







本篇将通过小例子的方式来一个一个的说明内置的分片算法;
内置多种分片算法以满足不同的业务场景;
自动分片算法
内置了一些常见场景的分片算法,只需要简单配置一些属性就可以实现分片
取模分片算法
顾名思义就是通过数据取模来分片,只需要指定分片算法类型和分片的数量,就会自动根据分片键的数据 % 分片的数量 完成分片
分片算法只需要指定类型,和配置一个几个分片的属性即可
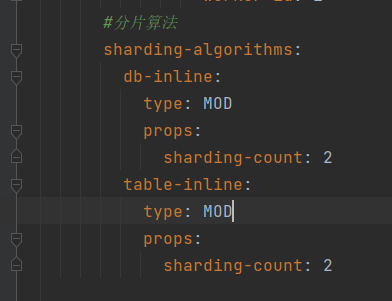
完整配置如下
spring:
application:
name: shardingjdbcDemo
main:
allow-bean-definition-overriding: true
shardingsphere:
#数据源信息
datasource:
#名称为dbsource-0的数据源
dbsource-0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
#名称为dbsource-1的数据源
dbsource-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db2?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
names: dbsource-0,dbsource-1
#规则的配置
rules:
sharding:
tables:
#配置表的规则
t_order:
actual-data-nodes: dbsource-$->{0..1}.t_order_$->{0..1}
#分库策略
database-strategy:
standard: # 用于单分片键的标准分片场景
sharding-column: user_id
sharding-algorithm-name: db-inline
#分表策略
table-strategy:
#标准策略
standard:
sharding-column: user_id
sharding-algorithm-name: table-inline
#分片算法
sharding-algorithms:
db-inline:
type: MOD
props:
sharding-count: 2 # 表示有2个分片库数量
table-inline:
type: MOD
props:
sharding-count: 2 # 表示有2个分片表数量
props:
sql-show: true
sql-comment-parse-enabled: true
哈希取模分片算法
说白了就是在取模算法的基础上加了一层 hash运算 然后再取模;
主要的特点是 可以针对非数值类型字段作为分片键;
如果分片键不是数值类型是不能取模的;这里假设order 表增加一个字符串的类型字段;
同时给数据库各个表增进此字段;
alter table t_order_0 add city varchar(20);
alter table t_order_1 add city varchar(20);这里用一个库来做演示,因为分库和分表的分片算法是一样的
假设需求同一个城市的数据落到一个库中;
配置信息
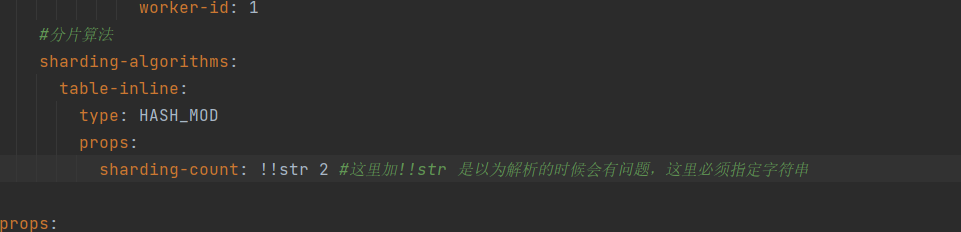
注意:sharding-count 后面的值需要强制指定为字符串 不然会报错,应该是有问题的;
@Test
void batchInsert(){
String[] citys = {"北京","上海","成都","石家庄","太原","广州","海口"};
for (int i = 0; i < 30; i++) {
Order order = new Order();
order.setUserId(Long.valueOf(i+""));
order.setOrderPrice(new BigDecimal("1"));
order.setCity(citys[i % citys.length]);
orderMapper.insert(order);
}
}这样就完成根据字符串的hash取模分片处理
完整配置如下
spring:
application:
name: shardingjdbcDemo
main:
allow-bean-definition-overriding: true
shardingsphere:
#数据源信息
datasource:
#名称为dbsource-0的数据源
dbsource-0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
names: dbsource-0
#规则的配置
rules:
sharding:
tables:
#配置表的规则
t_order:
actual-data-nodes: dbsource-0.t_order_$->{0..1}
#分表策略
table-strategy:
#标准策略
standard:
sharding-column: city
sharding-algorithm-name: table-inline
#分片算法
sharding-algorithms:
table-inline:
type: HASH_MOD
props:
sharding-count: !!str 2 #这里加!!str 是以为解析的时候会有问题,这里必须指定字符串
props:
sql-show: true
sql-comment-parse-enabled: true
基于分片容量的范围分片算法
根据数据的容量进行拆分;比如一个需求一个表中最多只让存10条数据,就可以使用这个分片算法,用来严格的控制每个表的容量;假设id 使用自增的id;根据数据id 来分片;
1. 设置id 类型为输入,后续会给它指定id @TableId(type = IdType.INPUT) private Long orderId;
2. 为了演示效果,准备6个数据表 从0 到 5
CREATE TABLE `t_order_5` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) DEFAULT NULL,
`order_price` decimal(10,2) DEFAULT NULL,
`city` varchar(20) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;3. 配置分片容量算法
修改了 actual-data-nodes 指定了6个表
指定了算法分片容量10 ,最小值是 1 最大值是 40

4. 插入50 条数据演示效果
@Test
void volumeR 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









