







在web应用中,当数据量非常大时,即使MySQL的存储能够满足,但性能一般也会比较差。此时,可以考虑使用ClickHouse存储历史数据,在Mysql存储最近热点数据的方式,来优化和提升查询性能。ClickHouse的设计初衷就是为了解决大规模数据分析场景下的性能问题,特别是在处理OLAP(联机分析处理)任务时表现优异。
但是,通常不推荐直接使用Clickhouse作为数据库使用,虽然Clickhouse查询大数量时表现优秀,但其本身不支持事务,不具备Innodb锁等机制。Clickhouse其主要作用是优化海量数据的查询问题,所以结合Mysql做冷热数据分离的方式更推荐。海量的冷数据存储在Clickhouse中,最近的热点数据存储在Mysql中。
1、ClickHouse vs MySQL在大数据量场景下的对比
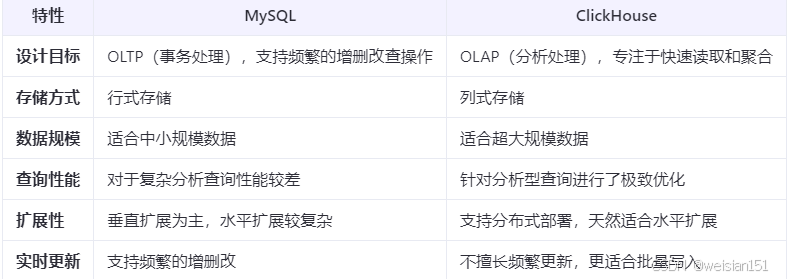
ClickHouse更适合处理海量数据的分析查询,而MySQL更擅长事务处理和频繁的数据修改。
2、具体思路
(1)、数据迁移
- 如果你的业务已经运行在MySQL上,但发现查询性能瓶颈,可以将部分数据迁移到ClickHouse中。
- 通常的做法是将需要频繁分析的历史数据或日志数据导入到ClickHouse,而MySQL继续负责事务处理。
- 迁移工具:
- 可以通过ETL工具(如Apache NiFi、DataX等)将数据从MySQL导出并导入到ClickHouse。
- 或者直接使用ClickHouse的INSERT INTO … SELECT …语句从MySQL中抽取数据。
(2)、数据分层架构
- MySQL作为主数据库:用于存储在线交易数据,支持高频的增删改操作。
- ClickHouse作为分析引擎:定期从MySQL同步数据,或者通过日志(如Binlog)实时订阅MySQL的变化数据,加载到ClickHouse中进行分析。
- 这种架构既能保证事务处理的灵活性,又能充分发挥ClickHouse在分析查询上的优势。
(3)、查询分离
- 将复杂的分析查询从MySQL转移到ClickHouse。例如:
- 如果你需要统计过去一年的用户行为数据,并按月进行汇总分析,这种查询可能会让MySQL不堪重负。
- 而在ClickHouse中,这类查询可以在秒级甚至毫秒级完成。
(4)、数据压缩与列式存储
- ClickHouse的列式存储和高效压缩算法能够显著减少存储空间占用,同时提高查询性能。
- 对于大规模数据集,存储成本和I/O开销往往是性能瓶颈的重要因素,ClickHouse在这方面具有明显优势。
3、具体案例
- 场景:电商网站的日志分析
- 问题:电商平台每天产生大量的用户访问日志和订单数据,存储在MySQL中。随着时间推移,数据量达到TB级别,查询变得越来越慢。
- 解决方案:
(1)、将历史日志数据从MySQL导出到ClickHouse。
(2)、在ClickHouse中创建表,并使用MergeTree引擎进行存储。
(3)、定期将MySQL中的增量数据同步到ClickHouse。
(4)、使用ClickHouse执行复杂的分析查询,例如:
sql示例:
SELECT toDate(event_time) AS event_date, COUNT(*) AS event_count
FROM user_logs
WHERE event_date BETWEEN '2025-01-01' AND '2025-01-31'
GROUP BY event_date;
这类查询在ClickHouse中通常只需几秒钟即可完成。
4、性能对比
场景:5000万条日志数据查询
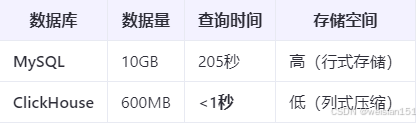
优化效果:
- 查询速度提升:200倍以上(从分钟级到秒级)。
- 存储成本降低:压缩率高达 17倍(10GB → 600MB)。
可以看到,相同的数据放到Mysql和ClickHouse中,占用的内存节省了90%多,查询的速度也是非常高效的。
5、注意事项
尽管ClickHouse在处理大数据量方面表现出色,但也需要注意以下几点:
(1)、不适合频繁更新:
- ClickHouse不擅长频繁的单行更新或删除操作。如果你的业务需要频繁修改数据,可能需要结合其他工具(如Kafka)来实现增量更新。
