







一:文件类型
(1)普通文件
最常用的文件类型,这种文件包含了某种形式的数据。对于这种数据是文本还是二进制数据,对于unix内核而言并没有区别,普通文件内容的解释由处理该文件的应用程序来完成。对于可执行的二进制文件,内核必须理解他的格式,所有可执行的二进制文件都遵循一种标准化的格式。
(2)目录文件
这种文件包含了其他文件的名字以及指向与这些文件有关信息的指针。
对于目录文件的权限信息:r为可以读取该目录,w为可以修改这个目录,x为可以进入这个目录。
(3)块特殊文件
这种类型的文件提供对设备带缓冲的访问,每次访问以固定长度为单位进行。
(4)字符特殊文件
这种类型的文件提供对设备不带缓冲的访问,每次访问长度可以改变。
(5)FIFO
这种类型的文件用于进程之间的通信。
(6)socket
用于进程之间的网络通信,也可用于宿主机上的非网络通信。
(7)符号链接
这种类型的文件指向另一个文件,传说中的软链接吧。
demo:取命令行参数,然后针对每一个命令行参数打印其文件类型。
1 #include"apue.h"
2 int main(int argc,char *argv[])
3 {
4 int i;
5 struct stat buf;
6 char* ptr;
7 for(i = 1;i < argc;i++)
8 {
9 printf("%s:",argv[i]);
10 if(lstat(argv[i],&buf) < 0){
11 err_ret("lstat error\n");
12 continue;
13 }
14 if(S_ISREG(buf.st_mode))
15 ptr = "regular";
16 else if(S_ISDIR(buf.st_mode))
17 ptr = "directory";
18 else if(S_ISCHR(buf.st_mode))
19 ptr = "character special";
20 else if(S_ISBLK(buf.st_mode))
21 ptr = "block special";
22 else if(S_ISFIFO(buf.st_mode))
23 ptr = "fifo";
24 else if(S_ISLNK(buf.st_mode))
25 ptr = "symbolic link";
26 else if(S_ISSOCK(buf.st_mode))
27 ptr = "socket";
28 else
29 ptr = "Unknow";
30 printf("%s\n",ptr);
31 }
32 exit(0);
33 }
每个C语言程序都必须有一个称为main()的函数,作为程序启动的起点。当执行程序时,命令行参数(command-line argument)(由shell逐一解析)通过两个入参提供给main()函数。第一个参数int argc,表示命令行参数的个数。第二个参数char *argv[],是一个指向命令行参数的指针数组,每一参数又都是以空字符(null) 结尾的字符串。第一个字符串,亦即argv[0]指向的,(通常)是该程序的名称。argv中的指针列表以NULL指针结尾(即argv[argc]为NULL)。
argv[0]包含了调用程序的名称,可以利用这一特性玩个实用的小技巧。首先为同一程序创建多个链接(即名称不同),然后让该程序查看argv[0],并根据调用程序的名称来执行不同任务。gzip(1)、gunzip(1)和zcat(1)命令是该技术应用的一个例子,这些命令链接的都是同一可执行文件。(使用该技术,必须小心处理如下情况:用户通过链接调用程序,但链接名又在该程序的意料之外。)

