from userbehavior where Behavior = "pv")/
count(distinct UserID), 2) "人均访问数" from userbehavior;

我们可以看到这段时间内的访客数为37376,点击数为3431904,人均访问数为91.82次。可以看出:
在这9天中人均每天访问约9次,可见用户经常使用。
- 用户跳出率
用户跳出率的计算公式为:
只 访 问 一 次 页 面 数 / 总 用 户 数 只访问一次页面数/总用户数 只访问一次页面数/总用户数
所以代码为:
select 总用户数,只访问一次页面数,concat((只访问一次页面数 * 100) / (总用户数), "%") "跳出率"
from (select U 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









