






前言
机器学习(Machine Learning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机系统对特定任务的性能,逐步进行改善的算法和统计模型。通过输入海量数据对模型进行训练,使模型掌握数据所蕴含的潜在规律,进而对新输入的数据进行准确的分类和预测。它是人工智能核心,是使计算机具有智能的根本途径。
机器学习分类
机器学习主要包括:监督学习,无监督学习及强化学习,神经网络与深度学习,集成学习 。机器学习的基础是监督学习与无监督学习,所以我们从基础开始。
监督学习
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
举个🌰:你的女朋友教你认识香水跟口红,她先告诉你香水跟口红分别有什么特征,然后拿出一堆香水跟口红,并且告诉你哪些是香水,哪些是口红。这样当你再一次看到香水跟口红时,你就能够辨认出来了。
监督学习的方法: 回归(Regression)、分类(Classification)
回归算法
回归问题是针对于连续型变量的。
举个🌰:预测房屋价格
假设想要预测房屋价格,绘制了下面这样的数据集。水平轴上,不同房屋的尺寸是平方英尺,在竖直轴上,是不同房子的价格,单位时(千万$)。给定数据,假设一个人有一栋房子,750平方英尺,他要卖掉这栋房子,想知道能卖多少钱。
这个时候,监督学习中的回归算法就能派上用场了,我们可以根据数据集来画直线或者二阶函数等来拟合数据。
 通过图像,我们可以看出直线拟合出来的150k,曲线拟合出来是200k,所以要不断训练学习,找到最合适的模型得到拟合数据(房价)。
通过图像,我们可以看出直线拟合出来的150k,曲线拟合出来是200k,所以要不断训练学习,找到最合适的模型得到拟合数据(房价)。
回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
分类算法
和回归最大的区别在于,分类是针对离散型的,输出的结果是有限的。
举个🌰:估计肿瘤性质
假设某人发现了一个乳腺瘤,在乳腺上有个z肿块,恶性瘤是危险的、有害的;良性瘤是无害的。如何预估该肿瘤的性质,是恶性的还是良性的。
那么分类就派上了用场,假设在数据集中,水平轴是瘤的尺寸,竖直轴是1或0,也可以是Y或N。在已知肿瘤样例中,恶性的标为1,良性的标为0。那么,如下,蓝色的样例便是良性的,红色的是恶性的。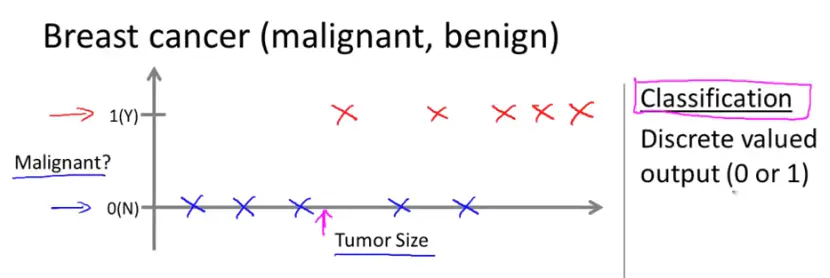
在这个例子中就是向模型输入人的各种数据的训练样本(这里是肿瘤的尺寸,当然现实生活里会用更多的数据,如年龄等),产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
举个🌰:你的女朋友拿出一堆香水跟口红,但是她不告诉你哪些是香水,哪些是口红,而且也不告诉你有什么特征,你只能靠自己对它们进行分类,这样当你再一次看到香水和口红时,你能够正确的分类。(不代表你知道什么是香水,什么是口红,仅仅代表你能够正确的把它们各自分到正确的类别中)
无监督学习有两个最常使用的场景,即聚类和降维。
聚类算法
简单来说聚类就是将一堆零散的数据根据某些标准分为几个类别,一般来说最常使用的标准是距离,距离也分为好几类,比如欧式距离(空间中两点的直线距离)、曼哈顿距离(城市街区距离)、马氏距离(数据的协方差距离)和夹角余弦。
举个🌰:Google新闻分类
Google新闻按照内容结构的不同分成财经,娱乐,体育等不同的标签,这就是无监督学习中的聚类。
如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,这样的算法就叫聚类算法。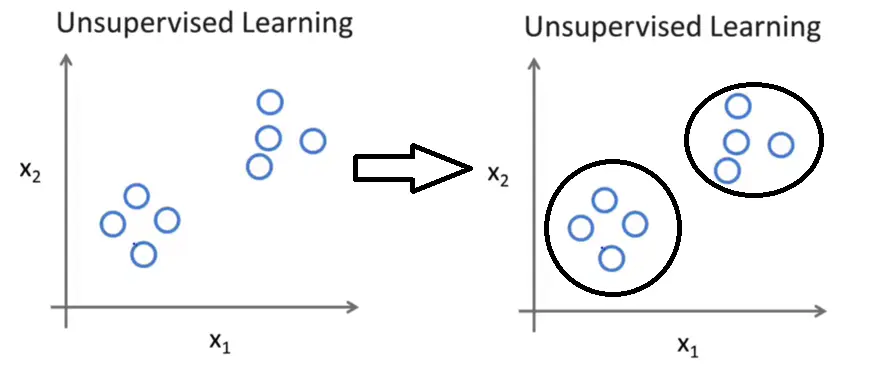
降维算法
降维指的是在保证数据所具有的代表性特性或者分布的情况下,将高维数据转化为低维数据的过程,这个过程包括数据的可视化和数据的精简。简单来说,我们拿到的一些数据存在很多字段,但是一些字段的数据对于结果是没有意义或者意义极小,但是在做机器学习的过程中也会参与计算,对我们最终分析结果造成不利影响,所以为了方便计算分析,要想办法将这部分字段去掉,这就是降维。
举个🌰:鸢尾花数据降维展示
将三类四维的鸢尾花数据,使用PCA对其进行降维,实现在二维平面上的可视化。
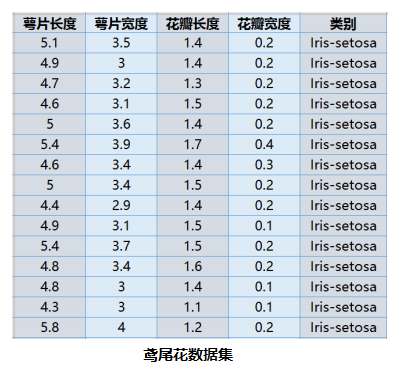 因为每个鸢尾花的特征数据有4个属性,我们想看这150点的分布情况没办法绘制图像。因此我们可以通过PCA降维,4维属性降为2维,就可以在二维平面上表示出来。
因为每个鸢尾花的特征数据有4个属性,我们想看这150点的分布情况没办法绘制图像。因此我们可以通过PCA降维,4维属性降为2维,就可以在二维平面上表示出来。
















 3758
3758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











