







ORM操作
字段类型
CharFeild varchar类型,需要指定最大长度
IntegerFeild 整型
DecimalFeild 浮点型,需要指定最大长度和小数点位数
DateFeild datetime类型,日期
ForeignKey
to 设置关联表
to_feild 关联表要关联的键名,默认为关联表中的id,可以不写
on_delete 级联等级
CASCADE 当关联表中数据删除的时候,外键所在表中的数据也会被删除
SET_NULL 当关联表中数据删除的时候,外键所在表中的外键设置为空
SET_DEFAULT 当关联表中数据删除的时候,为外键所在表中的外键设置一个默认值
PROTECT 关联保护,当关联表中数据被删除的时候,报异常
DO_NOTHING 当关联表中数据被删除的时候,外键所在的表不进行任何操作
字段属性
max_length 最大长度
verbose_name 备注,站点管理中用于改变字段名的显示
max_digits 浮点型最大长度
decimal_places 小数位数
auto_now 默认获取当前时间
null = True 可为空
源数据
db_table 修改表的名字
verbose_name 备注,站点管理中用于改变模型名的显示,会有s,复数
verbose_name_plural 复数名称
去掉复数s:
verbase_name=‘模型名’
verbose_name_plural=verbose_name
ordering=[’-age’,‘id’] 指定排序字段,加-降序
(一)单表操作
1.添加
-
save
# 第一种 person = Person(name='lisi',age=19,height=170,birthday='2019-08-01') person.save()# 第二种 person = Person() person.name = 'wangwu' person.age = 23 person.height = 185 person.birthday = '1998-03-01' person.save() -
create
# 第一种 Person.objects.create(name='hhh', age=10, height=190)# 第二种 data = dict(name='xxx',age=21,height=187) Person.objects.create(**data)
2.查询
-
all
返回一个queryset,存放对象
返回符合条件的所有数据
# 若重写了模块类的__str__方法,可直接输出 data = Person.objects.all() print(data)# 若没有需要使用这种方式 data = Person.objects.all() for one in data: print(one.id) print(one.name) print(one.age) print(one.height) -
get
返回的是一个对象
有且只能有一条,否则会报错
常使用主键作为条件
data = Person.objects.get(id=1) print(data.name) print(data.age) print(data.height) -
filter
返回一个queryset,存放对象
返回符合条件的所有数据
data = Person.objects.filter(name='wangwu') for one in data: print(one.age) -
first
返回一个对象
返回符合条件的第一条数据
data = Person.objects.filter(name='wangwu').first() print(data.id) print(data.name) print(data.age) print(data.height) -
last
返回一个对象
返回符合条件的最后一条
data = Person.objects.filter(name='wangwu').last() print(data.id) print(data.name) print(data.age) print(data.height) -
order_by
正–升序,负–降序
data = Person.objects.all().order_by('id') for one in data: print(one.id)data = Person.objects.all().order_by('-id') for one in data: print(one.id) -
exclude
返回一个queryset,包含跟给定条件不符合的所有数据
