







一、原因:
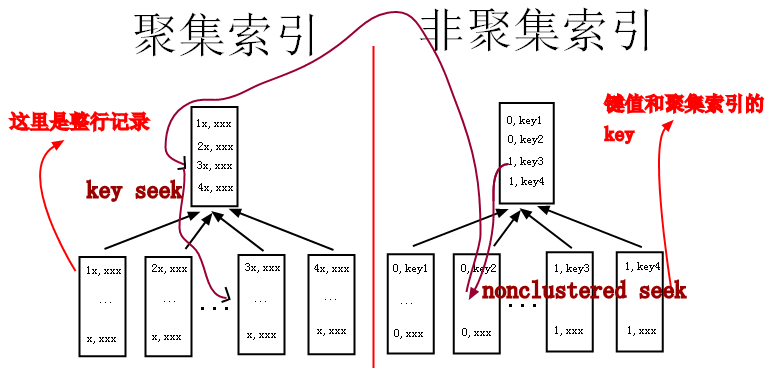
- 非聚簇索引存储了对主键的引用,如果 select 字段不在非聚簇索引内,就需要跳到主键索引。
- 如果非聚簇索引值重复率高,那么查询时就会大量出现上图中从右边跳到左边的情况,导致整个流程很慢
原因就是上面的。
数据库中聚集索引只有一个,默认主键。其他用户创建的索引都是非聚集索引。
非聚集索引存储了对主键的引用,即通过索引确定叶子节点之后,还需要再次根据主键去查询数据。(所以会查询两次)
如果非聚集索引重复率高(即一个同样的值有多个主键),那么首先你会从索引中取一半主键值,然后根据主键值再去查询数据,增加了IO,所以特别耗时。
大概就是上面的原因。
二、聚集索引和非聚集索引
2.1 区别:
主要可以参考高性能MySQL。这里简单总结一下
- 聚集索引把索引和数据存在了一起。
可以这么理解,聚集索引的叶子节点存储的是数据的指针(或者是数据本身)。具体暂时不确定,后续了解之后再确定。
- 非聚集索引(也叫二级索引)的叶子节点存储的是主键值(或叫做聚集索引值)
2.2 查询次数
非聚集索引需要两次查找,先从非聚集索引中找到主键值,然后再去聚集索引中找到具体数据。
聚集索引只需要查找本身。
2.3 为什么不适合在枚举少的字段上建立索引?
如果聚集索引唯一,那么条件只会确定几条值的主键,然后去聚集索引中查询还可以。
如果聚集索引重复,那么条件会确定近乎一般或者1/3或者1/5的主键值,然后再一个一个去聚集索引中查询,就会引起问题。
2.4 如果没有索引,数据库是怎么查询的?
全表扫描。
如果索引可以减少全表扫描,那么索引有效。如果索引导致了比全表扫描更糟糕的结果,那么还不如全表扫描。
三、参考
1. 为什么重复值高的字段不能建索引(比如性别字段等) - 扯 - 博客园
注:说的很精简。
2. 从性别字段不适合建索引说起 - Win32FanEx 的专栏 - CSDN 博客
注:详细讲解了实例,挺好的,便于理解。
3. 为什么状态少的字段不能建索引 - youzhouliu 的博客 - CSDN 博客
注:创建10W数据,亲自操作和分析,挺好的。
4. 聚集索引和非聚集索引(整理) - 布颜书 - 博客园
注:这个还需理解。如果不理解聚集索引和非聚集索引,就无法解决这个问题。
这篇教程特别好。















 2334
2334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}