转自https://www.cnblogs.com/rainbow70626/p/5595454.html
二:设置用户ID和设置组ID
实际用户ID和实际组ID说明我们实际是谁
有效用户ID和有效组ID、附属组ID用于文件访问权限检查
实际用户ID与 有效用户ID, 这两个ID在一般情况下是相同的,比如当前用户是andrew,那么它的实际用户ID是andrew,而有效用户ID也是andrew。可是在不一般的情况下那么这两个ID就可能不一样了,那么什么样的情况下是不一样的呢?那就是当一个用户要进行一个合理的特权的时候就需要啦,那么到底是怎么样的情况呢?
比如我们在linux系统中的passwd这个命令或者这个passwd这个程序,一个用户对自己进行修改密码是一种很正常的事情,可是保存密码的文件/etc/passwd却是root用户可写的这样的权利,那么也就是用如果你要修改密码,必须通过root用户帮你修改,这个事情的处理是这样的,让用户去运行passwd这个程序的时候,os给与root用户的权利,然后用户就可以修改自己的密码。具体的讲就是让用户去运行passwd这个程序的时候,unix将它的有效用户ID变成了拥有passwd的用户的ID,也就是root,所以就可以修改这个/etc/passwd这个文件。
保存设置用户ID(SUID): 是有效用户ID副本,既然有效用户ID是副本,那么它的作用肯定是为了以后恢复有效用户ID用的。。这个ID是用来保存有效ID的副本,让我们运行程序的过程其实就是os调用exec系列函数来调用我们程序的main函数,exec函数是kernel唯一执行程序的方法,或者那么讲不管什么用户程序的运行,其实也就是os的exec的调用过程。而exec在调用过程中会将这个程序的有效用户ID拷贝给保存用户ID。
文件的设置用户ID位: 这个东西应该是上面的关键所在,每一个文件都有一个文件模式字(st_mode),这个字可以通过看stat函数,而这个模式字包含了很多文件的属性,包括文件的类型,以及文件的访问权限的,当然设置用户ID位也在其中。通过设置这个位,就能当执行这个文件的时候,进程的有效ID设置为该文件本身的用户。这里的文件我可以把他认为是一些可运行的文件,或者就是可执行文件,而当运行这个文件的时候,进程会改变其有效用户ID,变成这些文件本身的ID。
转自http://www.voidcn.com/article/p-smsbogta-z.html
三:文件访问权限
重点是目录的访问权限啦,对于目录文件,读权限和执行权限是不同的,读权限允许我们读目录,获得在该目录中所有文件名的列表。而对目录的执行权限使我们可以进入这个目录。如果只有读权限没有执行权限的话,我们是不能进入到这个目录中的,如果只有执行权限而没有读权限的话,那么ls无法显示目录内容。

四:函数access与faccessat
这两个函数按实际用户ID和实际组ID进行访问权限测试的。
#include<unistd.h>
int access(const char* pathname,int mod);
int faccessat(int fd,const char* pathname,int mode,int flag);
demo:
1 #include"apue.h"
2 #include<fcntl.h>
3
4 int main(int argc,char* argv[])
5 {
6 if(argc != 2)
7 err_quit("usage: a.out <oathname>");
8 if(access(argv[1],R_OK) < 0)
9 err_ret("access error for %s",argv[1]);
10 else
11 printf("read access OK\n");
12 if(open(argv[1],O_RDONLY) < 0)
13 err_ret("open error for %s",argv[1]);
14 else
15 printf("open for reading OK\n");
16 }

五:函数umask
umask函数为进程设置文件模式创建屏蔽字
用于设定进程文件模式的掩码(又称屏蔽字),并返回之前的值。umask 值越大,权限越低。umask(1) 命令就是用这个函数封装的。
文件的访问允许权限共有9种,分别是:rwxrwxrwx
它们分别代表:用户读 用户写 用户执行 组读 组写 组执行 其它读 其它写 其它执行
1 #include"apue.h"
2 #include<fcntl.h>
3
4 #define RWRWRW (S_IRUSR|S_IWUSR|S_IWGRP|S_IROTH|S_IWOTH)
5
6 int main()
7 {
8 umask(0);
9 if(creat("foo",RWRWRW) < 0)
10 err_sys("creat error for foo");
11 umask(S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH);
12 if(creat("bar",RWRWRW) < 0)
13 err_sys("creat error for bar");
14 exit(0);
15 }
6:chown
chown(2) 函数族用来修改文件所有者。修改成功返回 0,修改失败返回 -1 并设置 errno
修改文件所有者这件事在 Linux 中只有超级用户能做
7:文件中的空洞
什么是空洞文件?
“在UNIX文件操作中,文件位移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都被设为 0。”
在Linux下,利用lseek人为的修改offset可以获得一个空洞文件。
空洞文件的表现:
空洞文件特点就是offset大于实际大小,也就是说一个文件的两头有数据而中间为空,以‘\0‘填充。
所以说,空洞文件在文件系统表现的还是和普通文件一样的,但是实际上文件系统并没有给他分配所表现出来的那么多空间,只是存放了有用的信息。
空洞文件有什么用?例如:迅雷下载文件时,在未下载完成时就已经占据了全部文件大小的空间,这时候就是空洞文件。下载的时候如果没有空洞文件,多线程下载时文件就都只能从一个地方写入,这就不是多线程了。如果有了空洞文件,可以从不同的地址写入,就完成了多线程的优势任务。
1 #include"apue.h"
2 #include<fcntl.h>
3
4 char buf1[] = "abcdefghij";
5 char buf2[] = "ABCDEFGHIJ";
6
7 int main()
8 {
9 int fd;
10 if((fd = creat("file.hole",FILE_MODE)) < 0)
11 {
12 err_sys("creat error");
13 }
14 if(write(fd,buf1,10) != 10)
15 err_sys("buf1 write error");
16 if(lseek(fd,16384,SEEK_SET) == -1)
17 err_sys("lseek error");
18 if(write(fd,buf2,10) != 10)
19 err_sys("buf2 write error");
20 exit(0);
21 }

