







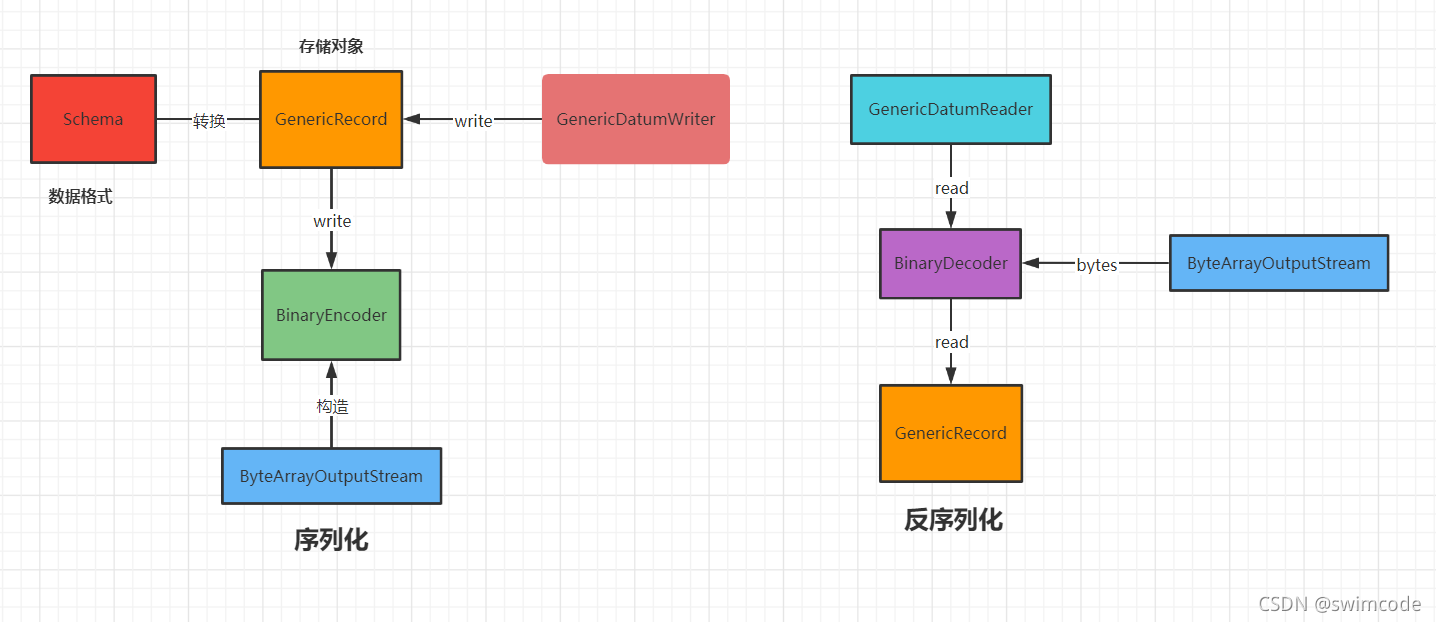
Apache Avro是一个数据序列化系统。序列化就是将对象转换成二进制流,
相应的反序列化就是将二进制流再转换成对应的对象。
因此,Avro就是用来在传输数据之前,将对象转换成二进制流,然后此二进制流达到目标地址后,Avro再将二进制流转换成对象。
Avro提供:
- 丰富的数据结构
- 一个紧凑的,快速的,二进制的数据格式
- 一个容器文件,来存储持久化数据
- 远程过程调用(RPC)
- 简单的动态语言集成。
- 代码生成不需要读写数据文件,也不要使用或实现RPC协议。代码生成是作为一个可选的优化,只对静态类型的语言值得实现。
.avro本质只是一种数据格式
scheme
Avro依赖于模式(Schema)。通过模式定义各种数据结构,只有确定了模式才能对数据进行解释,
所以在数据的序列化和反序列化之前,必须先确定模式的结构。
Avro作为RPC框架来使用。客户端希望同服务器端交互时,就需要交换双方通信的协议,它类似于模式,
需要双方来定义,在Avro中被称为消息(Message)。
通信双方都必须保持这种协议,以便于解析从对方发送过来的数据,这也就是传说中的握手阶段。
简单数据类型
null、boolean、int、long、float、double、bytes、string
| 类型名 | 描述 | 描述 | 二进制编码(Binary Encoding) | 排序(Sort Order) |
|---|---|---|---|---|
| null | 空 | no value | 0字节(zero bytes) | 总是相等 |
| boolean | 布尔值(0或1) | a binary value | 1字节,值是0(false)或者1(true) | false在前,true在后 |
| int | 32位有符号整数 | 32-bit signed integer | 使用可变长度编码(variable-length)、zig-zag编码 | 按数值升序排列 |
| long | 64位有符号整数 | 64-bit signed integer | 使用可变长度编码(variable-length)、zig-zag编码 | 按数值升序排列 |
| float | 单精度(32位)的IEEE 754浮点数 | single precision (32-bit) IEEE 754 | ||
| floating-point number | 4字节,float浮点数会被转换成32位的整数, | |||
| 等价于 Java’s floatToIntBits | 按数值升序排列 | |||
| double | 双精度(64位)的IEEE 754浮点数 | double precision (64-bit) IEEE 754 | ||
| floating-point number | 8字节,double浮点数会被转换成64位的整数, | |||
| 等价于 Java’s doubleToLongBits | 按数值升序排列 | |||
| bytes | 8位无符号字节序列 | sequence of 8-bit unsigned bytes | 编码成long类型,后面跟着很多字节的数据。 | 按字典顺序通过无符号8位值进行比较。 |
| string | 字符串 | unicode character sequence | 编码成long类型,后面跟着很多字节的UTF-8编码的字符数据。 | 按字典顺序由Unicode代码点进行比较。由于UTF-8用作字符串的二进制编码,因此字节和字符串二进制数据的排序是相同的。 |
| 型名 | 描述 | 样例 | 二进制编码(Binary Encoding) | 排序(Sort Order) |
|---|---|---|---|---|
| Records | 记录 | { “type”: “record”, “name”: “LongList”, “aliases”: [“LinkedLongs”],// old name for this “fields” : [ {“name”: “value”, “type”: “long”},// each element has a long {“name”: “next”, “type”: [“null”, “LongList”]}// optional next element ]} | 记录通过模式里面声明的字段顺序编码,换句话说,记录被编码成它的字段编码的连接。字段值按它的模式编码。 | 记录数据按字段的字典顺序排序。 如果字段指定其顺序为:“升序”,然后其值的顺序不变。“降序”,然后其值的顺序颠倒过来。“忽略”,然后在排序时忽略其值。 |
