







一、com
grep (global search regular expression(RE) and print out the line,全量搜索正则表达式并把行打印出来)
是一种文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。
Linux 系统中有很多很有名的搜索类命令,例如 find 命令、locate 命令、sed 命令,但还有三位兄弟是不得不提的,它们在搜索界的地位举足轻重,那就是 grep、egrep、fgrep 三兄弟。
为什么称它们为搜索三兄弟呢?大家看看下面的家谱就一目了然了。
grep
/
(选项) (-E) (-F)
/
egrep fgrep
从上面的关系图可以看出,egrep 和 fgrep 都可以通过 grep 加上不同选项来实现,真是“打断胳膊连着筋”,血脉相亲的一家人啊。它们三兄弟,各有特点,如表 1 所示。
| 命 令 | 是否支持正则 | 支持的正则类型 |
|---|---|---|
| grep | √ | 基本正则表达式 |
| egrep | √ | 扩展正则表达式 |
| fgrep | × |
http://c.biancheng.net/linux/grep.html
notice
二、grep的正则
1.grep的正则很迷,跟awk一样,反正不能用常规的正则。
比如在使用-E的情况下,\d用不了,只能[0-9]。
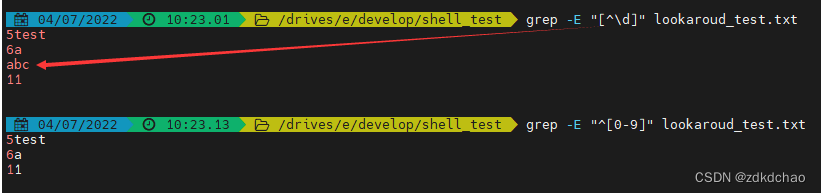
下面3种都不行

2.表达或者
{1}只有用-E的情况下,才能使用或者符号|。在这里插入图片描述
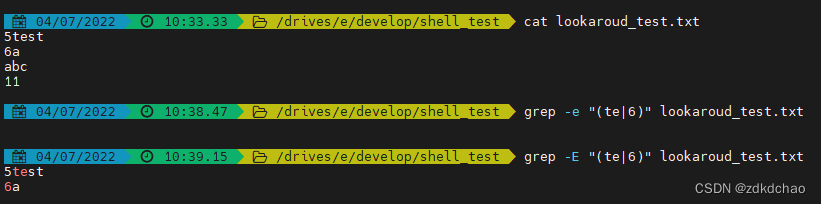
{2}或者用连续的-e,-E不能连续用,-v也不能连续用

