









数据本地化策略
把计算发到离数据近的地方,移动计算不移动数据
1、实际过程中,Split大小 = Block大小/n,意味着Split的大小往往是Block大小的某个因子,例如Block是128M,Split是64M,n等于2,这么设置的目的是为了减少每一个MapTask所读取的次数 ,一般Split和Block大小相等
2、数据本地话策略:两个方面
① 为了减少跨集群的传输,往往是将DataNode和TaskTracker部署在相同的节点上,即意味着一个节点既是DataNode也是TaskTacker 【反正一个用存储,一个用内存和CPU,不冲突】
②为了减少节点之间的数据传输,JobTracker分配任务的时候,会尽量的将任务分配到有任务处理的对应数据的节点上
当提交任务时,将Job提交给JobTracker,然后JobTacker作为客户端向HDFS中的NameNode发起请求,获取待处理文件文件的元数据。NameNode返回文件信息之后,JobTacker可以计算出来需要划分多少个Split;根据split数量计算需要多少个mapTask以及reduceTask,然后任务分配的相应的节点上去。

数据切片split过程分析
相关结论
1、如果文件为空,即文件大小是0B,将整个文件作为一个切片来处理
2、在MapReduce中,文件分为可切和不可切。这里是指逻辑上可不可以切分。例如绝大部分的压缩文件都是不可切的 【不同的压缩规则不一样,随便切了交给不同的mapTask进行处理,切错了就不能解压缩了】
3、如果文件不可切(不能逻辑切分),那么将整个文件作为一个切片来进行处理
4、默认情况下,Split大小和Block大小是一致的
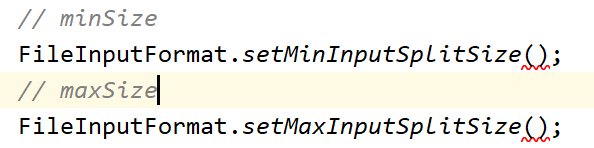
5、如果需要调大SplitSize,那么调大minSize(调下限);如果需要调小SplitSize,那么需要调小maxSize(调上限)

默认情况下,minSize = 1,而maxSize = 21亿(Long.max_value),所以先在最大和blocksize之间去最小值,就是blocksize,然后又在blocksize和minsize之间取最大值,结果就是blocksize了,所以才说默认情况下split的大小和分区的大小是一样的。
切片的大小设置
在Driver中进行设置,单位是字节
6、切片的过程中,有一个切片阈值,不是说一定按照128M切,最后不足128M的成为一个切片。而是切片阈值是1.1,只有待切长度/切片长度大于1.1的时候才会进行切片。切片阈值默认1.1,即剩余字节个数/splitSize>1.1的时候才会计算切片;如果剩余字节个数/splitSize<=1.1,那么剩余的字节个数整体作为1个切片处理 (切片大小可能回到大于splitSize的,最后一个)
切片过程的源码分析
FileInputFormat实现了对文件进行切片的逻辑。
//返回值是一个切片列表
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();//对切片过程的一个计时,后面对应了一个sw.stop(),可以不管
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//getFormatMinSplitSize()返回值是1,默认的切片下限
//getMinSplitSize(job):通过job设置的下限,默认也是1,取两个值的较大值
long maxSize = getMaxSplitSize(job);
//通过job取切片上限,没有设置的话就是Long.MAX_VALUE
// generate splits-开始切片,通过一个ArrayList返回切片信息
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);//获取输入的文件列表
for (FileStatus file: files) {//遍历文件列表进行判断
Path path = file.getPath();//获取文件的路径
long length = file.getLen(); //获取文件的长度大小
if (length != 0) {//如果长度不是0的话,不是空文件继续处理
BlockLocation[] blkLocations;//声明一个block位置数组
if (file instanceof LocatedFileStatus) {//当前的file是不是一个本地文件,其实就是判断是还不是单机模式,因为单机模式没有HDFS,所以单机模式的blk获取和集群模式的不一样,这里单独列出来
blkLocations = ((LocatedFileStatus) file).getBlockLocations();//是本地文件时的处理
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());//是一个hdfs上的文件时,连接到HDFS,获得一个FileSystem文件系统对象
blkLocations = fs.getFileBlockLocations(file, 0, length);//从文件系统上获取整个文件的所有block块信息
}
if (isSplitable(job, path)) { //判断文件是否可切分,可切时返回true
long blockSize = file.getBlockSize(); //获取文件的block块大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);//计算分配大小。先min,后max,不做特殊设置的话splitSize等于blocksize,也就是128m
long bytesRemaining = length;// 待切片长度等于整个文件的字节数
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { // 当待切字节/split字节数大于1.1时进行循环切片
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);//length-bytesRemaining 未切分字节的起始位置,根据这个位置找到block的index
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));//向list中添加分片,对inputsplit进行了封装,大概应该是分片的偏移量,在哪个主机上之类的
bytesRemaining -= splitSize;//待切的减去一个切片的长度,剩下的就是新的还没有切的字节长度
}
if (bytesRemaining != 0) { //低于切片阈值1.1后,判断剩余字节数是不是0,不是0时,同样作为一个切片添加
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable 判断不可切返回false的时候
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts())); //整体上作为一个切片,位置就放第一个block块的地址
}
} else { //如果当前file是一个空文件的话
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));//向list中添加一个空的split
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
job执行的流程
入口:
job.waitForCompletion(true)
设置true还是false,不会影响提交,影响的是是否执行 monitorAndPrintJob(); ,是否对执行过程进行监控。
submit()方法才是真正的将job提交集群的操作。
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
/**
* Submit the job to the cluster and return immediately.
* 将任务提交到集群上
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
真正的提交过程是 submitter.submitJobInternal(Job.this, cluster);
任务提交阶段
1、检查输入和输出路径
检查输入路径是否存在,如果不存在那么抛出FileNotFountException
检查输出路径是否存在,如果存在那么抛出FileAlreadyExistException;如果输出路径不存在,那么会创建这个路径
2、计算切片数量,产生切片 (getSplit)
3、如果有需要,可以为分布式缓存设置存根账户信息
4、将这个任务的jar包和配置信息提交到HDFS上存储 【任务执行完之后,jar包自动删除】
5、将job提交给JobTracker,并且选择是否监控这个job的执行状态
任务执行阶段
1、JobTracker在收到Job任务之后,会将这个Job任务拆分成MapTask和ReduceTask(多个线程),其中MapTask的数量由切片数量来决定,ReduceTask的数量由分区数量决定。拆分完成之后,JobTracker等待TaskTracker的心跳
2、JobTracker在收到TaskTracker的心跳之后,会分配任务。注意,在分配任务的时候MapTask要考虑数据本地化,ReduceTask则要分配到相对空闲的节点上。在这个过程中,每一个TaskTracker不一定只领取一个任务,可能会领取多个任务(也就是某个节点领取走多个线程,5个节点领取10000个分片任务)
3、TaskTracker通过心跳领取到任务之后,连接对应的节点将jar包下载过来,解析jar包获取执行逻辑,这一步体现的逻辑移动【啥叫移动计算,啥是计算,这个逻辑就是计算】数据固定的思想
4、TaskTracker解析完jar之后,在本节点(服务器)上开启一个JVM子进程执行MapTask或者ReduceTask。默认情况下,每执行一个MapTask或者ReduceTask就会开启一次JVM子进程,执行完成之后就会关闭这个JVM子进程。也就意味着,如果一个TaskTracker领取到了多个任务,那么就会开启和关闭多次JVM子进程 ,每个任务都是一个线程来处理的。















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









