







 本文深入探讨了深度学习中常见的梯度消失与梯度爆炸问题,并介绍了残差网络(ResNet)如何通过特殊的设计解决这一难题。文章详细解释了1x1卷积核的作用,残差单元的工作原理,以及如何在ResNet中实现维度变化。此外,还提供了构建ResNet-50模型的Python代码示例。
本文深入探讨了深度学习中常见的梯度消失与梯度爆炸问题,并介绍了残差网络(ResNet)如何通过特殊的设计解决这一难题。文章详细解释了1x1卷积核的作用,残差单元的工作原理,以及如何在ResNet中实现维度变化。此外,还提供了构建ResNet-50模型的Python代码示例。
【一】深度问题 - 梯度消失 & 梯度爆炸
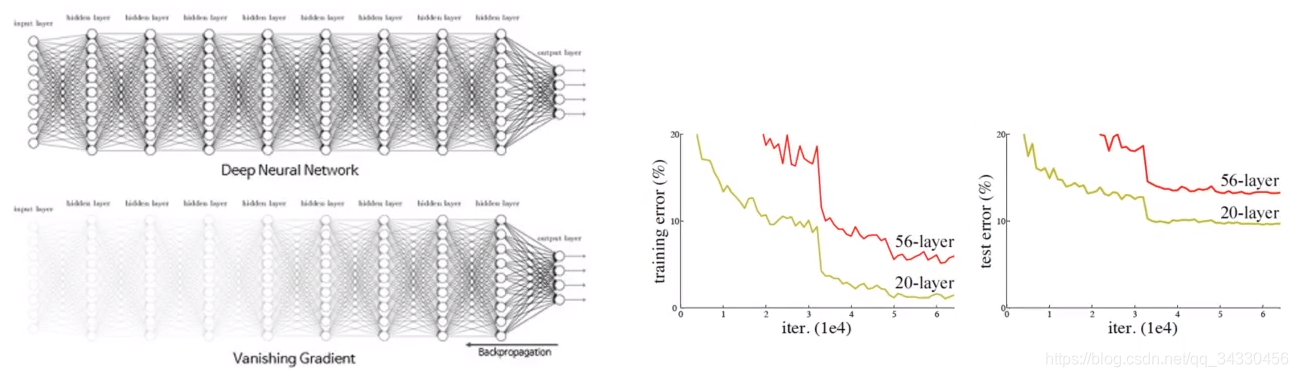
- BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为 w←w+Δw,给定 学习速率 α,得出 Δw = −α * ∂Loss / ∂w
- 根据 链式求导法则,更新梯度信息,∂fn / ∂fm 其实就是 对激活函数进行求导
- 当层数增加,∂fn / ∂fm < 1 → 梯度消失
- 当层数增加,∂fn / ∂fm > 1 → 梯度爆炸
【二】残差网络
- 在 统计学 中,残差的初始定义为:实际观测值 与 估计值 (拟合值) 的差值
- 在 神经网络 中,残差为 恒等映射 H(X) 与 跨层连接 X 的差值
- 残差元 结构图,两部分组成:恒等映射 H(X) + 跨层连接 X,使得前向传播过程为 线性,而非连乘
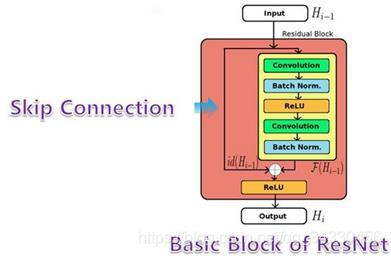
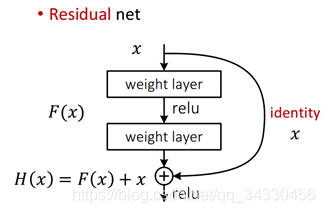
- 残差网络的 基本思路:在原神经网络结构基础上,添加 跨层跳转连接,形成 残差元 (identity block),即 H(X) = F(X) + X,包含了大量 浅层网络 的可能性
- 数学原理:在 反向传播 的过程中,链式求导 会从 连乘 变成 连加,即:(∂fn / ∂fm) * (1 + (∂fm / ∂fo)),可以有效解决 梯度消失 & 梯度爆炸 问题

【三】1X1 卷积核
- 改变图像纬度(通道):只作用于图像的通道数,在通道内进行全连接操作
- 不对图像的像素进行操作
- 大量减少卷积操作形成的参数的数量
- Identity Block 如下图(纬度不可变)
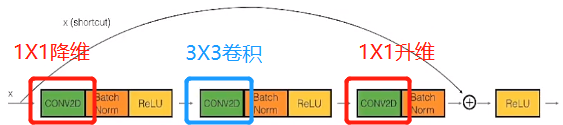
- 先进行 1X1 卷积,将图像纬度降低,减少参数,也就是减少了之后卷积的计算量
- 然后 3X3 卷积时,学习特征 速度加快
- 最后再进行 1X1 卷积,将图像纬度提升回来。因为在残差网络中,F(X) + X 相当于两个 tensor 相加,纬度需要一致
- Identity Block 代码
class identity_block(nn.Module):
def __init__(self, f, filters, stride=1, downsample= None):
super(identity_block, self).__init__()
# filters 为通道数:输入,第一层卷积,第二层卷积,第三层卷积
inc, outc1, outc2, outc3 = filters
# 第一层
self.conv1 = nn.Conv2d(inc, outc1, kernel_size=1, stride = 1)
self.bn1 = nn.BatchNorm2d(outc1)
# 第二层
self.conv2 = nn.Conv2d(outc1, outc2, kernel_size = f, stride = 1, bias= False)
self.bn2 = nn.BatchNorm2d(outc2)
# 第三层
self.conv3 = nn.Conv2d(outc2, outc3, kernel_size=1, stride = 1, bias=False)
self.bn3 = nn.BatchNorm2d(outc3)
# relu 非线性变换
self.relu = nn.ReLU(inplace = True)
self.stride= stride
self.f = f
def forward(self,x):
# 存储 x,后面需要用来相加
residual = x
# 第一层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层(含 padding,在图像 上 左 下 右 都加一层或多层的0)
out = self.conv2(out)
if self.f%2==0:
out = F.pad(out,(int(self.f/2), int(self.f/2-1) ,int(self.f/2), int(self.f/2 -1)))
else:
out = F.pad(out,(int((self.f-1)/2),int((self.f-1)/2),int((self.f-1)/2),int((self.f-1)/2)))
out = self.bn2(out)
out = self.relu(out)
# 第三层
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out)
return out
【四】Convolutional Block(纬度需要改变)
- Identity Block 部分并 没有改变 纬度的大小,而实际操作过程中是 需要改变 纬度的,增加通道数
- Convolutional Block 通过在跳转过程中添加 卷积模块 来改变纬度

- 代码 (eg. X = torch.randn (3,6,4,4),ConvolutionBlock (2,filters=[6,2,4,8]) )
- 变化 [3, 6, 4, 4] - [3, 2, 2, 2] - [3, 4, 2, 2] - [3, 8, 2, 2]
class ConvolutionBlock(nn.Module):
def __init__(self, f, filters , stride = 2, downsample= None):
super(ConvolutionBlock, self).__init__()
# defining bottom net
# Retrieve Filters
inc, outc1, outc2, outc3 = filters
# first layer, do 1x1 convolution
self.conv1 = nn.Conv2d(inc, outc1, kernel_size=1, stride=stride)
self.bn1 = nn.BatchNorm2d(outc1)
# second layer , f convolution
self.conv2 = nn.Conv2d(outc1, outc2, kernel_size=f, stride = 1, bias= False)
self.bn2 = nn.BatchNorm2d(outc2)
# convert back to original size, convolution
self.conv3 = nn.Conv2d(outc2, outc3, kernel_size=1, stride = 1, bias= False)
self.bn3 = nn.BatchNorm2d(outc3)
self.relu = nn.ReLU(inplace= True)
# create another pathway for x
self.conv4 = nn.Conv2d(inc, outc3, kernel_size=1, stride = stride)
self.bn4 = nn.BatchNorm2d(outc3)
self.stride= stride
self.f = f
def forward(self, x):
# 跳转层的卷积
residual = self.bn4(self.conv4(x))
# 第一层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层
out = self.conv2(out)
# padding 操作
if self.f%2==0:
out = F.pad(out,(int(self.f/2),int((self.f-1)/2),int(self.f/2),int((self.f-1)/2)))
else:
out = F.pad(out,(int((self.f-1)/2),int((self.f-1)/2),int((self.f-1)/2),int((self.f-1)/2)))
out = self.bn2(out)
out = self.relu(out)
# 第三层
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out)
return out
【五】ResNet
- 残差网络模型(ResNet-50 Model)

- 代码
class ResNet(nn.Module):
# BottleNeck 构建
def _make_layer(self, blocks, f, ch_in, ch, ch_out, stride = 1):
layers = []
