




1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2.案例
使用中间件完成对豆瓣前250电影的爬取
项目结构如下
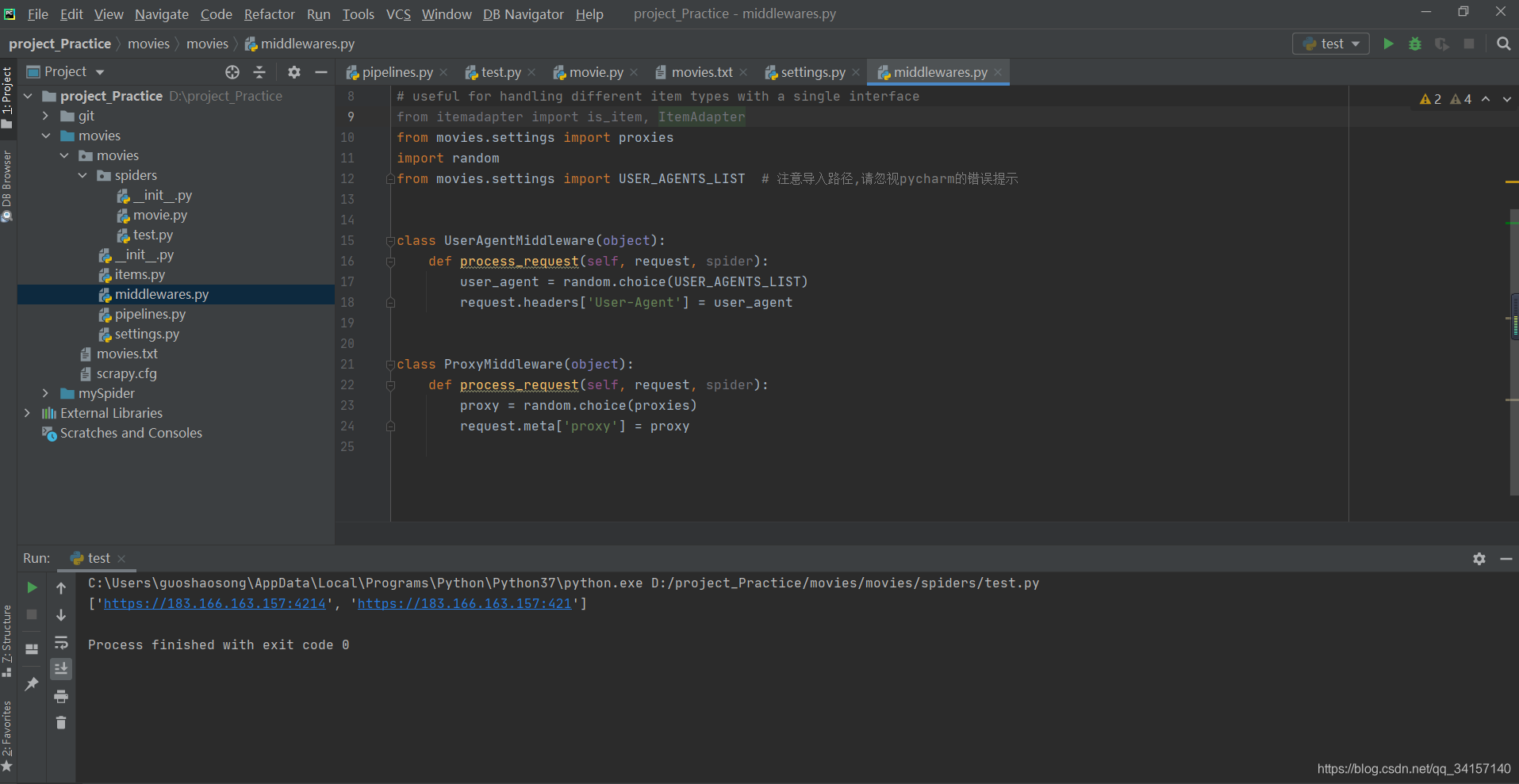
其中test.py是对代理池进行过滤的文件
2.1 设置请求中间件
在setting中设置请求头列表以及代理池
首先对代理池进行过来吧,我用的代理是芝麻代理,1块钱活动获取100条·,链接如下:官网直达
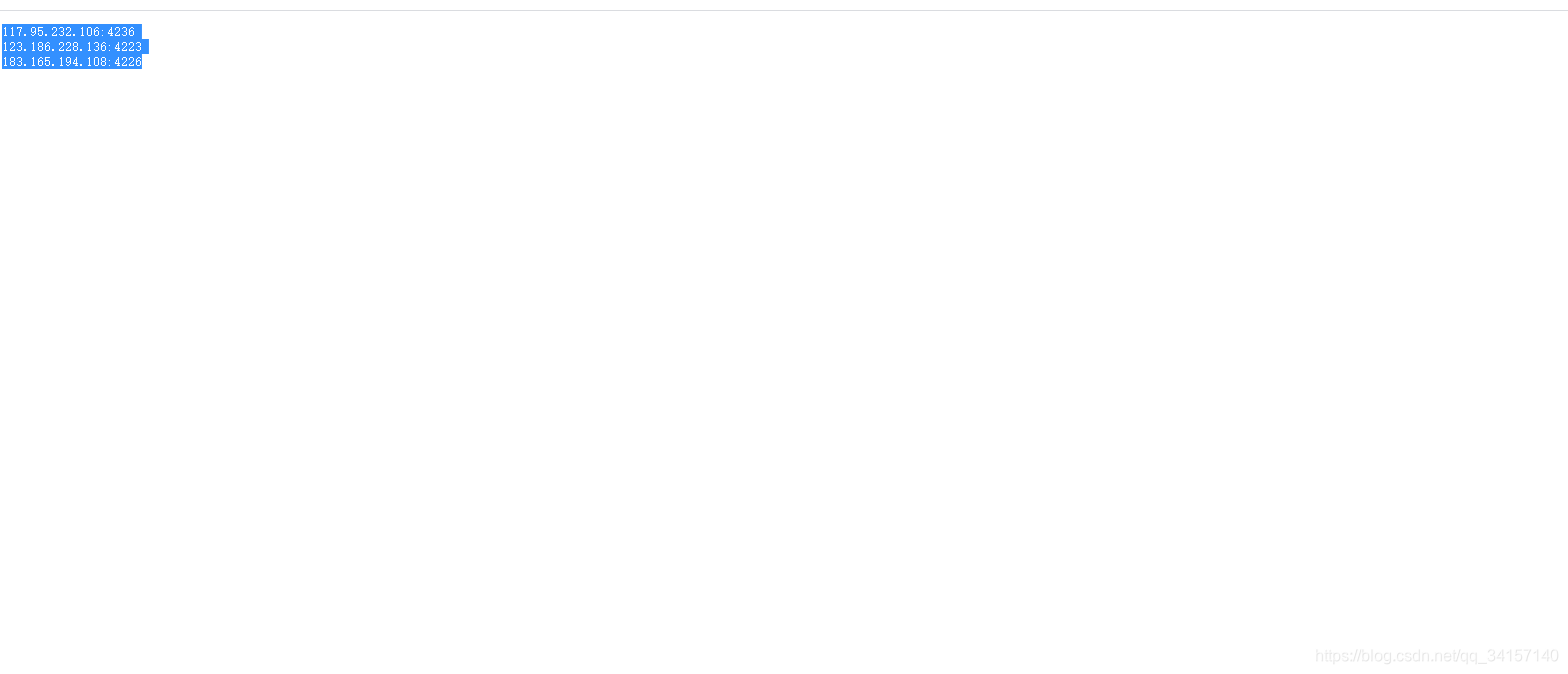
因为便宜,所以有时间限制,可以使用率有90%,所以获取到代理后过滤下。向百度发请求(百度支持http和https协议),代码如下:
import requests
from requests.exceptions import ProxyError
if __name__ == '__main__':
post_url = "https://www.douban.com/"
header = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
'Connection': 'close'
}
proxies = [
"https://183.166.163.157:4214",
"https://183.166.63.157:4214",
"https://183.166.163.157:421",
]
for proxy in proxies:
try:
response = requests.get(url=post_url, headers=header, proxies={'https': proxy})
except ProxyError:
proxies.remove(proxy)
print(proxies)
这种过滤办法稍显low,大佬有更好的教一下我。。。。。
接着是setting中设置请求头和代理池
USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
proxies = [
"https://183.166.163.157:4214",
"https://183.165.128.5:4231",
"https://42.179.173.127:4286"
# "https://42.54.95.85:4252"
# "https://1.70.76.153:4236"
# "https://112.116.248.134:4256"
]
其次是中间件中的设置
from itemadapter import is_item, ItemAdapter
from movies.settings import proxies
import random
from movies.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示
class UserAgentMiddleware(object):
def process_request(self, request, spider):
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
