







1 需求
统计单词出现的次数并且按照次数降序排序
2 JAVA CODE
package com.rosh.spark.wc;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class JavaWordCount {
public static void main(String[] args) {
//创建spark上下文
SparkConf sparkConf = new SparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//读取数据
JavaRDD<String> lines = javaSparkContext.textFile("data/input/word.txt");
//扁平化
JavaRDD<String> wordRDD = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//计数
//聚合
//PairFunction<传入参数,传出参数,传出参数>
//PairFunction<word,word,1>
JavaPairRDD<String, Integer> wordAndOneRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
//聚合
//Tuple的值是integer
//Function2<Tuple1.value, Tuple2.value, 结果>
JavaPairRDD<String, Integer> wordCountRDD = wordAndOneRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//调换顺序
//<word,count> -> <count,word>
JavaPairRDD<Integer, String> countWordRDD = wordCountRDD.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception {
return tp.swap();
}
});
//排序
JavaPairRDD<Integer, String> countWordSortRDD = countWordRDD.sortByKey(false);
// <count,word> -> <word,count>
JavaPairRDD<String, Integer> resultRDD = countWordSortRDD.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tp) throws Exception {
return tp.swap();
}
});
//打印
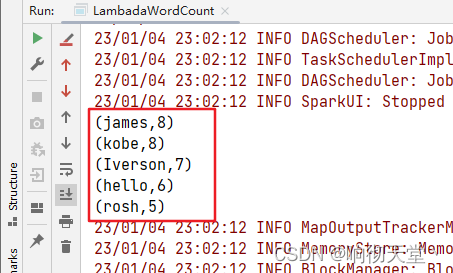
resultRDD.collect().forEach(o -> System.out.println(o));
//关闭连接
javaSparkContext.stop();
}
}
3 JAVA LAMBADA CODE
package com.rosh.spark.wc;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class LambadaWordCount {
public static void main(String[] args) {
//创建spark上下文
SparkConf sparkConf = new SparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//读取数据
JavaRDD<String> lines = javaSparkContext.textFile("data/input/word.txt");
//扁平化
JavaRDD<String> wordRDD = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
//wordToOne
JavaPairRDD<String, Integer> wordToOneRDD = wordRDD.mapToPair(word -> new Tuple2<>(word, 1));
//聚合
JavaPairRDD<String, Integer> wordCountRDD = wordToOneRDD.reduceByKey((c1, c2) -> c1 + c2);
//交换顺序 (word,count) -> (count,word)
JavaPairRDD<Integer, String> countWordRDD = wordCountRDD.mapToPair(tp -> tp.swap());
//排序
JavaPairRDD<Integer, String> coutWordSortedRDD = countWordRDD.sortByKey(false);
//交换
JavaPairRDD<String, Integer> resultRDD = coutWordSortedRDD.mapToPair(tp -> tp.swap());
//打印
resultRDD.collect().forEach(o -> System.out.println(o));
//关闭连接
javaSparkContext.stop();
}
}
















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