将文件复制后,空的位置会被填0。


八:文件系统
这个就很重要啦!!!但是也很难理解。。。主要是绕来绕去的,apue讲的也不清楚,不知道是不是翻译的问题。。。
先说硬链接和软链接:
在Linux系统中,文件被分成两个部分,用户数据和元数据,用户数据块记录文件真实内容,元数据记录文件的附加属性,其中就有inode,inode包含了文件有关的所有信息:文件类型、文件访问位权限、文件长度和指向文件数据块的指针等,文件名和inode编号被存放在目录项中,不在inode里,其中一个inode可以指向多个数据块(也就是说,多个数据块共同组成了一个文件),一个文件对应一个inode。
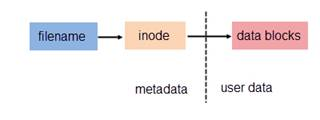
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接。
当多个目录项同时指向一个inode时,这种链接为硬链接。因为目录项的inode节点编号指向同一文件系统中的相应inode节点,一个目录项不能指向另一个文件系统的inode节点(不同的文件系统可能有相同的inode号,但这两个inode可能指向不同的文件),因此硬链接不能跨越文件系统。
此外,硬链接不能链接目录文件,为什么???(下面这段话别人写的,我插个眼)
如果引入了对目录的硬连接就有可能在目录中引入循环,那么在目录遍历的时候系统就会陷入无限循环当中。也许您会说,符号连接不也可以引入循环吗,那么为什么不限制目录的符号连接呢?原因就在于在linux系统中,每个文件(目录也是文件)都对应着一个inode结构,其中inode数据结构中包含了文件类型(目录,普通文件,符号连接文件等等)的信息,也就是说操作系统在遍历目录时可以判断出符号连接,既然可以判断出符号连接当然就可以采取一些措施来防范进入过大的循环了,系统在连续遇到8个符号连接后就停止遍历,这就是为什么对目录符号连接不会进入死循环的原因了。但是对于硬连接,由于操作系统中采用的数据结构和算法限制,目前是不能防范这种死循环的。
转自 : https://blog.csdn.net/TODD911/article/details/8756697

软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制。
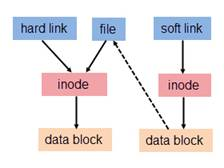
简单介绍完软链接和硬链接,再来讨论文件系统,以UFS为例,apue也只讲了UFS,其他的我不会。。。

data block:文件数据的逻辑存储块,每个块的大小是 4KB 的倍数。
inode table:存放着inode的数组,内部结构是这样的。。。
inode内部结构这幅鸟样。。。

包含 15 个磁盘块地址的数组,其中前 12 个地址是直接地址,它们直接指向 data block 的数据块。如果使用 12 个数据逻辑存储块无法容纳下一个文件,那么就会启用数组中第 13 个元素,它不直接指向数据块,而是指向一级间接块的。
一级间接块。包含 256 个磁盘块地址的数组,每个元素指向 data block 区域的一个数据逻辑存储块。如果依然无法容纳下一个文件,那么将启用 inode 中的第14个元素,它指向二级间接块。
二级间接块。包含 256 个磁盘块地址的数组,每个元素指向一个一级间接块数组。如果依然无法容纳下一个文件,那么将启用 inode 中的第15个元素,它指向三级间接块。
三级间接块。包含 256 个磁盘块地址的数组,每个元素指向一个二级间接块数组。
这回知道为什么 UFS 文件系统不惧怕大文件了吧?但是——UFS 文件系统不善于管理小文件,这是为什么呢?
答案其实很简单,因为文件系统中数据块的数量远比 inode 块多得多,所以一个 inode 块才能够对应多个 data block。而如果小文件太多,会导致在 data block 还有大量剩余空间的情况下就把 inode 耗尽了。















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