class ProxyMiddleware(object):
def process_request(self, request, spider):
proxy = random.choice(proxies)
request.meta['proxy'] = proxy
爬虫文件如下:
import scrapy
from movies.items import MoviesItem
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['douban.com']
start_urls = ['https://www.douban.com/movie/top250']
def parse(self, response):
print(response.request.meta['proxy'])
print(response.request.headers['User-Agent'])
movie_list = response.xpath('*//div[@class="info"]')
item = MoviesItem()
for movie in movie_list:
item['name'] = movie.xpath('.//span[@class="title"]/text()').extract_first()
item['info'] = movie.xpath('.//p[1]//text()').extract_first()
item['score'] = movie.xpath('.//span[@class="rating_num"]/text()').extract_first()
item['desc'] = movie.xpath('.//p[2]//text()').extract_first()
yield item
# 进行翻页操作
back_url = response.xpath('//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href').extract_first()
if back_url is not None:
back_url = response.urljoin(back_url)
yield scrapy.Request(url=back_url, callback=self.parse)
最后我对爬取文件进行了保存
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class MoviesPipeline:
def open_spider(self, spider):
self.f = open('movies.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
item = dict(item)
item = json.dumps(item) + ',\n'
self.f.write(item)
return item
def close_spider(self, spider):
self.f.close()

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