data = Person.objects.exclude(name='zs') for one in data: print(one.id) -
双下划线查询
# lt 小于 data = Person.objects.filter(id__lt=4) print(data) # lte 小于等于 data = Person.objects.filter(id__lte=4) print(data) # gt 大于 data = Person.objects.filter(id__gt=4) print(data) # gte 大于等于 data = Person.objects.filter(id__gte=4) print(data) # in 包含 data = Person.objects.filter(id__in = [1,2,3]) print(data) # range 范围,值域:前后都闭 data = Person.objects.filter(id__range=[1, 5]) print(data) # startswitch 像like j% data = Person.objects.filter(name__startswith='w') print(data) # endswitch 像like %j data = Person.objects.filter(name__endswith='u') print(data) # __contains 包含 大小写敏感 data = Person.objects.filter(name__contains='w') print(data) # __icontains 包含 大小写不敏感 data = Person.objects.filter(name__icontains='W') print(data) -
values
返回的是一个特殊的queryset
内容不是实例对象,而是具体数据的字典
data = Person.objects.filter(name="zhangsan").values() print (data) -
count
返回的是符合当前条件的数据的条数
data = Person.objects.filter(name="zhangsan").count() print (data) -
exists
返回一个True或False
判断是否存在
data = Person.objects.filter(name="libai").exists() print (data) -
切片
data = Person.objects.order_by("id")[2:5] print (data) -
reverse
对查询结果反向排序
这个方法通常放在有排序的查询集后面使用
排序:使用order_by或者模型类中的class Meta中使用odering = []
data = Person.objects.order_by('-id').reverse() print(data)
Queryset
查询集,不是python中的列表,也叫结果集,表示从数据库中获取的一个对象集合。
使用如下的方法时返回:
- all()
- filter()
- order_by()
- exclude()
- values() 特殊的
- 切片
特性:
- 惰性
- 创建好查询集之后不会立即执行,在使用的时候才会进行数据的查询。
- 缓存
- 使用一个查询集,第一次使用进行查询,然后将数据进行缓存,之后再使用该查询集不会再次发起查询,而是使用了缓存下来的数据。
使用如下方法返回对象:
- get()
- first()
- last()
3.修改
-
save
先查询到数据,然后进行重新赋值,然后执行save进行保存
data = Person.objects.get(id=2) data.name='dhdsd' data.save()data = Person.objects.filter(name='wangwu').all() for one in data: if one.id == 5: one.name='hjhs' one.save() -
update
Person.objects.filter(id=2).update(name='aaaa')
4.删除
-
delete
Person.objects.filter(id=9).delete()
(二)关系搭建之一对多
关系表

模型
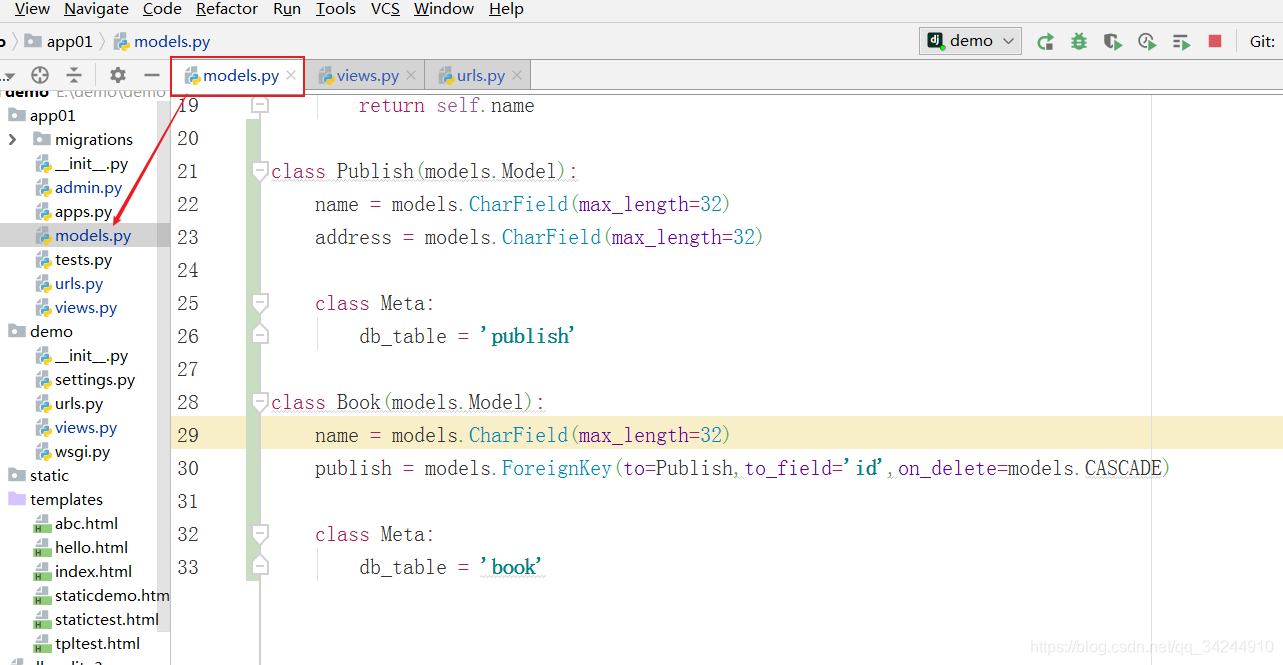
创建成的表
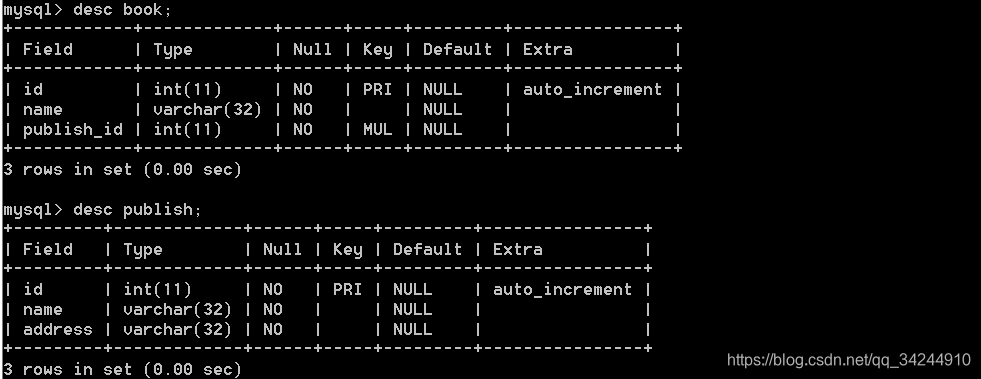
1.增加
Publish.objects.create(name='清华出版社',address='北京')
