







概述
1、AVRO是Apache提供的一套用于进行序列化(按照指定的格式将对象输出成二进制)和RPC机制
2、市面上常见的序列化框架:Google Protobuffer,Apache AVRO,Facebook thrift等 ,hadoop远程的序列化机制就是avro
什么是序列化
1、序列化:序列化就是将对象按照指定的格式(字节数组,json字符串)来进行转换
2、序列化的目的 : 便于数据的持久化以及传输
3、序列化框架好坏的衡量标准:
序列化出来的数据够小越好。——便于传输,便于存储
序列化机制的复杂程度越简单越好。——越复杂的机制,CPU内存占用得越多,而且花费的事件也就更多
序列化出来的数据应该具有语言无关性,平台无关性。—— 序列化出来的数据,不应该只能用某一种程序语言才能识别,也不能只有某种平台可以识别。
例如下图,很多项目都是跨语言的,如果序列化机制和语言相关,那么就无法传递数据了

选择什么作为序列化结果呢?
选择JSON字符串,字符在任何语言中都以一样的,只要码表相同。而JSON的格式可以很好的表示一个对象。
AVRO相关API操作
1、新建maven工程,导入avro依赖
查询maven常见依赖
2、在main目录下,新建avro文件夹,并且新建User.avsc文件
我们已经在pom配置文件中指定了avsc的文件地址以及生产的类的输出地址

文件中定义了需要进行json字符串转换的类的格式,需要根据avro提供的标准来进行定义
如下:
这个文件中定义的是我们要进行转换的类,定义转换规则
// 为AVRO指定输出的json格式
{
"namespace":"cn.tedu.serial", // namespace等价于Java中package
"type":"record", // record等价于Java中class
"name":"User", // class User{}
"fields":
[
{"name":"username","type":"string"}, // private String username;
{"name":"age","type":"int"}, // private int age;
{"name":"gender","type":"string"}, // private String gender
{"name":"height","type":"double"}, // private double height
{"name":"weight","type":"double"} // private double weight
]
}
3、编译maven工程,从而生成
这两个命令哪个都可以

编译完成之后,java目录下会自动生成一个类User.java,就是通过上面的配置文件写的。
4、编写序列化过程
创建待序列化对象
@Test
public void createObject() {
// 方式一:先创建后赋值
User u1 = new User();
u1.setUsername("Alex");
u1.setAge(19);
u1.setGender("male");
u1.setHeight(185.0);
u1.setWeight(65.8);
System.out.println(u1);
// 方式二:在创建的时候赋值
User u2 = new User("Lucy", 22, "female", 168.2, 49.8);
System.out.println(u2);
// 方式三:建造者模式
// 创建一个和u2相同属性但是名字不一样的对象
User u3 = User.newBuilder(u2).setUsername("Lily").build();
System.out.println(u3);
}
序列化过程:
@Test
public void serial() throws IOException {
// 创建对象
User u1 = new User("Amy", 15, "female", 153.8, 45.5);
User u2 = new User("Jack", 17, "male", 183.8, 64.5);
User u3 = new User("Helen", 16, "female", 168.8, 55.5);
// 创建序列化流,指定源对象的反射对象
DatumWriter<User> dw = new SpecificDatumWriter<>(User.class);
// 将序列化之后的数据写到文件中,需要创建一个文件流,文件流需要一个序列化作为参数
DataFileWriter<User> dfw = new DataFileWriter<>(dw);
// 指定文件 --- 第一个参数表示要按照avsc的格式来对数据整理,第二个参数是文件路径
// 等价的另外两种写法:
// dfw.create(User.getClassSchema(), new File("D:\\a.txt"));
// dfw.create(u1.getSchema(),new File("D:\\a.txt"));
dfw.create(User.SCHEMA$, new File("D:\\a.txt"));
//开始序列化
dfw.append(u1);
dfw.append(u2);
dfw.append(u3);
// 关流
dfw.close();
}
反序列化过程:
// 反序列化
@Test
public void deSerial() throws IOException {
// 创建反序列化流
DatumReader<User> dr = new SpecificDatumReader<>(User.class);
// 创建文件流来读取数据
// 路径和序列化流作为参数
DataFileReader<User> dfr = new DataFileReader<>(new File("D:\\a.txt"), dr);
// 读取对象,DataFileReader将读取过程封装成了迭代器来使用
while (dfr.hasNext()) {
User u = dfr.next();
System.out.println(u);
}
// 关流
dfr.close();
}
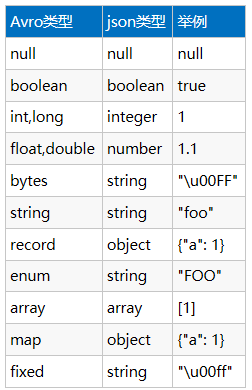
AVSC文件中的type属性
定义了avro按照什么类型进行序列化
最常用的就是record,相当于是一个类
有个映象即可:recored,Enums,Arrays,Maps,Fixed,Unions

而且Record类型中的field有默认值,如果对象中相应的地方没有提供值,会使用默认值,默认值和java不太一样。别有时候不明白为啥会不一样。Union的field默认值由Union定义中的第一个Schema决定。
当属性是引用类型时
此处有误,并不能怎么写,待更新
当属性的类型时一个引用类型时,应该讲属性的type修改为该引用类型的全路径类名。
并且这个类也应该同样的配置序列化。
配置文件应该是可以写在一起的















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