layers.append(ConvolutionBlock(f, filters= [ch_in, ch, ch, ch_out], stride = stride))
for i in range(1, blocks):
layers.append(identity_block(f, filters= [ch_out, ch, ch, ch_out], stride = 1))
return nn.Sequential(*layers)
def __init__(self,input_shape, layers, stride, outputsize):
super(ResNet, self).__init__()
# stage1
l1, l2, l3, l4 = layers
s1, s2, s3, s4 = stride
self.conv1 = nn.Conv2d(input_shape[0], 64, kernel_size=7, stride = 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.mx1 = nn.MaxPool2d(kernel_size=3, stride = 2, padding = 1)
# stage2, convoulution block makes the image smaller size with more filters, identity block keeps the dimension
self.layer1 = self._make_layer(l1, 3, 64, 64, 256, stride = s1)
# stage3
self.layer2 = self._make_layer(l2, 3, 256, 128, 256*2, stride = s2)
# stage4
self.layer3 = self._make_layer(l3, 3, 256*2, 256, 256*4, stride = s3)
#stage5
self.layer4 = self._make_layer(l4, 3, 256*4, 256*2, 256*8, stride = s4)
#stage6
self.ax = nn.AvgPool2d(kernel_size=2, stride = 2)
# calculate output dimension by print it
self.fc = nn.Linear(2048 * input_shape[1]//(8*s1*s2*s3*s4) * input_shape[2]//(8*s1*s2*s3*s4), outputsize)
def forward(self, x):
x = F.pad(x,(3,3,3,3),value=0)
# assert (x.size()[1:] == (3,70,70))
x = self.conv1(x)
# assert (x.size()[1:] == (64,32,32))
x = self.bn1(x)
x = self.relu(x)
x = self.mx1(x)
# assert (x.size()[1:] == (64,16,16))
x = self.layer1(x)
# assert (x.size()[1:] == (256, 16, 16))
# print (x.size())
x = self.layer2(x)
# assert (x.size()[1:] == (512, 8, 8))
x = self.layer3(x)
# assert (x.size()[1:] == (1024, 4, 4))
x = self.layer4(x)
# assert (x.size()[1:] == (2048, 4, 4))
x = self.ax(x)
# assert (x.size()[1:] == (2048, 2, 2))
x = x.view(-1 , self.num_flat_features(x))
# assert (x.size()[1:] == (2048 *4,))
x = self.fc(x)
return x
def num_flat_features(self,x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
## 构建一个 resnet50 网路
net = ResNet(input_shape=[3,64,64], layers = [2,3,5,2], stride = [1,2,2,1], outputsize = 6)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