(2)、学习曲线:
- ClickHouse的功能和优化方式与传统的关系型数据库有很大不同,团队可能需要时间熟悉其特性和最佳实践。
(3)、数据一致性:
- ClickHouse本身不提供强一致性保证,因此在需要高一致性的场景下,仍需依赖MySQL或其他事务型数据库。
(4)、硬件需求:
- ClickHouse对硬件资源(尤其是内存和CPU)要求较高,尤其是在分布式部署时。
6、数据迁移步骤
(1)、数据迁移
步骤 1:定义历史数据范围
- 时间字段:确保 MySQL 表中存在时间字段(如 create_time 或 update_time),用于划分历史数据和近期数据。
- 迁移条件:例如,将三个月之前 create_time < ‘2025-01-12’ 的数据迁移到 ClickHouse。
步骤 2:迁移历史数据
-
工具选择:
- 全量迁移:使用 mysqldump或mydumper导出历史数据,通过clickhouse-client导入。
- 增量迁移(可选):使用 Canal、Debezium 或 TapData 实时捕获 MySQL 的 Binlog,过滤历史数据并同步到 ClickHouse。
-
迁移示例:
– 在 MySQL 中导出历史数据(示例)
mysqldump -u user -p --where="create_time < '2025-01-12'" dbname table_name > history_data.sql
– 转换为 CSV 格式(如通过脚本或工具)
– 导入到 ClickHouse
clickhouse-client --query="INSERT INTO clickhouse_table FORMAT CSV" < history_data.csv
步骤 3:清理MySQL中的历史数据
- 分区表优化:在 MySQL 中按时间分区,删除旧分区以释放空间(参考知识库[9])。
– 创建分区表(示例)
ALTER TABLE mysql_table
PARTITION BY RANGE (TO_DAYS(create_time)) (
PARTITION p2024 VALUES LESS THAN (TO_DAYS('2025-01-01')),
PARTITION p2025 VALUES LESS THAN (TO_DAYS('2026-01-01'))
);
– 删除旧分区
ALTER TABLE mysql_table DROP PARTITION p2024;
(2)、查询路由实现
方案 1:应用层路由
- 逻辑判断:在应用代码中根据时间条件决定查询 MySQL 或 ClickHouse。
python示例:
def query_data(start_time, end_time):
if end_time < '2025-01-12': // 三个月之前
查询 ClickHouse
return clickhouse_query(...)
elif start_time > '2025-01-12': // 三个月之内
查询 MySQL
return mysql_query(...)
else:
合并查询(如需跨时间范围)
return merge(mysql_query(...), clickhouse_query(...))
方案 2:中间件路由
- 使用代理工具:如 ProxySQL 或自定义 SQL 路由服务,根据查询条件动态转发请求。
- 示例规则:
- 若查询条件中 create_time < ‘2025-01-12’,则路由到 ClickHouse。
- 否则路由到 MySQL。
7、总结建议
当MySQL在大数据量场景下性能不足时,ClickHouse是一个非常优秀的解决方案,特别是在需要高性能分析查询的场景中。通过合理的数据分层架构和查询分离策略,可以充分利用ClickHouse的优势,同时保留MySQL在事务处理上的灵活性。
不过,ClickHouse并非万能药。它最适合的是只读或批量写入的大数据分析场景。在引入ClickHouse之前,建议充分评估业务需求,并制定清晰的数据迁移和查询优化策略。
逆风翻盘,Dare To Be!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









