







1 分词器
text类型数据存入ES经过的步骤:

2 规范化(normalization)
#采用默认分词器分词
GET _analyze
{
"analyzer": "standard",
"text": "Kobe Bryant"
}

#在match text字段的时候,分词器也会把Kobe Bryant转成kobe 、bryant变成小写去匹配
GET student_index/_search
{
"query": {
"match": {
"name": "Kobe Bryant"
}
}
}

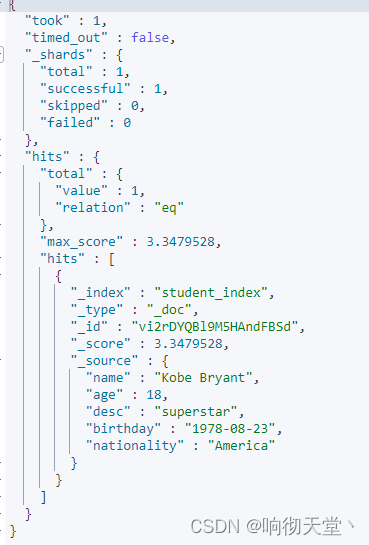
#查看字典序里面是否有Kobe索引
GET student_index/_search
{
"query": {
"term": {
"name": {
"value": "Kobe"
}
}
}
}

3 tokenizer(分词器)
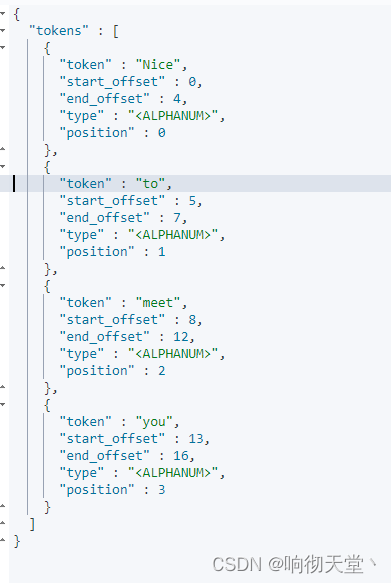
GET _analyze
{
"text": ["Nice to meet you"],
"tokenizer": "standard"
}
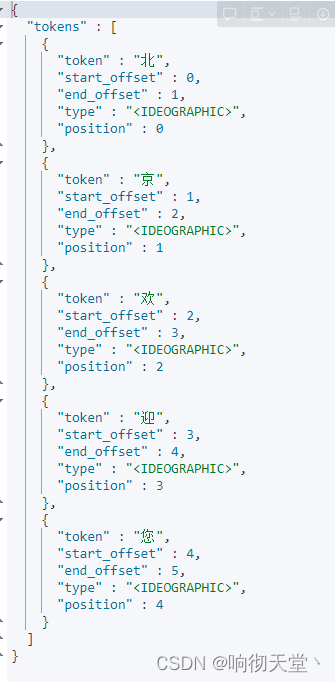
GET _analyze
{
"text": ["北京欢迎您"],
"tokenizer": "standard"
}
4 中文分词器
4.1 挂载目录
4.2 解压删除
#解压
unzip elasticsearch-analysis-ik-8.4.3.zip -d ik-analyzer
#删除
rm -rf elasticsearch-analysis-ik-8.4.3.zip
#给权限
chmod +777 ik-analyzer/
4.3 查看
#进入容器
docker exec -it elasticsearch /bin/bash
#命令查看插件
cd /usr/share/elasticsearch/bin
#查看插件
./elasticsearch-plugin list

4.4 重启ES
docker restart elasticsearch
4.5 测试
GET _analyze
{
"text": "疯狂星期四",
"tokenizer": "ik_smart"
}
GET _analyze
{
"text": "疯狂星期四",
"tokenizer": "ik_max_word"
}

