







搜了一圈,都是这种答案,不用估计,就是弃用了。
DataFrame.append在1.4版本中弃用,2.0版本中完全删除。

为啥?
因为它有严重的性能问题,有时候还会出现性能警告
DataFrame is highly fragmented.
This is usually the result of calling `frame.insert` many times,
which has poor performance.
Consider joining all columns at once using pd.concat(axis=1) instead.
To get a de-fragmented frame, use `newframe = frame.copy()`在此前的pandas文档中有这么一段话
It is worth noting however, that concat (and therefore append) makes a full copy of the data,
and that constantly reusing this function can create a significant performance hit.
If you need to use the operation over several datasets, use a list comprehension.翻译过来就是说append操作会生成数据的完整副本,反复重用此函数可能会对性能造成重大影响。
一般来说,append都是在迭代中使用较多。在官方讨论看到说DataFrame.append is around the 10th most visited page in our API docs.
可见,这个方法使用量是相当大的。
比如Brideau这位老哥有一个几百万记录的数据集,使用如下脚本进行处理,肯定是贼慢的
city = ["SomeCity"]
df = DataFrame({}, columns=['Date', 'HouseID', 'Price'])
for city in cities:
for dateRun in data[city]:
for record in data[city][dateRun]:
recSeries = Series([record['Timestamp'],
record['Id'],
record['Price']],
index = ['Date', 'HouseID', 'Price'])
FredDF = FredDF.append(recSeries, ignore_index=True)也有人做过基准测试,使用append和loc都挺慢的。
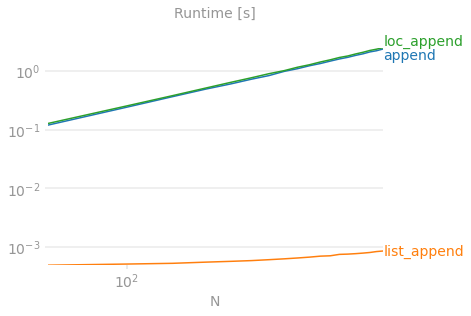
官方推荐:Deprecated since version 1.4.0: Use concat() instead.
但更好的做法是















 8652
8652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









