







抛砖引玉
背景:某服务曾遇到一个学校开通状态同步,使用了kotlin协程异步批量更新学校双开服务,遇到某些学校状态更新不正确。
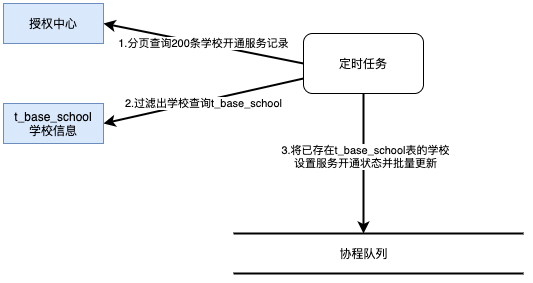
kotlin协程调度原理
什么是协程?
kotlin结构化协程在kotlin协程实现模型最终都会转化为线程执行的任务
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
什么是调度器?
有默认实现,Dispatchers
| 实现 | 类型 | 具体调度器 |
|---|---|---|
| Default | 线程池 | DefaultScheduler/CommonPool |
| Main | UI 线程 | MainCoroutineDispatcher |
| Unconfined | 直接执行 | Unconfined |
| IO | 线程池 | LimitingDispatcher |
从表面可以看出,是自己实现了一个维护许多协程执行的线程池。
调度器具体怎么实现呢?
内部继承关系

以上可以看出:
- 抽象类CoroutineDispatcher 约定类调度器需要的抽象方法。
- ExecutorCoroutineDispatcher提供基本的默认实现。
- CoroutineScheduler为基础的核心调度器实现。
CoroutineScheduler为核心的基本的线程池实现,那它是如何实现一个维护协程生命周期的线程池的?
CoroutineScheduler的设计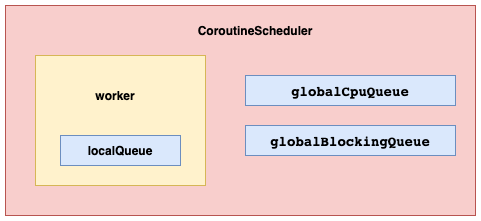
在设计上有点借鉴了常规线程池的设计,包含了创建线程池的核心要素
-
corePoolSize -
maxPoolSize -
idleWorkerKeepAliveNs -
schedulerName
既然是线程池,那是如何维护线程池的worker的数量和状态呢?
controlState的设计
一个原子long型变量记录线程池的核心参数信息。8个字节,64bit

