







概述
通过带入问题来搞明白为什么用要redis
预热
1、为什么文件查找内容比数据库查找要慢?
早期内容都存放在本文中,我们都是直接文本搜索,之后数据都放在数据库中大家都用数据库搜索,都说数据库查数据快,为什么呢?,带着疑问我们看下对比:这里核心词 全量
-
文件:一次要加载整个文件,没听说过打开一半搜索文件的吧。
-
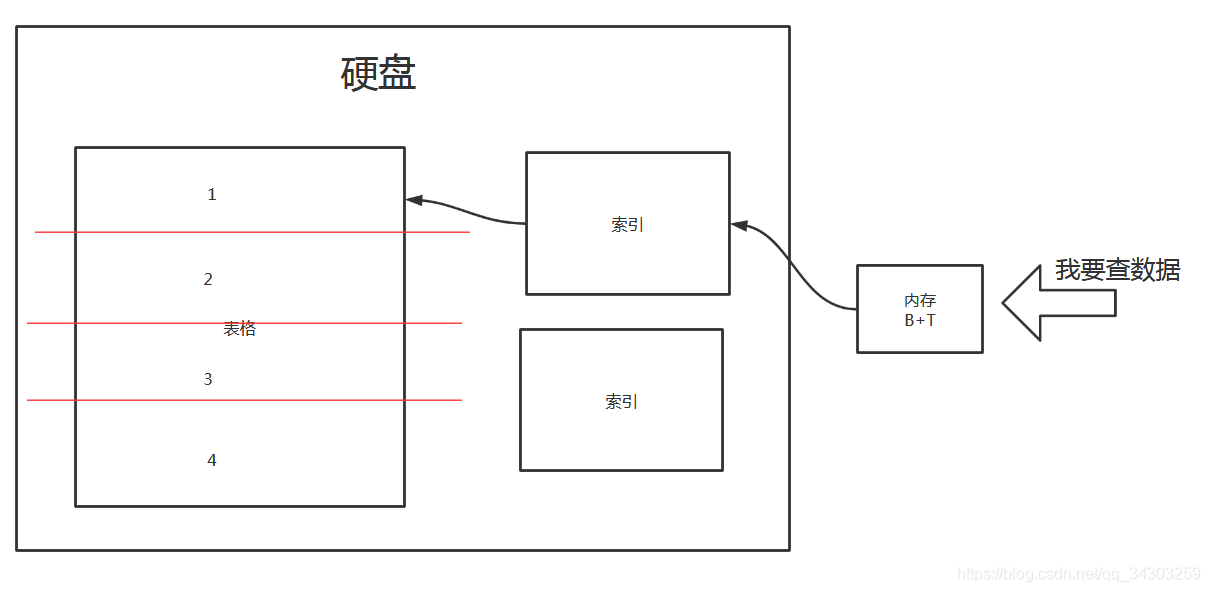
数据库:使用3连击,第1击:数据切块最小为4k,2连接索引读块,3连击内存建立B+T树。
举例:以下是数据库的查找路线,比较简陋大致能看懂哈
几个注意点:
- 以下查找速度可以在最少的数据中找到需要的数据,在10W数据中找数据肯定比在1000W数据中要快。
- 内存查找速度比硬盘快,内存的寻址ns级别,硬盘的寻址ms级别。
- 硬盘还受限于数据吞吐量。
问题2:既然内存查找速度比内存块,为什么不用全内存数据库呢?
有一个全内存关系型数据库,hana,有在用这个的,至于为什么用的少,之前有过一个报价,比较早了。
erp+hana+服务器+内存2T => 2亿人民币
为什么编译安装都是用make就可以安装各种应用?
make根据的是当前目录的makefile文件,makefile文件中是一系列的执行脚本。
拿到一套陌生的源码编译安装包怎么进行安装?
读下压缩包中的README,里面有build,runing等。
redis的问题探索
从常见的开始吧
单个redis存多少数据量比较合适?
redis单个数据量压缩到G级别,不要超过10G,节点越多数据量越少越好,不然一旦redis出现问题他会进行数据恢复很长时间,所以都是靠redis堆量。
连接池和线程池的区别?
用户建立连接会有一个socket,这个是连接池,我们说的work thread就是线程池,一个线程可以处理N个scket。
memcache和redis都是缓存数据库,为什么redis这么火?
我们用工具就是看好不好用,当然场景很重要,我们还是做下对比:
首先2个都是k,v类型的数据库;
memcache value只能是String,那我们现在的需求还是挺多的,简单举一个我存入一个[a,b,c,d],然后我只要取c,我要做的是value都get下来,然后转list,在取第3个元素。
redis的value可以是String,list,hash,set等,那我只要直接取在取第3个元素就行了,是不是很简单,好用才是王道。
redis是单线程的吗?
通过strace追踪redis故障的线程
strace -ff -o /tmp/redis.stracelog ./redis-server #-ff 抓取创建线程的操作
redis work是一个,但是有其他线程,细品。
redis为什么用单work线程,而nginx是多work线程,他们都用epoll?
原因在于数据需要一致性,redis存数据,nginx早期当做webserver是给人浏览静态页面的,后面作为负载均衡。
相关
linux 系统的select(多路复用):传给keinel 10W文件标识符,kelnel遍历10w文件标识符,传递和返回1次。
linux 系统的epoll:10w文件标识符存在cpu区域,通过划分epoll wait区域返回给应用,谁用传谁。
一个java连接会消耗1M的系统内存空间,线程堆不起啊。














 2315
2315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