3.表达并且。在表达并且的时候,文件名不能放在最后,只能在前面用cat
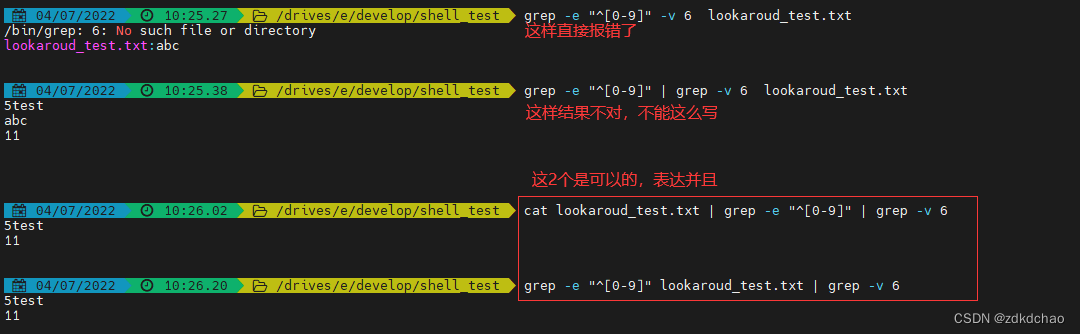
4.表达否
grep不支持在字符类中使用^作为否,所以表达否只能用-v
三、syntax
base
grep的FILE部分支持通配符
grep [OPTIONS] PATTERN [FILE…]
grep [OPTIONS] PATTERN PATTERN_FILE
OPTIONS
-e: 使用正则搜索
-i: 不区分大小写
-v: 查找不包含指定内容的行
-w: 按单词搜索
-c: 统计匹配到的次数
-n: 显示行号
-r: 逐层遍历目录查找
-A: 显示匹配行及前面多少行, 如: -A3, 则表示显示匹配行及前3行
-B: 显示匹配行及后面多少行, 如: -B3, 则表示显示匹配行及后3行
-C: 显示匹配行前后多少行, 如: -C3, 则表示显示批量行前后3行
–color: 匹配到的内容高亮显示
–include: 指定匹配的文件类型
–exclude: 过滤不需要匹配的文件类型
-s:不报no such file的错
四、常用正则
\ 反义字符:如"“”“表示匹配”"
^$ 开始和结束
[] 单个字符,[A]
[ - ] 匹配一个范围,[0-9a-zA-Z]匹配所有数字和字母
- 前面的字符出现0次或者多次
- 前面的字符出现了一次或者多次
. 任意字符
五、case
1. grep 命令最常用的场景就是筛选输出
[1]匹配和反向匹配
(1)grep ‘字符串’
这是最普通的使用方式:
匹配文件中包含 qwe的那一行:
cat manpath.config | grep 'qwe'
(2)grep -v ‘字符串’
与上例子相反,反向匹配
匹配文件中包含 qwe的那一行:
cat manpath.config | grep -v 'qwe'
[2]或、与
(1)grep -E | egrep :或
匹配 file.txt 中包含 word1 或 word2 或 word3 的行。
grep -E "word1|word2|word3" file.txt
ll | grep -E "word1|word2"
ll | grep -E -v "word1|word2"
egrep "word1|word2|word3" file.txt
(2) 与
使用管道符连接多个 grep ,间接实现多个关键字的与关系匹配:
必须同时满足三个条件(word1、word2和word3)才匹配。
grep word1 file.txt | grep word2 |grep word3
2. 统计文件中能够匹配的行数,注意是行数,不是匹配到的次数
涉及选项:
-c:计算匹配成功的行数
输出text.txt中含有hello字符串的行的数量:
grep -c "hello" text.txt
统计文件中pattern匹配的次数,注意是次数,不是行数
使用grep -o "xxx字符"按行显示出所有的匹配结果,然后再用grep -c “xxx字符” 或者 wc -l来计算行
统计某文本在整个文件中出现的次数
-o是出现一个就输出一行,可以方便的跟wc -l配合
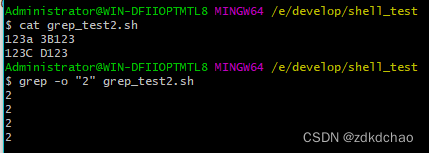
依据匹配次数进行查找
查找g至少出现5次的行
root@PC1:/home/test# cat a.txt
s d d
q e ggggg sdd
z a i ggggggg dddd
m x r
3 1 c ggggggggggggggggggggg xxx
7 3 n
root@PC1:/home/test# grep "g\{5,\}" a.txt
q e ggggg sdd
z a i ggggggg dddd
3 1 c ggggggggggggggggggggg xxx
4. 指定/排除文件
涉及选项:
(1)–include:指定需要搜索的文件
(2)–exclude:排除需要搜索的文件
(3)–exclude-dir:排除需要搜索的目录
例子:
(1)搜索src目录中下.c和.cpp文件中的含有main的行:
grep -r "main" ./src --include *.{c,cpp}
(2)搜索src目录中含有main的行,但不搜索readme文件:
grep -r "main" ./src --exclude "readme"
(3)搜索src目录中含有main的行,但不搜索.git文件夹:
grep -r "main" ./src --exclude-dir ".git"
5. 零值字节
涉及选项:
-Z:设定输出的文本之间以’\0’作为分隔符
注意如果不使用-Z选项,则输出的文件名之间以空格符分隔。那么如果有个文件的文件名本身就是包含空格的,则该文件会被认为是两个文件,就可能造成误删
例子:
(1)删除含有hello字符串的文件:
grep -r "hello" ./src -lZ | xargs -0 rm -f
6. 正则
hosts = `cat /etc/hosts | grep [zd][1-9] | awk '{print $1}'`
[zd]中[ ]表示里面的元素只取1个,[1-9]表示从1到9这9个数中匹配1个
7.递归查找
grep的 -R|-r 只能用于目录,且不能对目录下的文件进行进一步筛选
grep后的filename支持多个,filename可以使用*通配符,可以设置多级目录,比如/*/*/*.txt
如果又想递归,又想指定文件名,只能用find了
















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