Publish.objects.create(name='中国出版社',address='北京朝阳')
Publish.objects.create(name='河南出版社',address='洛阳')
Book.objects.create(name='python入门',publish_id = 1)
-
第一种
publish = Publish.objects.get(name='中国出版社') Book.objects.create(name='java',publish_id=publish.id) -
第二种
Book.objects.create(name='python核心编程',publish=Publish.objects.get(name='中国出版社')) -
第三种
正向:从外键所在的表到关联表
book = Book() book.name='笨办法学python' book.publish = Publish.objects.get(name='河南出版社') book.save()反向:从关联表到外键所在的表
publish_obj = Publish.objects.get(name='中国出版社') publish_obj.book_set.create(name='pythonWeb开发')
2.查询
-
第一种
publish = Publish.objects.get(name='中国出版社') book = Book.objects.filter(publish_id=publish.id).all() for x in book: print(x.name) -
第二种
正向
book = Book.objects.filter(name='pythonWeb开发').first() print(book.name) print(book.publish) # publish对象 print(book.publish.name)反向
publish = Publish.objects.get(name='中国出版社') book = publish.book_set.all() for b in book: print(b.name)
3.更新
-
save
book = Book.objects.get(id=1) book.publish = Publish.objects.get(name='中国出版社') book.save() -
update
Book.objects.filter(name='java').update(publish = Publish.objects.get(name='清华出版社'))publish_obj = Publish.objects.get(name='清华出版社') Book.objects.filter(name='python核心编程').update(publish=publish_obj) -
set 反向
public = Publish.objects.get(name='河南出版社') book = Book.objects.get(id=4) book1 = Book.objects.get(id=3) public.book_set.set([book,book1])
4.删除
先删除外键所在的表,在删除关联表
Book.objects.get(id=2).delete()
Publish.objects.get(name='清华出版社').delete()
(三)关系搭建之多对多
关系表
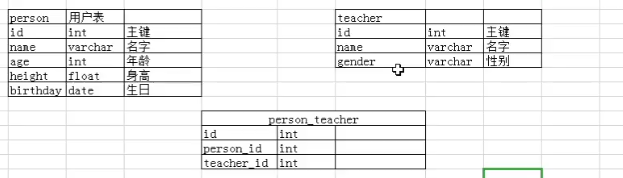
模型
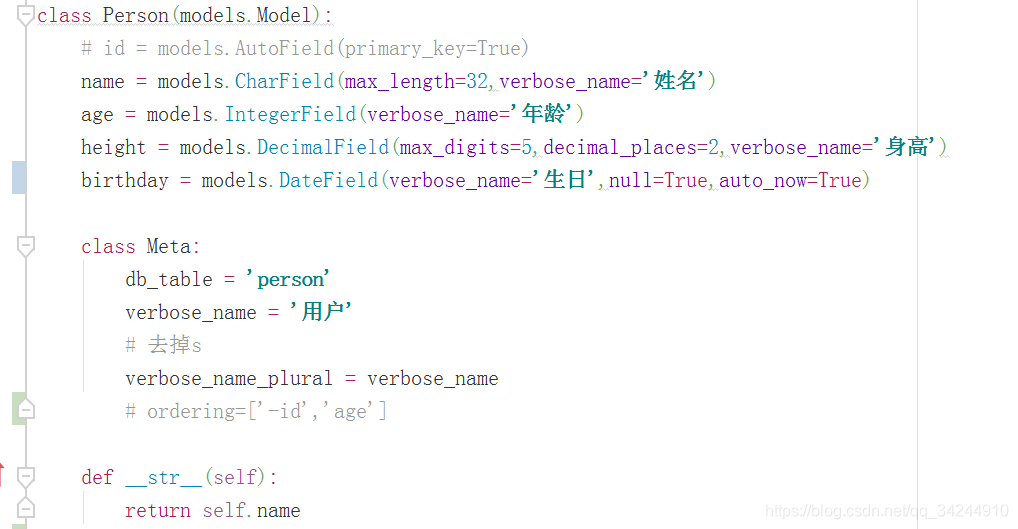


1.增加
Teacher.objects.create(name='laozhang',gender='女')
Teacher.objects.create(name='laobian',gender='男')
Teacher.objects.create(name='laoliu',gender='男')
Teacher.objects.create(name='laowang',gender='女')
-
增加新数据,并创建关系
teacher_obj = Teacher.objects.filter(name='laozhang').first() teacher_obj.person.create(name='秦秦',age=17,height=192) -
已存在的数据,创建关系