@JvmField
val workers = AtomicReferenceArray<Worker?>(maxPoolSize + 1)
/**
* Long describing state of workers in this pool.
* Currently includes created, CPU-acquired and blocking workers each occupying [BLOCKING_SHIFT] bits.
*/
private val controlState = atomic(corePoolSize.toLong() shl CPU_PERMITS_SHIFT)
private val createdWorkers: Int inline get() = (controlState.value and CREATED_MASK).toInt()
private val availableCpuPermits: Int inline get() = availableCpuPermits(controlState.value)
private inline fun createdWorkers(state: Long): Int = (state and CREATED_MASK).toInt()
private inline fun blockingTasks(state: Long): Int = (state and BLOCKING_MASK shr BLOCKING_SHIFT).toInt()
public inline fun availableCpuPermits(state: Long): Int = (state and CPU_PERMITS_MASK shr CPU_PERMITS_SHIFT).toInt()
companion object {
// A symbol to mark workers that are not in parkedWorkersStack
@JvmField
val NOT_IN_STACK = Symbol("NOT_IN_STACK")
// Worker ctl states
private const val PARKED = -1
private const val CLAIMED = 0
private const val TERMINATED = 1
// Masks of control state
private const val BLOCKING_SHIFT = 21 // 2M threads max
private const val CREATED_MASK: Long = (1L shl BLOCKING_SHIFT) - 1
private const val BLOCKING_MASK: Long = CREATED_MASK shl BLOCKING_SHIFT
private const val CPU_PERMITS_SHIFT = BLOCKING_SHIFT * 2
private const val CPU_PERMITS_MASK = CREATED_MASK shl CPU_PERMITS_SHIFT
internal const val MIN_SUPPORTED_POOL_SIZE = 1 // we support 1 for test purposes, but it is not usually used
internal const val MAX_SUPPORTED_POOL_SIZE = (1 shl BLOCKING_SHIFT) - 2
// Masks of parkedWorkersStack
private const val PARKED_INDEX_MASK = CREATED_MASK
private const val PARKED_VERSION_MASK = CREATED_MASK.inv()
private const val PARKED_VERSION_INC = 1L shl BLOCKING_SHIFT
}
什么时候创建线程?
创建的线程-阻塞的线程 < corePoolSize
private fun createNewWorker(): Int {
synchronized(workers) {
// Make sure we're not trying to resurrect terminated scheduler
if (isTerminated) return -1
val state = controlState.value
val created = createdWorkers(state)
val blocking = blockingTasks(state)
val cpuWorkers = (created - blocking).coerceAtLeast(0)
// Double check for overprovision
if (cpuWorkers >= corePoolSize) return 0
if (created >= maxPoolSize) return 0
// start & register new worker, commit index only after successful creation
val newIndex = createdWorkers + 1
require(newIndex > 0 && workers[newIndex] == null)
/*
* 1) Claim the slot (under a lock) by the newly created worker
* 2) Make it observable by increment created workers count
* 3) Only then start the worker, otherwise it may miss its own creation
*/
val worker = Worker(newIndex)
workers[newIndex] = worker
require(newIndex == incrementCreatedWorkers())
worker.start()
return cpuWorkers + 1
}
}
阻塞的线程不占用CPU
private fun beforeTask(taskMode: Int) {
if (taskMode == TASK_NON_BLOCKING) return
// Always notify about new work when releasing CPU-permit to execute some blocking task
if (tryReleaseCpu(WorkerState.BLOCKING)) {
signalCpuWork()
}
}
private inline fun releaseCpuPermit() = controlState.addAndGet(1L shl CPU_PERMITS_SHIFT)
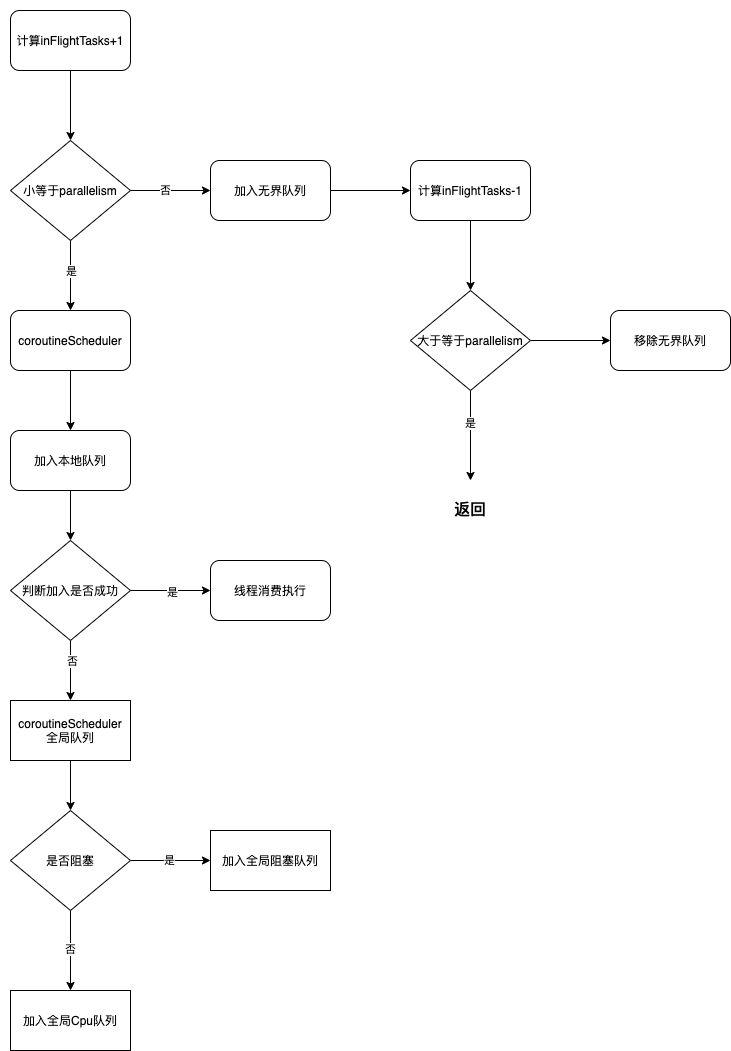
调度原理
主要的核心逻辑为disptach函数,以LimitingDispatcher为例
private fun dispatch(block: Runnable, tailDispatch: Boolean) {
var taskToSchedule = block
while (true) {
// Commit in-flight tasks slot
val inFlight = inFlightTasks.incrementAndGet()
// Fast path, if parallelism limit is not reached, dispatch task and return
if (inFlight <= parallelism) {
dispatcher.dispatchWithContext(taskToSchedule, this, tailDispatch)
return
}
queue.add(taskToSchedule)
if (inFlightTasks.decrementAndGet() >= parallelism) {
return
}
taskToSchedule = queue.poll() ?: return
}
}
CoroutineScheduler的dispatch函数
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
trackTask() // this is needed for virtual time support
val task = createTask(block, taskContext)
// try to submit the task to the local queue and act depending on the result
val currentWorker = currentWorker()
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
if (notAdded != null) {
if (!addToGlobalQueue(notAdded)) {
// Global queue is closed in the last step of close/shutdown -- no more tasks should be accepted
throw RejectedExecutionException("$schedulerName was terminated")
}
}
val skipUnpark = tailDispatch && currentWorker != null
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) {
if (skipUnpark) return
signalCpuWork()
} else {
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark)
}
}
整体调度流程
总结
- 了解协程、调度器基本原理,涉及线程池的基本设计,加深对kotlin协程调度器的理解,有助于后续自定义调度器。
- 调度器涉及很多CAS的使用,提高并发安全设计意识。
- 可以规避协程的不正确使用,提前识别风险。















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