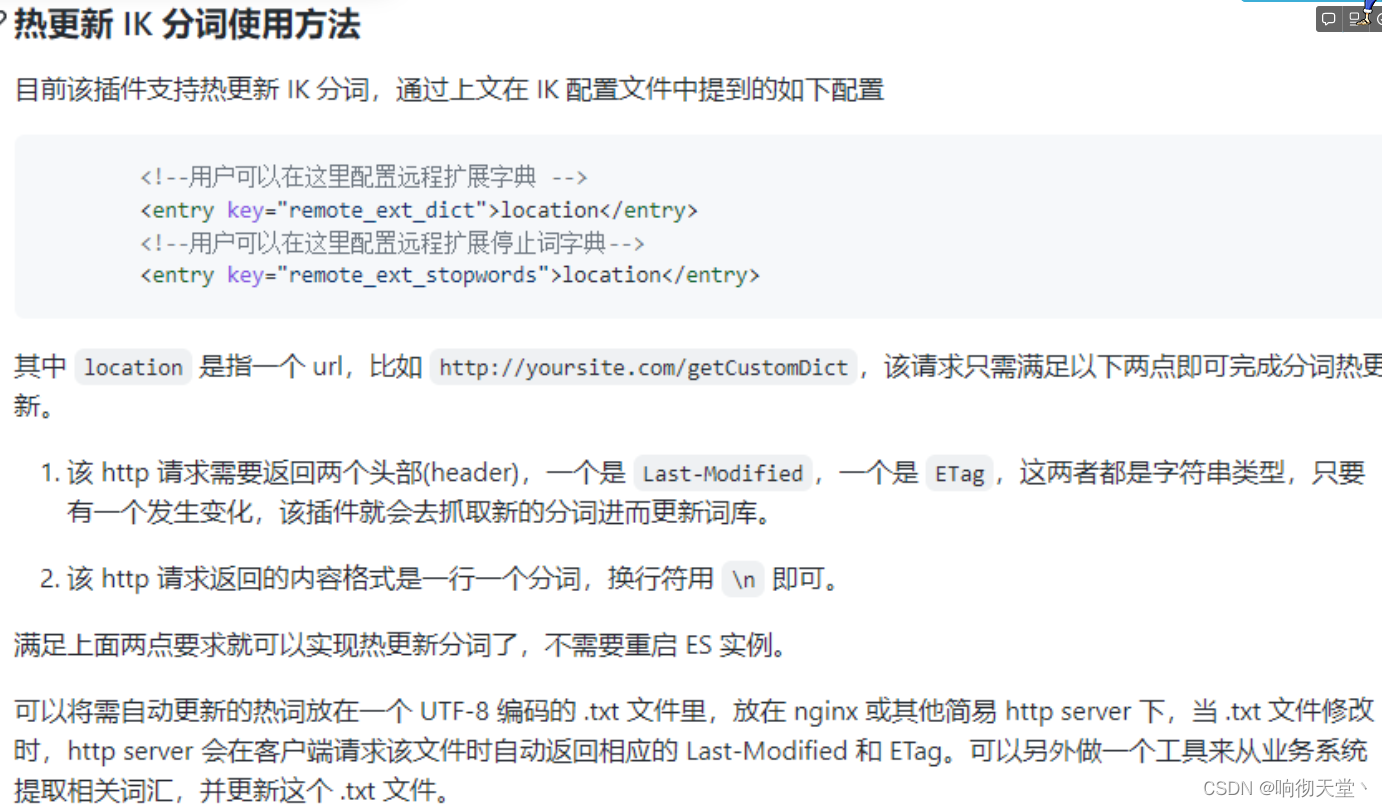
5 基于URL热更新
https://github.com/medcl/elasticsearch-analysis-ik
查看分词效果:
GET _analyze
{
"text": "鸡哥喜欢打篮球",
"analyzer": "ik_smart"
}

java 核心代码:
package com.word.service;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileInputStream;
@Service
public class WordService {
@Value("${config.word.stop}")
private String stopFilePath;
@Value("${config.word.extend}")
private String extendFilePath;
public void getExtendWord(HttpServletResponse response) {
File file = new File(extendFilePath);
getIkWordFormat(file, response);
}
public void getStopWord(HttpServletResponse response) {
File file = new File(stopFilePath);
getIkWordFormat(file, response);
}
private void getIkWordFormat(File file, HttpServletResponse response) {
try (FileInputStream fis = new FileInputStream(file)) {
byte[] buffer = new byte[(int) file.length()];
response.setContentType("text/plain;charset=utf-8");
response.setHeader("Last-Modified", String.valueOf(buffer.length));
response.setHeader("ETag", String.valueOf(buffer.length));
int offset = 0;
if (buffer.length > 0) {
while (true) {
if (fis.read(buffer, offset, buffer.length - offset) == -1) {
break;
}
}
}
ServletOutputStream outputStream = response.getOutputStream();
outputStream.write(buffer);
outputStream.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
}
部署java:
server:
port: 9999
servlet:
context-path: /api
config:
word:
stop: /usr/local/springboot-word/stop.txt
extend: /usr/local/springboot-word/extend.txt
#运行
nohup java -jar springboot-word-1.0-SNAPSHOT.jar &
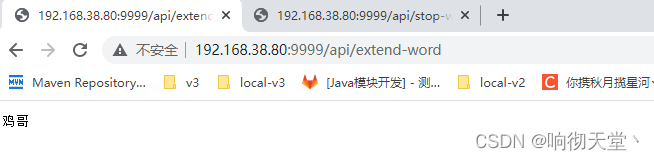
修改es配置文件:
cd /usr/local/elasticsearch/plugins/ik-analyzer/config
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.38.80:9999/api/extend-word</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://192.168.38.80:9999/api/stop-word</entry>
</properties>
重启ES:
docker restart elasticsearch
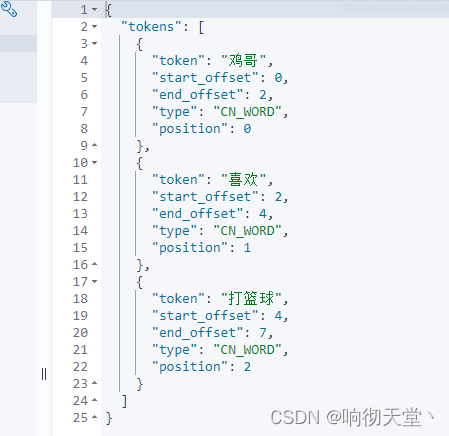
测试:
GET _analyze
{
"text": "鸡哥喜欢打篮球",
"analyzer": "ik_smart"
}
GET _analyze
{
"text": ["鸡哥","坤坤"],
"analyzer": "ik_smart"
}
6 基于Mysql热更新
https://blog.csdn.net/qq_34125999/article/details/127567776?spm=1001.2014.3001.5502
















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