teacher_obj = Teacher.objects.filter(name='laowang').first() person_obj = Person.objects.filter(name='aaaa').first() teacher_obj.person.add(person_obj) -
反向
teacher_obj = Teacher.objects.filter(name='laoliu').first() person_obj = Person.objects.filter(name='秦秦').first() person_obj.teacher_set.add(teacher_obj)
2.查询
-
正向
teacher_obj = Teacher.objects.filter(name='laoliu').first() person = teacher_obj.person.all() print(person) -
反向
person_obj = Person.objects.filter(name='秦秦').first() teacher = person_obj.teacher_set.all().values() print(teacher)
3.更新
-
正向
根据id
teacher_obj = Teacher.objects.filter(name='laoliu').first() teacher_obj.person.set([1,2,3,4,5])放对象
teacher_obj = Teacher.objects.filter(name='laoliu').first() person1 = Person.objects.filter(name='wangwu').first() person2 = Person.objects.filter(name='hjhs').first() teacher_obj.person.set([person1,person2]) -
反向
根据id
person_obj = Person.objects.filter(name='lisi').first() person_obj.teacher_set.set([2])放对象
person_obj = Person.objects.filter(name='wangwu').first() teacher_obj = Teacher.objects.filter(name='laobian').first() person_obj.teacher_set.set([teacher_obj])
4.删除
-
remove
删除对象之间的关系
正向操作
person_obj = Person.objects.filter(name='秦秦').first() teacher_obj = Teacher.objects.filter(name='laozhang').first() teacher_obj.person.remove(person_obj)反向操作
person_obj = Person.objects.filter(name='zs').first() teacher_obj = Teacher.objects.filter(name='laoliu').first() person_obj.teacher_set.remove(teacher_obj) -
delete
删除对象数据,以及对象之间的关系
正向操作
Teacher.objects.filter(name='laoliu').first().delete()反向操作
Person.objects.filter(name='wangwu').first().delete()
(四)聚合查询–Avg、Sum、Max、Min、Count
通过aggregate()调用聚合函数。
aggregate():是一个queryset的方法。
意思是:返回一个包含数据的键值对的字典。
键名:聚合值的标识符号。
值:聚合函数的计算结果。
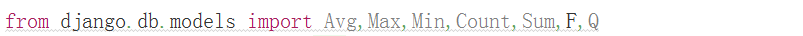
data = Person.objects.all().aggregate(Avg('age'))
print(data)
# 可设置键名,还可连用
data = Person.objects.all().aggregate(avg=Avg('age'),sum=Sum('age'))
print(data)
(五)F对象/Q对象
F对象:用于比较同一个模型中的两个字段的值。
data = Book.objects.filter(num__gt = F('salled')).all()
print(data)

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









