







引言
在上两篇博文中,我们主要讲述了DS相关的作用和操作,包括如何使用DS去读写内存数据,以及Debug工具的熟练使用。通过Debug工具,我们得以亲身验证之前说过的一些问题和限制,比如 MOV 指令操作CS、IP 寄存器会发生什么样的现象,猜想MOV指令的形式并做实际验证,这些都大大加深了我们对指令使用的认知和理解。
前面说过了代码段和数据段,那么本篇博文中我们将学习栈,了解它的作用和意义。
指令讲解补充
在开始讲解之前,我们先简单说下我们之前提到过的几条汇编指令:
MOV 指令已经说的比较详细,这里就不再做补充,有遗忘的小伙伴可以翻看之前的博文加深学习。
ADD指令和SUB指令
ADD 指令,加法算术运算指令,它和MOV指令一样,同样拥有两个操作对象。ADD 的指令形式基本和MOV 指令形式保持一致,比如它也有 ADD 寄存器,内存单元 ,ADD 内存单元,寄存器 这样的指令形式。内存单元的访问形式也是一致的,DS寄存器中存放段地址,使用 [...] 的格式来表示内存单元。
比如下面的几条汇编指令,展示了使用ADD指令来访问内存单元:
add ax,[0]
含义为:将内存地址DS:0下的字单元内容与AX寄存器中的值进行相加,运算结果放到AX寄存器中。
add al,[0]
含义为:将内存地址DS:0下的字节单元内容与AL寄存器中的值进行相加,运算结果放到AL寄存器中。
请注意区分上述两个指令中操作的数据长度,AX是十六位寄存器,对应的数据长度为一个字,数据就是由DS:[0]、DS:[1]这两个字节组成的字内容;AL是八位寄存器,对应的数据长度为一个字节,数据就是DS:[0]下的字节内容。
add [0],ax
含义为:将内存地址DS:0下的字单元内容与AX寄存器中的值进行相加,运算结果放到内存地址DS:[0]下的字单元中。
add [0],al
含义为:将内存地址DS:0下的字节单元内容与AL寄存器中的值进行相加,运算结果放到内存地址DS:[0]下的字节单元中。
这里博主就不做Debug内验证了,希望小伙伴们可以自己亲自在Debug中验证一下,以加强自己的学习。
SUB 指令,减法算术运算指令,其指令形式和用法和 ADD 指令保持一致,这里博主就不再进行赘述。
JMP指令
JMP 指令,跳转指令,通过修改CS、IP的值达到程序执行逻辑跳转的目的。它照样可以访问内存,指令形式为:JMP 内存单元 。
jmp [0]
含义为:将 IP 寄存器修改为内存地址DS:0下的字单元内容。
补充:由于IP寄存器也是一个十六位寄存器,所以操作的数据长度为一个字,数据为DS:0、DS:1这两个字节组成的字内容。
这里我们去Debug中实际操作并验证一下:
打开Debug,使用A命令向内存中写入如下汇编指令:jmp [0]。为了方便观察,我们先通过E命令将内存地址DS:0字单元内容修改为0。记得注意CS:IP指向是否为会变指令所在的地址,然后通过T命令进行执行,观察 IP寄存器是否被修改为0,结果下图所示:

我们观察发现,执行后,IP寄存器值被修改为0,证明我们的指令执行成功。
小结
ADD指令和SUB指令同MOV指令一样,它们都有两个操作对象,也都有以下几种指令形式:

JMP指令为一个操作对象,存在以下几种操作形式:
JMP 内存地址
会同时修改CS寄存器值和IP寄存器值,比如:jmp 073f:0,含义:将CS寄存器设置为073fH,IP寄存器设置为0H;
JMP 寄存器
只修改IP寄存器值,比如:jmp ax,含义:将IP寄存器值设置为AX寄存器中的值。
JMP 内存单元
也是只修改IP寄存器值,比如:jmp [0],含义:将IP寄存器值设置为内存地址DS:0字单元内容。
上述指令中,ADD指令、SUB指令和MOV指令都无法修改CS寄存器值和IP寄存器值,仅JMP指令可修改CS寄存器值和IP寄存器值。
栈
在学习SS段寄存器之前,首先我们来学习栈的概念。
什么是栈?栈是一种具有特殊的访问方式的储存空间,它的特殊性就在于,最后进入这个空间的数据,会最先出去。也就是LIFO(Last In First Out),后进先出模式。
为了更好的理解栈,我们可以发挥想象,比如,我们把栈想象成是一个只有底没有盖的盒子,现在我们有三本书,如图:

那么现在,我们依次把这三本书放入盒子内:先放入《高等数学》

再放入《C 语言》

最后放入《软件工程》
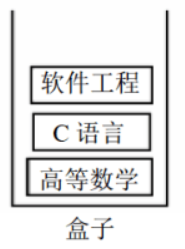
现在三本书放入完毕,那么我们该如何再把它们从盒子里面取出来呢?盒子底部是封住的,只有上面盖子一个出口,所以我们只能从盒子最上面的那本书(此时是《软件工程》)开始向外取:如图

此时最上面的那本书是《C 语言》,那么就只能取出它:

取出《C 语言》后,此时最上面的那本书就变成了《高等数学》,现在才开始取它:

三本书都取完后,盒子为空。
我们对比下上述三本书放入盒子的顺序和从盒子中取出的顺序,就发现:《高等数学》是最先放入盒子的,结果它是最后被取出的;《软件工程》是最后放入盒子的,结果它是最先被取出的。那么我们就可以说,这三本书的放入和取出顺序,符合LIFO模式,即这个“盒子”就是一个栈。
栈的意义
你可能会问,为什么会有栈这种设计?栈存在的意义是什么呢?
栈被设计用来满足程序中的方法调用。例如,一段程序中存在三个方法,分别是方法 A(),方法B(),方法C(),它们三个之间存在相互调用,调用顺序为:A()->B()->C()。A方法中调用了B方法,B方法中调用了C方法。
现在我们执行这段程序,程序先在A()中执行了几段代码,然后跳转到B(),在B()中执行了极端代码,然后跳转到C()。把C()所有代码执行完成后,此时程序需要回到B()中继续执行B()中剩余的代码,将B()所有代码执行完毕后,程序需要回到A()中继续执行A()中剩余的代码,将A()所有代码执行完毕后,程序结束。
我们分析上述程序执行过程,调用顺序为:A->B->C();返回的调用顺序(回调):C->B()->A()。发现顺序遵循LIFO模式,如何满足这个调用顺序?于是便有了栈。
由A()->B()的时候,向栈中放入此时A()中代码地址;由B()->C()时,我们再向栈中放入此时B()中代码地址,这便是入栈。
C()执行完毕后,我们只需要按照顺序依次从栈中取出代码地址即可,首先取出的是B()中的代码地址,程序便可以顺利回到B()中继续执行;B()中执行完毕后,此时栈中最上边的便是A()中代码地址,取出,程序便回到了A()中继续执行,这便是出栈。
由于栈的特殊访问模式,使得它的功能远不止上述程序中方法调用那么简单。
在我们开发中,还会经常使用栈来保存数据。比如我们从当前方法跳转到另外一个方法时,我们需要把当前方法中用到的一些数据保存下来,这样等程序返回时,可以方便恢复当前方法中的数据,使程序得以正确地继续执行下去,这叫做“保护现场”。如果没有栈,想一想,程序从别的方法回来之后,结果数据变了样,那么执行肯定会有错误或者异常。
和栈打交道的指令
现在我们已经明白了栈的含义以及它的作用和它特殊的访问方式,那么下面我们就学习两个和栈打交道的指令:push,pop。
PUSH:入栈指令,它有一个操作对象。操作对象可以是寄存器,也可以是内存单元。
push ax
含义:将AX寄存器中的值放入栈中
push [0]
含义:将内存地址DS:0下的字单元内容送入栈中。
注意:PUSH指令一次操作的数据长度为一个字,所以 push [0] 操作的数据为DS:0、DS:[1]这两个字节单元组成的字单元内容。由于数据长度为一个字的限制,所以 push al 是不可以的,为非法指令。
POP:出栈指令,和PUSH一样,它也有一个操作对象。操作对象可以是寄存器,也可以是内存单元。
pop ax
含义:将当前栈顶的字数据放入AX寄存器中
pop [0]
含义:将当前栈顶的字数据放入内存地址DS:0下的字单元中。
注意:POP指令一次操作的数据长度也是一个字。
栈空间
所谓的栈空间实际上也是一段被人为定义的内存地址空间,我们可以称这段空间为栈段。
之前我们学习了代码段、数据段,栈段本质上和代码段、数据段是一样的,都是一段连续的内存地址空间,区别就是:在任意时刻,CPU将栈段中的数据当作栈中数据来操作处理。
比如,我们将10000H~1000FH这段内存当作栈空间,那么我们可以说10000H~1000FH是栈段,段地址为1000H:0H,栈底为1000H:FH,栈大小为16个字节。向该段内存中写入数据的操作就是入栈,从这段内存中读取树的操作就是出栈。如图该栈空间在内存中的表示:
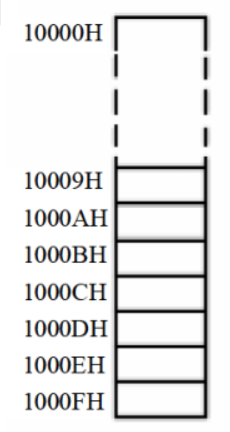
这里可能会有疑问,为啥栈底是1000H:FH,而不是1000H:0H呢?
因为栈段,实际上是个有范围空间。什么是有范围空间?就是说这段空间有具体已经明确的起始地址和结束地址。我们说的代码段和数据段,这两个段空间并不是有范围空间,因为它们实际上并未有准确的起始地址和结束地址,CPU只是固执的拿段寄存器和偏移指针的指向来当作这就是某种数据。
栈空间则是由固定的且明确的起始地址和结束地址组成一段内存地址空间。当然,这个明确的起始地址和结束地址,也是我们人为定义的,CPU本身并没有这样的概念。为啥栈就非要有明确的起始地址和结束地址?这其实和栈本身特殊的访问方式是相关的,因为在访问的时候你需要知道栈中的数据是否已经取完,亦或者栈中数据是否已满,这就要求必须存在明确的栈顶(起始地址)和栈底(结束地址)。
下面我们解释为啥栈底就要是1000H:FH?我们已经明确栈空间是有范围空间,所以我们就需要划分出栈的栈顶和栈底。1000H:0H这个地址只能是段地址,因为CPU要在此地址上进行寻址,寻址我们都知道是基于基地址向前寻,所以只有1000H:0H为基地址才能把整个栈空间寻完。
由于栈的特殊访问方式,无法从栈底进行数据的读写,只能通过栈顶来访问栈(联想我们上面讲解的比喻:底部封闭上面没盖的盒子),结合CPU寻址方式,所以栈顶也只能是1000H:0H。这样,栈底也只能是1000H:FH了。
本篇结束语
本篇博文中我们主要讲述了ADD指令、SUB指令以及JMP指令访问内存的方式,重点讲述了栈的概念,并且学习了两个操作栈的指令:PUSU和POP。
下篇博文我们将学习SS段寄存器与栈的关联,包括如何如何使用SS来访问栈。
感谢围观,转发分享请标明出处,谢谢!















 2572
2572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









