






datadf类型:list中包含若干个dataframe,由于每个dataframe都很大,现在需要把每个dataframe分别存储成一个csv方便读取
尝试1:
为了省内存,把每个DataFrame转换成str格式进行存储
file= open('./temp_diff/strline.csv', 'w')
for fp in datadf:
file.write(str(fp))
file.write('\n')
file.close()
打开strline.csv文件
尝试2:
list转换成数组,然后存成npy,报错memoryerror,可能是需要很大的内存

尝试3:
每个dataframe直接存为csv文件,由于DataFrame的数据类型默认为float,精度太高,所以存储时十分耗内存,速度也是十分慢
for i,df in enumerate(datadf):
df.to_csv("./temp_diff2/"+str(path[i])+".csv")

尝试4:
DataFrame中的数据只保留两位小数
for i,df in enumerate(datadf):
f=lambda x: '%.2f'%x ####(由于dataframe默认为float类型,存储时十分浪费内存,所以将其保留两位小数)
df=df.drop(["time"],axis=1)
t3=df.applymap(f)
t3.to_csv("./temp_diff2/"+str(path[i])+".csv")
 加载其中一个dataframe
加载其中一个dataframe
data=pd.read_csv("./temp_diff2/**.csv");data
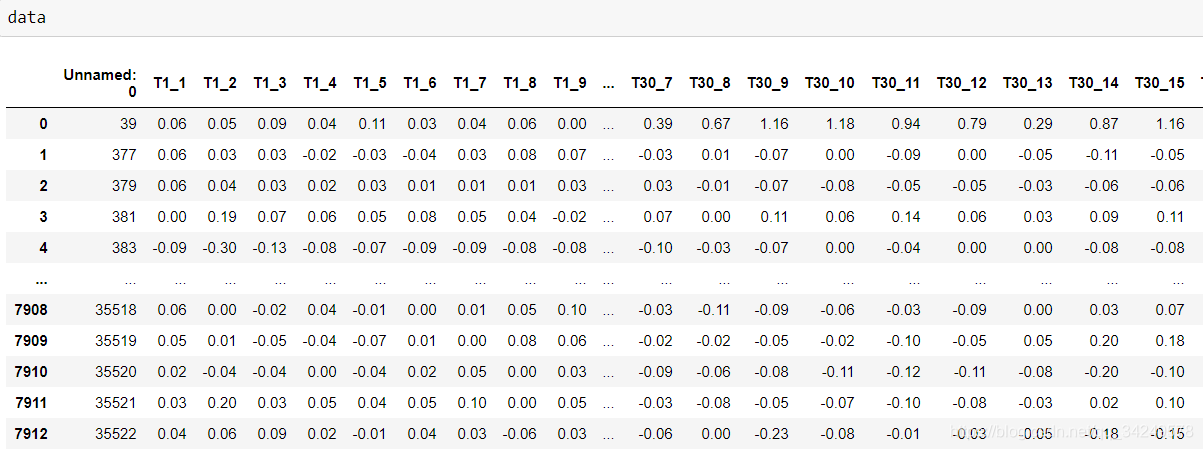
其中Unnamed:0 列为原先每个dataframe中的index,只需要 data.drop(["‘Unnamed: 0’"],axis=1),即可去除这一列














 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