| Enums | 枚举 | { “type”: “enum”, “name”: “Suit”, “symbols” : [“SPADES”, “HEARTS”, “DIAMONDS”, “CLUBS”]} | 枚举由int编码,表示模式中符号从零开始的位置。 | 按符号在枚举模式中的位置排序 |
| Arrays | 数组 | {“type”: “array”, “items”: “string”} | 数组被编码为一系列块(block)。 每个块包含一个长整数的计数,后跟许多数组项。计数为零的块表示数组的结束。每个元素都按照数组的模式进行编码。 | 按字典顺序进行元素比较。 |
| Maps | 映射(字典) | {“type”: “map”, “values”: “long”} | 映射被编码为一系列块(block)。每个块由一个长整数的计数,后跟许多键/值对。计数为零的块表示映射的结束。每个元素都按照映射的模式进行编码。 | 无法比较。 |
| Unions | 联合类型 | 即值可以是类型列表中的一种类型[“null”, “string”]表示模式可以是null或者string | 通过首先写入一个long值来编码union,该值指示其值的模式的并集内的从零开始的位置。 然后根据联合中指示的模式对该值进行编码。 | union数据首先由union中的分支排序,并且在其中由分支的类型排序。 例如,[“int”,“string”] union将在所有字符串值之前对所有int值进行排序,其中int和字符串本身按上面的定义排序。 |
| Fixed | 固定大小 | {“type”: “fixed”, “size”: 16, “name”: “md5”} | 使用模式中声明的字节数对固定实例进行编码。 | 按字典顺序通过无符号8位值进行比较。 |
序列化/反序列化
Avro指定两种数据序列化编码方式:binary encoding 和Json encoding。
使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。
编码(Encodings):
Avro指定了两种序列化编码:二进制和JSON。 大多数应用程序将使用二进制编码,因为它更小更快。
但是,对于调试和基于Web的应用程序,JSON编码有时可能是合适的。
Demo
1、直接将字符串转为二进制流
//直接将字符串转为二进制流
String s = JSONObject.toJSONString(hashMap);
System.out.println(s);
BinaryEncoder binaryEncoder = EncoderFactory.get().binaryEncoder(byteArrayOutputStream, null);
binaryEncoder.writeString(s);
binaryEncoder.flush();
2、二进制编码与JOSN编码
/**
* 二进制序列化
*
* @param t AVRO生成的对象
* @param <T> AVRO类型
* @return
*/
public static <T> byte[] binarySerializable(T t) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
BinaryEncoder binaryEncoder = EncoderFactory.get().binaryEncoder(out, null);
DatumWriter<T> writer = new SpecificDatumWriter<T>((Class<T>) t.getClass());
try {
writer.write(t, binaryEncoder);
binaryEncoder.flush();
out.flush();
} catch (IOException e) {
log.error("binarySerializable error");
e.printStackTrace();
}
log.debug("ByteArrayOutputStream = {}",new String(out.toByteArray()));
return out.toByteArray();
}
/**
* 二进制反序列化
*
* @param bytes
