







 读写分离是比较常见的应用场景,读库负责写入操作,多个从库通过binlog日志同步主库的写操作。读操作都落到读库上,写操作落到写库上;基本使用shardingjdbc 也支持读写分离的功能,同时也支持读操作的负载均衡算法;这里有3个数据源;db1 db2 db3db1 是写库。db2 和db3 是读库;每个库中都一个相同的表1. 首先配置3个数据源2. 配置那些库是写库,那些库是读库。这样配置表示写操作到source-0 读操作从source-1 和sour
读写分离是比较常见的应用场景,读库负责写入操作,多个从库通过binlog日志同步主库的写操作。读操作都落到读库上,写操作落到写库上;基本使用shardingjdbc 也支持读写分离的功能,同时也支持读操作的负载均衡算法;这里有3个数据源;db1 db2 db3db1 是写库。db2 和db3 是读库;每个库中都一个相同的表1. 首先配置3个数据源2. 配置那些库是写库,那些库是读库。这样配置表示写操作到source-0 读操作从source-1 和sour
读写分离是比较常见的应用场景,读库负责写入操作,多个从库通过binlog日志同步主库的写操作。读操作都落到读库上,写操作落到写库上;
基本使用
shardingjdbc 也支持读写分离的功能,同时也支持读操作的负载均衡算法;
这里有3个数据源;
db1 db2 db3
db1 是写库。db2 和db3 是读库;
每个库中都一个相同的表
![]()
1. 首先配置3个数据源
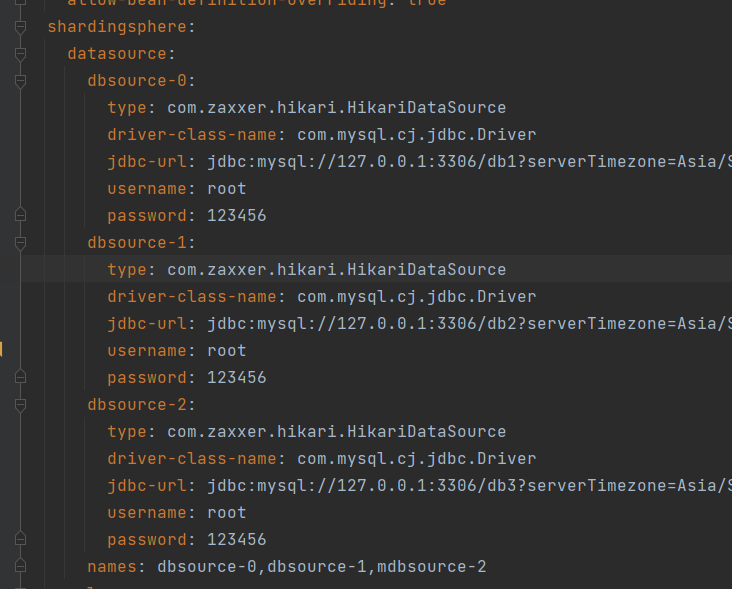
2. 配置那些库是写库,那些库是读库。
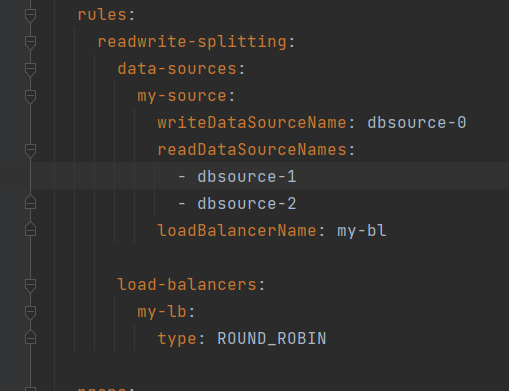
这样配置表示写操作到source-0 读操作从source-1 和source-2 使用轮询算法;
3. 验证
执行一个插入操作,通过sql能看到只插入到第一个数据源;
而执行查询操作则是从剩下的2个数据源中轮询执行;
4. 注意在配置数据分片的 actual-data-nodes 的时候的数据源名称就可以使用读写分离定义的名称
如上图的 my-source
具体配置可参考官网 (注意版本) :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









