







前言
上回,我们说到Linux内核中max()宏的终极奥义,Linux内核链表也不甘示弱,那么接下来,让我们看看Linux内核中的链表大招。
如何放出Linux内核中的链表大招
一、链表简介
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个节点的联系。按照指针域的组织以及各个节点之间的联系形式,链表又可以分为单链表、双链表、循环链表等多种类型,下面分别给出这几类常见链表类型的示意图:
(1)单链表
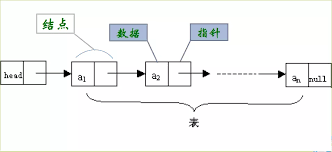
单链表(又名单向链表、线性链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过从头部开始,依序往下读取。
(2)双链表
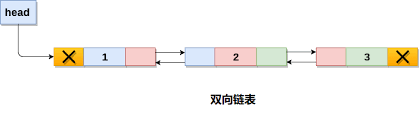
双链表,又称为双向链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
双链表设计前驱和后继两个指针域,双链表可以从两个方向遍历,这是它区别于单链表的地方。如果打乱前驱、后继的依赖关系,就可以构成"二叉树";如果再让首节点的前驱指向链表尾节点、尾节点的后继指向首节点,就构成了循环链表;如果设计更多的指针域,就可以构成各种复杂的树状数据结构。
(3)循环链表
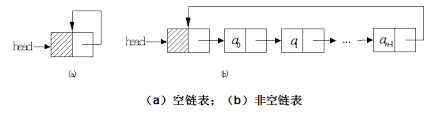
循环链表是一种链式存储结构,它的最后一个结点指向头结点,形成一个环。因此,从循环链表中的任何一个结点出发都能找到任何其他结点。
这里给出了双循环链表的示意图,它的特点是从任意一个节点出发,沿两个方向的任何一个,都能找到链表中的任意一个数据。如果去掉前驱指针,就是单循环链表。

在Linux内核中使用了大量的链表结构来组织数据,包括设备列表以及各种功能模块中的数据组织。这些链表大多被定义在/include/linux/list.h中,从而来实现各种较为复杂的数据结构。接下来,我们介绍一下在Linux内核中,链表的实现和操作。
二、Linux内核中的链表数据结构
1、内核链表的定义
在传统的数据结构课本中,链表的经典定义方式是这样的:
struct node{
ElemType data;
struct node *next;
};
因为ElemType的缘故,对每一种数据项类型都需要定义各自的链表结构,如果要用到大量不同类型的数据结构,就略显麻烦。
那么在Linux内核源代码中,链表是如何定义的呢?请看:
struct list_head {
struct list_head *next, *prev;
};
这就是内核中链表的定义方式,以版本3.18.43为例,它位于:
linux-3.18.43/include/linux/type.h
list_head结构包含两个指向list_head结构的指针prev和next,由此可见,内核的链表具备双链表功能,但其没有数据域。在Linux内核链表中,用链表组织的数据结构通常会包含一个struct list_head成员,例如:
struct mylist{
ElemType data;
struct list_head list;
};
这种通用的链表结构避免了为每个数据项类型定义自己链表的麻烦,也充分体现了Linux内核代码的智慧。
2、内核链表的使用
(1)声明和起始化
实际上Linux内核中只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看include/linux/list.h中的这个宏:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
其中,LIST_HEAD_INIT(name)宏表示仅初始化内核链表,LIST_HEAD(name)宏表示声明并初始化内核链表,用法举例:
struct mylist{
ElemType data;
struct list_head list;
};
struct mylist mylist_head;
LIST_HEAD(mylist_head);
上面代码表示申明并初始化自己的链表头mylist_head,此时mylist_head的next、prev指针都初始化为指向自己,这样就形成了一个内核空链表,那么如何判断链表是否为空呢?且看内核中的这个宏:
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
由此观之,Linux是用头指针的next是否指向自己来判断链表是否为空。
基本的list_empty()仅以头指针的next是否指向自己来判断链表是否为空,Linux链表另行提供了一个list_empty_careful()宏,它同时判断头指针的next和prev,仅当两者都指向自己时才返回真。这主要是为了应对多核cpu操作系统另外的cpu同时处理同一个链表而造成next、prev不一致的情况。但代码注释也有说明,这一安全保障能力有限,除非其他cpu的链表操作只有list_del_init(),否则仍然不能保证安全,也就是说,还是需要加锁保护,内核源码如下:
/**
* list_empty_careful - tests whether a list is empty and not being modified
* @head: the list to test
*
* Description:
* tests whether a list is empty _and_ checks that no other CPU might be
* in the process of modifying either member (next or prev)
*
* NOTE: using list_empty_careful() without synchronization
* can only be safe if the only activity that can happen
* to the list entry is list_del_init(). Eg. it cannot be used
* if another CPU could re-list_add() it.
*/
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
(2)插入链表
内核链表的插入操作有两种,让我们来分别分析一下。
第一种是list_add()函数,也就是我们常说的头插法,作用是插入到head之后,且看内核源码:
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
第二种是list_add_tail(),也就是我们常说的尾插法,作用是插入到head->prev之后,且看内核源码:
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
那么__list_add()函数又是何方神圣,且看内核源码:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
其实,list_add和list_add_tail的区别并不大,因为Linux链表是循环链表,且表头的next、prev分别指向链表中的第一个和最末一个节点,Linux分别用:
__list_add(new, head, head->next);
__list_add(new, head->prev, head);
就可以实现头插和尾插,用法举例:
list_add(&newnode1 -> list, &mylist_head.list);
list_add_tail(&newnode2 -> list, &mylist_head.list);
上面两行代码分别表示把新节点newnode1插入到mylist_head头结点的prev节点之后,把新节点newnode2插入到mylist_head头结点之后。
(3)删除链表
比较简单,直接上代码:
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
未完待续…















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









