






1:ByteBuf是如何工作的
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。当你从 ByteBuf 读取时,它的 readerIndex 将会被递增已经被读取的字节数。同样地,当你写入 ByteBuf 时,它的writerIndex 也会被递增。
2:ByteBuf 的使用模式
2.1.堆缓冲区
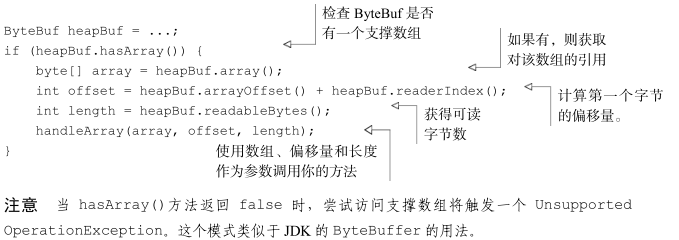
最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中。这种模式被称为支撑数组(backing array),它能在没有使用池化的情况下提供快速的分配和释放。
2.2.直接缓冲区
与使用支撑数组相比,这涉及的工作更多。因此,如果事先知道容器中的数据将会被作为数组来访问,你可能更愿意使用堆内存。
2.3.复合缓冲区
Netty 通过一个 ByteBuf 子类——CompositeByteBuf ——实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
3:字节级操作
ByteBuf 提供了许多超出基本读、写操作的方法用于修改它的数据。
- 随机访问索引
- 顺序访问索引
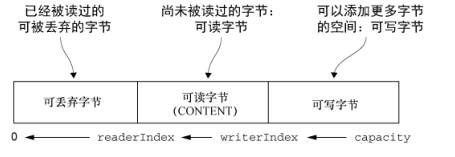
- 可丢弃字节
- 可读字节
- 可写字节
- 索引管理
- 查找操作
- 派生缓冲区
- 读/写操作
4:ByteBufHolder 接口
ByteBufHolder 也为 Netty 的高级特性提供了支持,如缓冲区池化,其中可以从池中借用 ByteBuf,并且在需要时自动释放

如果想要实现一个将其有效负载存储在 ByteBuf 中的消息对象,那么 ByteBufHolder 将是个不错的选择。
5:ByteBuf 分配
5.1 按需分配:ByteBufAllocator 接口
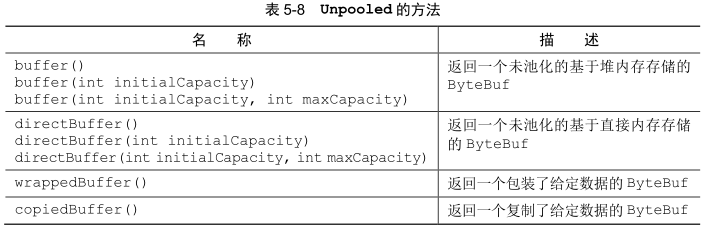
Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和Unpooled-ByteBufAllocator。前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。此实现使用了一种称为jemalloc的已被大量现代操作系统所采用的高效方法来分配内存。后者的实现不池化ByteBuf实例,并且在每次它被调用时都会返回一个新的实例。
5.2 Unpooled 缓冲区
5.3 ByteBufUtil 类
ByteBufUtil 提供了用于操作 ByteBuf 的静态的辅助方法。
hexdump()以十六进制的表示形式打印ByteBuf 的内容。
boolean equals(ByteBuf, ByteBuf)被用来判断两个 ByteBuf实例的相等性。















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