* @param tClass
* @param <T>
* @return
*/
public static <T> T binaryDeserialize(byte[] bytes, Class<T> tClass) {
try {
BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(bytes, null);
DatumReader<T> datumReader = new SpecificDatumReader<T>(tClass);
T read = datumReader.read(null, binaryDecoder);
return read;
} catch (IOException e) {
log.error("binaryDeserialize error");
e.printStackTrace();
}
return null;
}
/**
* 二进制反序列化
*
* @param bytes
* @param schema
* @param <T>
* @return
*/
public static <T> T binaryDeserialize(byte[] bytes, Schema schema) {
try {
BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(bytes, null);
DatumReader<T> datumReader = new SpecificDatumReader<T>(schema);
T read = datumReader.read(null, binaryDecoder);
return read;
} catch (IOException e) {
log.error("binaryDeserialize error");
e.printStackTrace();
}
return null;
}
/**
* json序列化
*
* @param t
* @param <T>
* @return
*/
public static <T> byte[] jsonSerializable(T t, Schema schema) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
Encoder jsonEncoder = EncoderFactory.get().jsonEncoder(schema, out);
DatumWriter<T> writer = new SpecificDatumWriter<T>(schema);
writer.write(t, jsonEncoder);
jsonEncoder.flush();
out.flush();
} catch (IOException e) {
log.error("jsonSerializable error");
e.printStackTrace();
}
log.info("json序列化的String为 = {}", new String(out.toByteArray()));
return out.toByteArray();
}
/**
* json反序列化
*
* @param schema
* @param byteArrayInputStream
* @param <T>
* @return
*/
public static <T> T jsonDeserialize(Schema schema, ByteArrayInputStream byteArrayInputStream) {
try {
Decoder jsonDecoder = DecoderFactory.get().jsonDecoder(schema, byteArrayInputStream);
DatumReader<T> datumReader = new SpecificDatumReader<T>(schema);
T read = datumReader.read(null, jsonDecoder);
return read;
} catch (Exception e) {
log.error("jsonDeserialize error");
e.printStackTrace();
}
return null;
}

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









